Docker Monitor Part1
之一部的几篇文章主要内容来自 这里
这个系列主要分为4个部分
- part1:这个文章主要是讨论由于docker的引进,给集群监控所带来的新的挑战,核心亮点就是引入一套tag+select的机制,类似于k8s。
- part2&3:这个部分主要是讨论适用于docker的监控指标,以及这些指标是怎么获取到的。
- part4:这个部分主要是描述最大的TV和无线电厂商如何对docker提供的基础设施服务进行监控
part1相关内容:
关于docker的详细背景介绍不再赘述,在生产环境中使用docker的优势自不必说,但是有一个 问题 :相比与虚拟机,容器启动和删除都很迅速,相比于虚拟机的量级,容器的监控难度会更大,这篇文章阐述了docker容器在监控环节所遇到的相关问题,并且进行了细致阐述。
尽管monitoring continer很有挑战,因为这样做会使得监控信息的粒度更细,以我们的经验,如果你以某种方式来监控你的容器基础设施,你将会得到更多的信息。
关于isolation
一个容器是一个轻量级的虚拟化的运行时环境(lightweight virtual runtime),它的主要目的是提供软件隔离,通常有三个环境可以用来提供软件隔离:
- 物理机 (highweight)
- 虚拟机 (medium-weight)
- 容器 (lightweight)
随着整体基础设施向容器换进迁移,运维方面的挑战也是巨大的,比较显著的比如网络,以及配置,像k8s以及mesos这样的项目已经在着手解决这方面的问题。
然而,在监控方面所遇到的挑战却很少有人关注。
monitor is crucial
一个有趣的比喻:在生产环境中运行没有监控的服务,就像是开一辆没有前车窗的汽车一样。你并不知道,自己的集群 是否crash掉 ,或者 性能 是怎样的。
对于监控功能的需求显然很容易被理解,传统的监控方案从以下两个维度进行:
-
应用性能监控:对用户代码进行instrument的操作,以此来发现应用的错误或者应用性能的瓶颈。
-
基础设施监控:搜集主机的各种度量指标,比如CPU负载,以及可用的内存。
似乎存在一个GAP:  按照上面的方式进行描述,容器的监控似乎是一个盲区,apm监控以及对于传统的基础设置的监控(采用传统监控工具)都没有对这一层的监控信息进行搜集,对于大规模使用容器的企业来说,这将是一个严重的问题。
按照上面的方式进行描述,容器的监控似乎是一个盲区,apm监控以及对于传统的基础设置的监控(采用传统监控工具)都没有对这一层的监控信息进行搜集,对于大规模使用容器的企业来说,这将是一个严重的问题。
container技术快速回顾
为什么对于传统监控工具而言,容器技术是一个需要考虑的重要问题?让我们来继续深入讨论下容器技术的相关细节。
Original benefit: Security
轻量级的运行时环境,已经存在了很长时间,根据操作系统的不同,container曾经被称作不同的名称:jail(BSD),zone(Solaris),cgroup(Linux)以及其他相关内容,正如jail所表达的那样,容器最初被设计出的目的就是为了安全而考虑的,它们提供了运行时的隔离,同时不需要为全虚拟化而产生额外的开销。
是迷你主机还是进程封装?
容器提供了一种在隔离环境下运行软件的方式,他不是一个进程也不是一个主机,它就像是存在于它们之间的一种连续的状态一样。下面这个表格说明了process,container,以及host之间的区别:
| type | Process | Container | Host |
|---|---|---|---|
| Spec | Source | Dockerfile | Kickstart |
| On disk | TEXT | /var/lib/docker | / |
| In memory | PID | Container ID | Hostname |
| In the network | Socket | veth* | eth* |
| Runtime context | server core | host | data center |
| Isolation | moderate: memory space, etc. | private OS view: own PID space, file system, network interfaces | full: including own page caches and kernel |
Container today
正如之前所描述的,容器以较低的代价来实现了security的价值,但是今天,使用容器有更重要的原因:它们提供了某种扩展的模式,可以用来简化部署流程。
一种扩展的模式
- 使用容器来启动服务,可以很轻易地实现服务的自动伸缩扩展,比如利用k8s这样的针对容器集群进行管理的平台。
- 它们可以帮助开发者摆脱依赖。
在以前的时候,libraries会被直接编译进可执行文件中,这种做法比较简便,但是随着librabies变得越来越大,启动服务的操作会占用太多的内存,因为有太多的依赖要被加载进来。
为了解决这个问题,进程开始在runtime的时候共享libraries,即把这些依赖导入到memory中的操作仅仅执行一次,这就减少了内存的消耗,但是依赖问题也变得难以处理,比如某些必须的依赖在runtime的时候不存在,或者两个进程需要的同一依赖的不同版本,虽然会变得更繁琐,但是因此而减少的内存开销是显而易见的。(其实这段还不是太理解)
如今,随着硬件技术的发展,来自内存的压力要少得多,但是依赖的问题依旧存在,在默认的情况下,我们都是通过shared libraries的方式来build software。
为了减少这种由依赖所引入的麻烦,我们创建了许多包管理工具,比如apm,yum,rvm,virtualenv等等。通过这些工具来很好地来每次安装一组binaries。但是package的更新需要上游方来完成(upstream updates),这可能会减慢开发的速度。
为了加快这种slow-release的问题,人们开始打算自己管理依赖,比如像 omnibus 这样的工具。这似乎又回到了静态链接库的老路上。
容器提供给了工程师新的选择,工程师可以把整个依赖打包进一个轻量级的,隔离的,虚拟化的runtime的mini-host中,这样就可以不受到运行在机器上的其他的软件的影响,而且对于其的版本管理就想在git上管理代码一样简单。
Container challenge: Massive operational complexity
可能认为容器就像是一个mini-host一样,因此对于host的实践都可以迁移到容器上,但是事实并非如此。最近几年来,基础设施层面的变化如下: 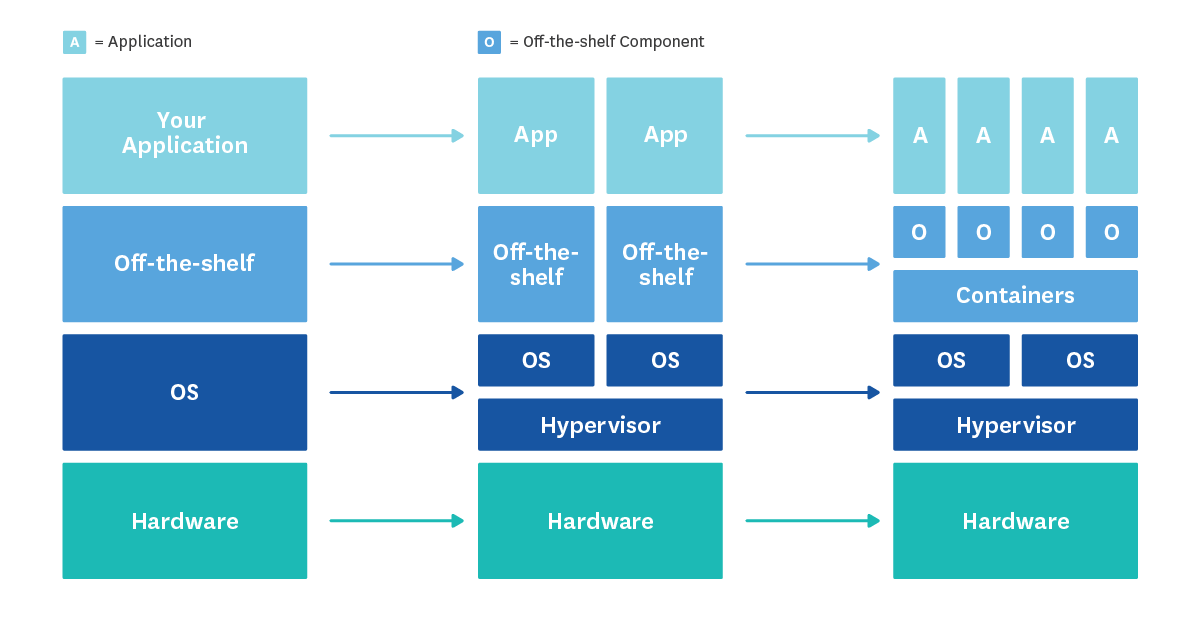 由此带来的metrix explosion:如果按照主机的维度来监控容器,那数据量的增大将会是巨大的。主机的生命周期远远长于容器,平均4倍长。对于宿主机来说,可能需要多天,或者多周地去搜集监控信息,而对于容器来说,仅仅几分钟或者几个小时就够了。
由此带来的metrix explosion:如果按照主机的维度来监控容器,那数据量的增大将会是巨大的。主机的生命周期远远长于容器,平均4倍长。对于宿主机来说,可能需要多天,或者多周地去搜集监控信息,而对于容器来说,仅仅几分钟或者几个小时就够了。
显然,在使用了容器技术之后,需要提供更高级的监控方案。
这种新方案的核心思想就是 不要把所有的东西都看成是host ,按照layers的思路来进行monitor。
没有盲区
为了避免盲区,应该使得整个应用层都得到监控,中间没有gaps。如果你的应用在ec2上构建,你可能会通过CloudWatch来监控VMs,infrastructure monitoring 来监控中间层,applicaiton performance来监控顶层。这样就能帮助你定位代码中出现的问题。
时间轴
为了使得基于layers的监控真正有效,关键是要 同时能够查看 ,跨layers的时候,都发生了什么事情,并且决定,某一个层次中的问题如何对另一个层次产生影响。比如,你看到自己的应用的响应时间比较慢,但是你不能确定这个很慢的响应是否由VM的io所引起的,那么你的监控方法就无法帮你解决问题。
Tags
这个有些类似于k8s中所引入的tag机制一样,说白了就是通过对于tag的query来实现对于制定的group的container的监听。
你可以让你的moitor变得更加“聪明”它们不再来监听所有的容器,可以从另外的一个维度(tag的维度)来选择监听的tag,比如查看位于同一个availability zone之中的容器。
比如可以执行类似下面的query: 监控由image web 所启动的所有的docker 容器 在region abc中 使用的利用率超过平均利用率多少
通过可查询的tag你可以使监控系统变得更加高效和动态,基于容器的架构也会变得更加高效。
结论
因为容器的两个优点:1 可以摆脱包依赖所带来的繁琐配置,2 并且为灵活的扩展提供原材料,它们在生产环境中的使用已经变得相当普遍。
然而,容器的一个典型的使用特性就是短生命周期,并且通常以很大的数目被启动,由于量级的增加,它们常会给运维工作增加许多负担。正是因为这个原因,如今很多使用容器技术的解决方案并没有对容器本身进行监控。这可能会造成系统的脆弱性,甚至导致服务的停工。
因此,我们考虑采用以下的解决方案
- 监控你应用栈的所有layer 这样你就可以看到各个layer到底发生了什么状况,并且可以同时对比这些数据指标,这中间也没有gaps。
- 为你的容器设置tag 这样你就可以通过query来对一组可query的集合对容器进行监控,而不是监控其中的某一个。
Part2 提供了一些Docker可以使用的具体的metrics信息。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

