做数据分析必须学R语言的4个理由
R 是一种灵活的编程语言,专为促进探索性 数据分析 、经典 统计 学测试和高级图形学而设计。R 拥有丰富的、仍在不断扩大的数据包库,处于 统计 学、 数据分析 和数据挖掘发展的前沿。R 已证明自己是不断成长的 大数据 领域的一个有用工具,并且已集成到多个商用包中,比如 IBM SPSS ® 和 InfoSphere®,以及 Mathematica。
本文提供了一位统计学家Catherine Dalzell对 R 的价值的看法。
为什么选择 R?
R可以执行统计。您可以将它视为 SAS Analytics 等分析系统的竞争对手,更不用提 StatSoft STATISTICA 或 Minitab 等更简单的包。政府、企业和制药行业中许多专业统计学家和方法学家都将其全部职业生涯都投入到了 IBM SPSS 或 SAS 中,但却没有编写过一行 R 代码。所以从某种程度上讲,学习和使用 R 的决定事关企业文化和您希望如何工作。我在统计咨询实践中使用了多种工具,但我的大部分工作都是在 R 中完成的。以下这些示例给出了我使用 R 的原因:
R 是一种强大的脚本语言。我最近被要求分析一个范围研究的结果。研究人员检查了 1,600 篇研究论文,并依据多个条件对它们的内容进行编码,事实上,这些条件是大量具有多个选项和分叉的条件。它们的数据(曾经扁平化到一个 Microsoft® Excel ® 电子表格上)包含 8,000 多列,其中大部分都是空的。研究人员希望统计不同类别和标题下的总数。R 是一种强大的脚本语言,能够访问类似 Perl 的正则表达式来处理文本。凌乱的数据需要一种编程语言资源,而且尽管 SAS 和 SPSS 提供了脚本语言来执行下拉菜单意外的任务,但 R 是作为一种编程语言编写的,所以是一种更适合该用途的工具。
R 走在时代的前沿。统计学中的许多新发展最初都是以 R 包的形式出现的,然后才被引入到商业平台中。我最近获得了一项对患者回忆的医疗研究的数据。对于每位患者,我们拥有医生建议的治疗项目数量,以及患者实际记住的项目数量。自然模型是贝塔—二项分布。这从上世纪 50 年代就已知道,但将该模型与感兴趣的变量相关联的估算过程是最近才出现的。像这样的数据通常由广义估计方程式 (general estimating equations, GEE) 处理,但 GEE 方法是渐进的,而且假设抽样范围很广。我想要一种具有贝塔—二项 R 的广义线性模型。一个最新的 R 包估算了这一模型:Ben Bolker 编写的 betabinom。而 SPSS 没有。
集成文档发布。 R 完美地集成了 LaTeX 文档发布系统,这意味着来自 R 的统计输出和图形可嵌入到可供发布的文档中。这不是所有人都用得上,但如果您希望便携异步关于数据分析的书籍,或者只是不希望将结果复制到文字处理文档,最短且最优雅的路径就是通过 R 和 LaTeX。
没有成本。作为一个小型企业的所有者,我很喜欢 R 的免费特定。即使对于更大的企业,知道您能够临时调入某个人并立即让他们坐在工作站旁使用一流的分析软件,也很不错。无需担忧预算。
R 是什么,它有何用途?
作为一种编程语言,R 与许多其他语言都很类似。任何编写过代码的人都会在 R 中找到很多熟悉的东西。R 的特殊性在于它支持的统计哲学。
一种统计学革命:S 和探索性数据分析
140 字符的解释:R 是 S 的一种开源实现,是一种用于数据分析和图形的编程环境。
计算机总是擅长计算 — 在您编写并调试了一个程序来执行您想要的算法后。但在上世纪 60 和 70 年代,计算机并不擅长信息的显示,尤其是图形。这些技术限制在结合统计理论中的趋势,意味着统计实践和统计学家的培训专注于模型构建和假设测试。一个人假定这样一个世界,研究人员在其中设定假设(常常是农业方面的),构建精心设计的实验(在一个农业站),填入模型,然后运行测试。一个基于电子表格、菜单驱动的程序(比如 SPSS 反映了这一方法)。事实上,SPSS 和 SAS Analytics 的第一个版本包含一些子例程,这些子例程可从一个(Fortran 或其他)程序调用来填入和测试一个模型工具箱中的一个模型。
在这个规范化和渗透理论的框架中,John Tukey 放入了探索性数据分析 (EDA) 的概念,这就像一个鹅卵石击中了玻璃屋顶。如今,很难想像没有使用箱线图(box plot) 来检查偏度和异常值就开始分析一个数据集的情形,或者没有针对一个分位点图检查某个线性模型残差的常态的情形。这些想法由 Tukey 提出,现在任何介绍性的统计课程都会介绍它们。但并不总是如此。
与其说 EDA 是一种理论,不如说它是一种方法。该方法离不开以下经验规则:
只要有可能,就应使用图形来识别感兴趣的功能。
分析是递增的。尝试以下这种模型;根据结果来填充另一个模型。
使用图形检查模型假设。标记存在异常值。
使用健全的方法来防止违背分布假设。
Tukey 的方法引发了一个新的图形方法和稳健估计的发展浪潮。它还启发了一个更适合探索性方法的新软件框架的开发。
S 语言是在贝尔实验室由 John Chambers 和同事开发的,被用作一个统计分析平台,尤其是 Tukey 排序。第一个版本(供贝尔实验室内部使用)于 1976 年开发,但直到 1988 年,它才形成了类似其当前形式的版本。在这时,该语言也可供贝尔实验室外部的用户使用。该语言的每个方面都符合数据分析的 “新模型”:
S 是一种在编程环境操作的解释语言。S 语法与 C 的语法很相似,但省去了困难的部分。S 负责执行内存管理和变量声明,举例而言,这样用户就无需编写或调试这些方面了。更低的编程开销使得用户可以在同一个数据集上快速执行大量分析。
从一开始,S 就考虑到了高级图形的创建,您可向任何打开的图形窗口添加功能。您可很容易地突出兴趣点,查询它们的值,使散点图变得更平滑,等等。
面向对象性是 1992 年添加到 S 中的。在一个编程语言中,对象构造数据和函数来满足用户的直觉。人类的思维始终是面向对象的,统计推理尤其如此。统计学家处理频率表、时间序列、矩阵、具有各种数据类型的电子表格、模型,等等。在每种情况下,原始数据都拥有属性和期望值:举例而言,一个时间序列包含观察值和时间点。而且对于每种数据类型,都应得到标准统计数据和平面图。对于时间序列,我可能绘制一个时间序列平面图和一个相关图;对于拟合模型,我可能绘制拟合值和残差。S 支持为所有这些概念创建对象,您可以根据需要创建更多的对象类。对象使得从问题的概念化到其代码的实现变得非常简单。
一种具有态度的语言:S、S-Plus 和假设测试
最初的 S 语言非常重视 Tukey 的 EDA,已达到只能 在 S 中执行 EDA 而不能执行其他任何操作的程度。这是一种具有态度的语言。举例而言,尽管 S 带来了一些有用的内部功能,但它缺乏您希望统计软件拥有的一些最明显的功能。没有函数来执行双抽样测试或任何类型的真实假设测试。但 Tukey 认为,假设测试有时正合适。
1988 年,位于西雅图的 Statistical Science 获得 S 的授权,并将该语言的一个增强版本(称为 S-Plus)移植到 DOS 以及以后的 Windows® 中。实际认识到客户想要什么后,Statistical Science 向 S-Plus 添加了经典统计学功能。添加执行方差分析 (ANOVA)、测试和其他模型的功能。对 S 的面向对象性而言,任何这类拟合模型的结果本身都是一个 S 对象。合适的函数调用都会提供假设测试的拟合值、残差和 p-值。模型对象甚至可以包含分析的中间计算步骤,比如一个设计矩阵的 QR 分解(其中 Q 是对角线,R 是右上角)。
有一个 R 包来完成该任务!还有一个开源社区
大约在与发布 S-Plus 相同的时间,新西兰奥克兰大学的 Ross Ihaka 和 Robert Gentleman 决定尝试编写一个解释器。他们选择了 S 语言作为其模型。该项目逐渐成形并获得了支持。它们将其命名为 R。
R 是 S 的一种实现,包含 S-Plus 开发的更多模型。有时候,发挥作用的是同一些人。R 是 GNU 许可下的一个开源项目。在此基础上,R 不断发展,主要通过添加包。R 包 是一个包含数据集、R 函数、文档和 C 或 Fortran 动态加载项的集合,可以一起安装并从 R 会话访问。R 包向 R 添加新功能,通过这些包,研究人员可在同行之间轻松地共享计算方法。一些包的范围有限,另一些包代表着整个统计学领域,还有一些包含最新的技术发展。事实上,统计学中的许多发展最初都是以 R 包形式出现的,然后才应用到商用软件中。
在撰写本文时,R 下载站点 CRAN 上已有 4,701 个 R 包。其中,单单那一天就添加了 6 个 R 。万事万物都有一个对应的 R 包,至少看起来是这样。
我在使用 R 时会发生什么?
备注:本文不是一部 R 教程。下面的示例仅试图让您了解 R 会话看起来是什么样的。
R 二进制文件可用于 Windows、Mac OS X 和多个 Linux® 发行版。源代码也可供人们自行编译。
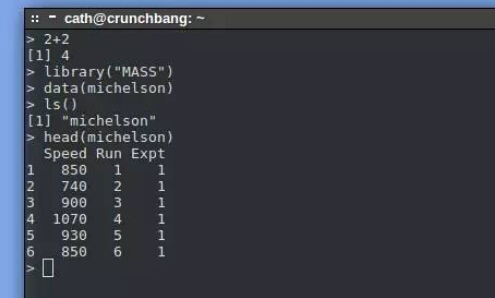
在 Windows® 中,安装程序将 R 添加到开始菜单中。要在 Linux 中启动 R,可打开一个终端窗口并在提示符下键入 R。您应看到类似图 1 的画面。

图 1. R 工作区
在提示符下键入一个命令,R 就会响应。
此时,在真实的环境中,您可能会从一个外部数据文件将数据读入 R 对象中。R 可从各种不同格式的文件读取数据,但对于本示例,我使用的是来自 MASS 包的 michelson 数据。这个包附带了 Venables and Ripley 的标志性文本 Modern Applied Statistics with S-Plus(参见 参考资料)。michelson 包含来自测量光速的流行的 Michelson and Morley 实验的结果。
清单 1 中提供的命令可以加载 MASS 包,获取并查看 michelson 数据。图 2 显示了这些命令和来自 R 的响应。每一行包含一个 R 函数,它的参数放在方括号 ([]) 内。
清单 1. 启动一个 R 会话
2+2 # R can be a calculator. R responds, correctly, with 4.
library(“MASS”) # Loads into memory the functions and data sets from
# package MASS, that accompanies Modern Applied Statistics in S
data(michelson) # Copies the michelson data set into the workspace.
ls() # Lists the contents of the workspace. The michelson data is there.
head(michelson) # Displays the first few lines of this data set.
# Column Speed contains Michelson and Morleys estimates of the
# speed of light, less 299,000, in km/s.
# Michelson and Morley ran five experiments with 20 runs each.
# The data set contains indicator variables for experiment and run.
help(michelson) # Calls a help screen, which describes the data set.
图 2. 会话启动和 R 的响应
现在让我们看看该数据(参见 清单 2)。输出如 图 3 中所示。
清单 2. R 中的一个箱线图
# Basic boxplot
with(michelson, boxplot(Speed ~ Expt))
# I can add colour and labels. I can also save the results to an object.
michelson.bp = with(michelson, boxplot(Speed ~ Expt, xlab=”Experiment”, las=1,
ylab=”Speed of Light – 299,000 m/s”,
main=”Michelson-Morley Experiments”,
col=”slateblue1″))
# The current estimate of the speed of light, on this scale, is 734.5
# Add a horizontal line to highlight this value.
abline(h=734.5, lwd=2,col=”purple”) #Add modern speed of light
Michelson and Morley 似乎有计划地高估了光速。各个实验之间似乎也存在一定的不均匀性。
图 3. 绘制一个箱线图

在对分析感到满意后,我可以将所有命令保存到一个 R 函数中。参见清单 3。
清单 3. R 中的一个简单函数
MyExample = function(){
library(MASS)
data(michelson)
michelson.bw = with(michelson, boxplot(Speed ~ Expt, xlab=”Experiment”, las=1,
ylab=”Speed of Light – 299,000 m/s”, main=”Michelsen-Morley Experiments”,
col=”slateblue1″))
abline(h=734.5, lwd=2,col=”purple”)
}
这个简单示例演示了 R 的多个重要功能:
保存结果—boxplot() 函数返回一些有用的统计数据和一个图表,您可以通过类似 michelson.bp = … 的负值语句将这些结果保存到一个 R 对象中,并在需要时提取它们。任何赋值语句的结果都可在 R 会话的整个过程中获得,并且可以作为进一步分析的主题。boxplot 函数返回一个用于绘制箱线图的统计数据(中位数、四分位等)矩阵、每个箱线图中的项数,以及异常值(在 图 3 中的图表上显示为开口圆)。请参见图 4。
图 4. 来自 boxplot 函数的统计数据

公式语言— R(和 S)有一种紧凑的语言来表达统计模型。参数中的代码 Speed ~ Expt 告诉函数在每个 Expt (实验数字)级别上绘制 Speed 的箱线图。如果希望执行方差分析来测试各次实验中的速度是否存在显著差异,那么可以使用相同的公式:lm(Speed ~ Expt)。公式语言可表达丰富多样的统计模型,包括交叉和嵌套效应,以及固定和随机因素。
用户定义的 R 函数— 这是一种编程语言。
R 已进入 21 世纪
Tukey 的探索性数据分析方法已成为常规课程。我们在教授这种方法,而统计学家也在使用该方法。R 支持这种方法,这解释了它为什么仍然如此流行的原因。面向对象性还帮助 R 保持最新,因为新的数据来源需要新的数据结构来执行分析。InfoSphere® Streams 现在支持对与 John Chambers 所设想的不同的数据执行 R 分析。
R 与 InfoSphere Streams
InfoSphere Streams 是一个计算平台和集成开发环境,用于分析从数千个来源获得的高速数据。这些数据流的内容通常是非结构化或半结构化的。分析的目的是检测数据中不断变化的模式,基于快速变化的事件来指导决策。SPL(用于 InfoSphere Streams 的编程语言)通过一种范例来组织数据,反映了数据的动态性以及对快速分析和响应的需求。
我们已经距离用于经典统计分析的电子表格和常规平面文件很远,但 R 能够应付自如。从 3.1 版开始,SPL 应用程序可将数据传递给 R,从而利用 R 庞大的包库。InfoSphere Streams 对 R 的支持方式是,创建合适的 R 对象来接收 SPL 元组(SPL 中的基本数据结构)中包含的信息。InfoSphere Streams 数据因此可传递给 R 供进一步分析,并将结果传回到 SPL。
R 需要主流硬件吗?
我在一台运行 Crunchbang Linux 的宏碁上网本上运行了这个示例。R 不需要笨重的机器来执行中小规模的分析。20 年来,人们一直认为 R 之所以缓慢是因为它是一种解释性语言,而且它可以分析的数据大小受计算机内存的限制。这是真的,但这通常与现代机器毫无干系,除非应用程序非常大(大数据)。
R 的不足之处
公平地讲,R 也有一些事做不好或完全不会做。不是每个用户都适合使用 R:
R 不是一个 数据仓库 。在 R 中输入数据的最简单方式是,将数据输入到其他地方,然后将它导入到 R 中。人们已经努力地为 R 添加了一个电子表格前端,但它们还没流行起来。电子表格功能的缺乏不仅会影响数据输入,还会让以直观的方式检查 R 中的数据变得很困难,就像在 SPSS 或 Excel 中一样。
R 使普通的任务变得很困难。举例而言,在医疗研究中,您对数据做的第一件事就是计算所有变量的概括统计量,列出无响应的地方和缺少的数据。这在 SPSS 中只需 3 次单击即可完成,但 R 没有内置的函数来计算这些非常明显的信息,并以表格形式显示它。您可以非常轻松地编写一些代码,但有时您只是想指向要计算的信息并单击鼠标。
R 的学习曲线是非平凡的。初学者可打开一个菜单驱动的统计平台并在几分钟内获取结果。不是每个人都希望成为程序员,然后再成为一名分析家,而且或许不是每个人都需要这么做。
R 是开源的。R 社区很大、非常成熟并且很活跃,R 无疑属于比较成功的开源项目。前面已经提到过,R 的实现已有超过 20 年历史,S 语言的存在时间更长。这是一个久经考验的概念和久经考验的产品。但对于任何开源产品,可靠性都离不开透明性。我们信任它的代码,因为我们可自行检查它,而且其他人可以检查它并报告错误。这与自行执行基准测试并验证其软件的企业项目不同。而且对于更少使用的 R 包,您没有理由假设它们会实际生成正确的结果。
结束语
我是否需要学习 R?或许不需要;需要 是一个感情很强烈的词。但 R 是否是一个有价值的数据分析工具呢?当然是的。该语言专为反映统计学家的思考和工作方式而设计。R 巩固了良好的习惯和合理的分析。对我而言,它是适合我的工作的工具。
(责任编辑:king)
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

