将参考数据嵌入 IBM ODM 决策服务实现中
简介
运行一个使用 IBM ODM 实现的复杂决策服务,常常需要访问一些企业参考数据来评估和应用业务规则。此数据通常定义为查找表,或者表示两个或多个业务概念之间的关系的键值对集合。让这些表可用于规则引擎,有时可能给应用程序架构、变更管理流程或同时给二者带来挑战。
试用 Business Rules 服务
在业务策略变更时,花更少时间来记录和测试。 来自 Bluemix 的 Business Rules 服务 通过保持业务逻辑与应用程序逻辑分离,最大限度地减少代码更改。免费试用它!
本教程的目的是根据数据大小、变更频率和对数据特征的其他考虑因素,为在运行时将参考数据用于业务规则而提供指南和建议。本教程重点介绍使用部署到 Rule Execution Server 的工件来嵌入参考数据的两种简单方法:规则集和托管执行对象模型 (XOM)。尽管其他方法可能更高效或更容易扩展,但这两种方法对 IBM ODM on Cloud 具有重要意义,该环境中所有可用于规则的数据要么来自在决策服务调用期间提供的输入载荷,要么来自 Rule Execution Server 资源。
上下文数据和参考数据
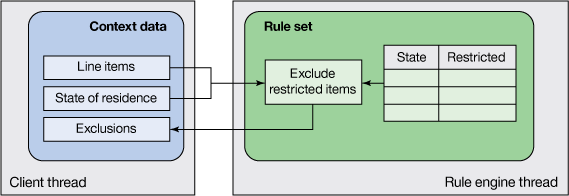
大多数基于业务规则的决策服务实现都基于一个简单的无状态模型,该模型中使用一系列假设规则来处理一组输入数据元素,生成表示预期业务决策的输出数据。需要的输入数据分为以下两个类别:
- 特定于决策服务调用的一个实例的数据。示例包括贷款申请者的特征、您用来为贷款担保的财产、您需要判决的医疗索赔的细节,或者您想要验证的购买订单。对于本教程,该数据称为决策的 事务数据 或 上下文数据 。
- 表示在定义和应用业务策略时使用的参考点的数据。此数据通常表示有关公司如何经营其业务的外部法规或合规性规则或内部特征。例如,它可能表示每个州的法律允许的最大利率,或者有效的医疗程序代码的列表,或者无法运送到一个邮政编号所在地的商品类型。在本教程的剩余部分中,这种类型的数据称为决策的 参考数据 。
从总体上讲,业务规则的一个关键功能是将从 上下文数据 发出(直接或通过业务规则计算得出)的值与从 参考数据 选择的值相匹配,最终生成想要的决策。
考虑来自一个购买订单验证决策服务的规则的例子,该规则拥有排除任何限制运送到购买者居住州的商品的作用。这样一条规则可在 IBM ODM 中表达,如清单 1 所示:
清单 1. 使用参考数据的受限商品操作排除规则的示例
definitions set item to an item in the line items of 'the PO'; if item is restricted in the state of residence of 'the buyer' then add item to the exclusions of 'the PO' with reason "cannot ship item to the buyer's state";
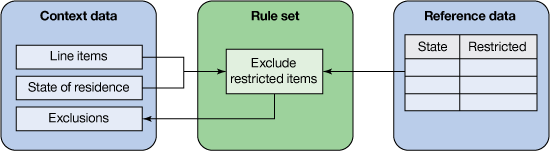
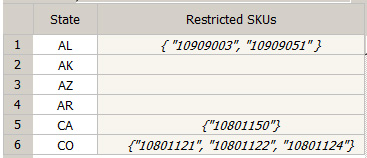
支持运行此规则所需的参考数据表可定义特定的州中限制的商品列表。例如,该表可能类似于图 1:
图 1. 受限商品参考数据表

清单 1 中显示的业务规则同时使用了上下文和参考数据元素。它通过将上下文数据与参考数据相匹配来实现部分业务规则。考虑这个示例中的以下细节:
- 订购的商品和排除的购买订单包含在上下文数据中。
- 购买者居住的州也包含在上下文数据中。
- 该州限制的商品列表包含在参考数据中。
图 2 演示了示例中涉及的不同类型的元素。
图 2. 支持规则集执行的上下文和参考数据
数据特征
上下文和参考数据通常拥有不同的特征。上下文数据表示来自一个业务领域的实体的详细信息。因此,它通常建模为一种大型且复杂的对象分层结构,其中包含多个级别和多值属性。决策越复杂,对象分层结构就越大和越详细,才能反映可能与业务决策相关的上下文的许多可能方面。
相对来讲,参考数据通常是一个简单的映射表(可能包含多列)。它没有上下文数据的结构复杂性。但是,这些表常常非常大,包含数百或数千个条目。对于参考数据,更复杂的决策会转换为更细粒度的表(例如,包含更多行,包含城市或邮政编码级别而不是州级别的条件)。或者,更复杂的决策包含更多表来支持规则中更详细和更多样性的决策条件。
考虑以下其他的明显区别:
- 上下文数据范围是整个决策,参考数据范围通常限制到决策内少量的具体规则或规则任务。
- 在大多数情况下,来自上下文数据的所有数据点用于计算决策,而来自参考数据集的数据可能只有少量适用。
- 对于不同的决策服务调用,上下文数据也不同,而参考数据很少更改(频率通常低于规则本身更改的频率)。
在映射表中,参考数据描述与上下文数据的某种关系。但是,它没有对应如何使用该关系提供任何规定。在大多数情况下,该数据会与规则集中左侧的规则(条件部分)自然地匹配。
挑战在于找到将参考数据合并到规则集中的最佳方式,使它可在运行时适用于手头的决策,也可能适用于同一个应用程序中包含的其他决策。下一节介绍您应考虑的一些帮助选择正确方法的因素。
本教程中的代码示例是使用 IBM ODM V 8.7.1 开发的。
回页首
选择一种方法
最终选择用来向决策服务提供参考数据的方法依赖于多种因素,这些因素源自您的解决方案的功能和非功能需求。请仔细衡量这些因素,因为没有适合所有情形的方法。
本地或远程调用
一般而言,使用决策服务的本地调用(例如使用从 IlrJ2SESessionFactory 或 IlrPOJOSessionFactory 获得的规则会话)是一种默认、首选的解决方案,因为它提供了访问参考数据的最高灵活性。不需要考虑在调用的应用程序与决策服务之间交换大量数据所涉及的网络延迟。访问数据库或其他数据服务的安全考虑因素可以简化。
相对而言,在使用远程调用时,例如一个自定义的 Web 服务托管的透明决策服务 (HTDS) 或受监视的透明决策服务 (MTDS),需要仔细衡量通过网络交换的数据量。您可能会发现很难提供一个可能部署在云中,具有数据来源的必要访问权的远程 Rule Execution Server。例如,对于 IBM ODM on Cloud,出于安全原因,不允许访问外部服务或数据来源。
顺便说一下,如果请求载荷对远程调用而言很大,请记住以下技巧。如果使用一个从 IlrEJB3SessionFactory 获得的规则会话,Enterprise JavaBean (EJB) 可能是比 Web 服务更高效的选择。如果使用异构语言或环境,可考虑在解决方案中使用消息驱动的规则 bean。
共享
相同的参考数据可由不同的应用程序以不同的方式使用,可拥有许多类型的不同使用者。数据是否由规则独享,常常决定着它如何合并到规则集中。对于多个使用者的情形,数据始终必须可供所有使用者使用并对所有使用者保持同步。
治理
预期的变更频率、所有权、软件开发生命周期和其他治理考虑因素会对应在何处维护参考数据产生巨大影响。决策治理流程需要包含必要的步骤,以确保部署的每个新规则集都在使用参考数据的恰当版本。在参考数据源不通过 IBM ODM 管理时,此需求特别重要。无论它的性质如何,每个存储库都必须加以托管、得到管理、予以版本控制且受到保护。
数据量
需要管理的参考数据的量可能影响规则集大小、性能和业务用户在 Decision Center 中创建规则的体验。大量的参考数据通常会阻碍将数据嵌入到规则中。
测试
参考数据必须可用于测试。很容易理解如果使用 Decision Center Business Console 执行测试,参考数据存储必须可从 Decision Center 访问。类似地,参考数据必须可供在 Rule Designer 中测试的规则开发人员访问。离线测试要求本地环境中提供数据来源。
回页首
扩充请求载荷
讨论将参考数据嵌入到可部署的 Rule Execution Server 工件中的解决方案的细节之前,需要考虑一种在 Rule Execution Server 上调用规则之前使参考数据可用于这些规则的通用战略。可通过扩充请求载荷来提供该数据。可过滤和扩充上下文数据,或者提供可在规则中使用的参考数据表的一组句柄。
一般而言,参考数据来自数据库表,而且它由一些框架缓存,比如来自 Apache Commons 的 Java Caching System ( commons.apache.org/proper/commons-jcs ) 和 Ehcache,这是一种开源、基于标准的缓存 ( www.ehcache.org )。
如图 3 中所示,在规则集运行后收集可用的信息是决策服务客户端线程的责任。图 3 中的客户端线程通常是一个自定义 Web 服务的一部分,该服务在面向服务的架构中向客户端公开决策服务并在扩充步骤后封装对 IBM ODM 服务的调用。
图 3. 通过请求扩充来提供参考数据
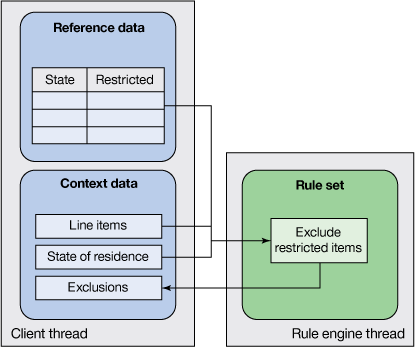
因为扩充直接影响到载荷的大小,所以此战略对决策服务调用是本地的还是远程的很敏感。另外,由于在调用决策服务之前为该服务收集了需要的完整参考数据集,所以可能检索比实际需要的更多的数据,从而影响性能。最后,避免在过滤数据来执行扩充时包含业务知识。有关此方法的更多细节,请参阅 在规则应用程序中访问外部数据 。
回页首
在 XOM 中捕获参考数据
在许多情形下,首选的方法是在规则集执行期间收集参考数据。类似于上一节中介绍的请求载荷扩充情形,数据本身在规则外维护并在规则运行时拉入。但是,规则引擎线程会检索该数据。组件的组织结构类似于图 4:
图 4. 在 XOM 中捕获参考数据
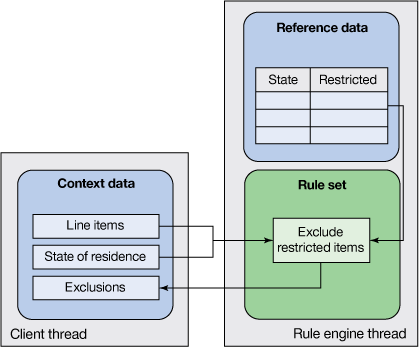
可将参考数据存储在外部数据来源(例如数据库)中或作为文件存储在 XOM 中。有关数据库方法的详细信息,请参阅 在规则应用程序中访问外部数据 。
备用方法(包括在 XOM 中捕获参考数据)在本质上依赖于文件资源与托管的 XOM 的捆绑。该文件在执行时读取并评估。用于评估内容的方法取决于数据的性质。数据可在 XOM 层内评估,对业务用户完全透明,也可以转换为业务对象模型 (BOM) 中的对象,然后可用在规则创建任务中。下面的实现示例演示了如何读取文件和将结果用在下游的规则中。
实现示例
在 XOM 中捕获参考数据在本质上依赖于捆绑一个文件,将其作为 IBM ODM Rule Execution Server 发布和托管的 XOM 归档文件中的一个资源。该资源文件由一个数据提供程序 Java 类在运行时加载和处理。该类是 BOM 的一部分,所以它可用于编写规则。
下面的示例演示了一个数据提供程序类的示例实现和如何将它用在下游的规则中。来自图 1 的参考数据可存储在一个平面文件中,该文件中的每一行表示一个州的限制。该行的第一个标记表示州,剩余内容是库存单元 (SKU) 的逗号分隔列表。该行的内容类似于清单 2 中的示例。
清单 2. 平面文件中的示例参考数据
AL 10909003,10909051 AZ AR 10801150 CA 10801121,10801122,10801124 CO …
清单 3 中的 ReferenceDataProvider 类读取该文件并将内容转换为合适的限制对象。它遵循单体模式设计,这会将一个类的实例化限制到一个对象,而且它包含一个调用私有构造函数的公共同步 getInstance 方法。
在第一次调用中,该构造函数解析数据集,并将解析的数据集存储在一个 ShippingStateRestriction 对象哈希图中,该哈希图按相应的州建立索引。
清单 3. ReferenceDataProvider 类定义
public classReferenceDataProvider { private staticReferenceDataProvider instance= null; privateMap<StateType, ShippingStateRestriction> restrictions = null; private static finalString LINE_SPLIT_BY= " "; private static finalString SKUS_SPLIT_BY= ","; privateReferenceDataProvider() throwsIOException { if(restrictions == null) { parseDataSet(); } } public static synchronizedReferenceDataProvider getInstance() throwsFileNotFoundException, IOException { if(instance== null) { instance= newReferenceDataProvider(); } returninstance; } publicShippingStateRestriction getRestriction(StateType state) { returnrestrictions.get(state); } private voidparseDataSet() throwsIOException { String dataFilename = "SKURestrictionsByState.csv"; InputStream inputStream = getClass().getClassLoader().getResourceAsStream(dataFilename); BufferedReader br = newBufferedReader(newInputStreamReader(inputStream)); restrictions = newHashMap<StateType, ShippingStateRestriction>(); String line; while((line = br.readLine()) != null) { String[] entry = line.split(LINE_SPLIT_BY); StateType state = StateType.valueOf(entry[0]); List<String> skus = Arrays.asList(entry[1].split(SKUS_SPLIT_BY)); ShippingStateRestriction stateRestriction = newShippingStateRestriction(); stateRestriction.setState(state); stateRestriction.setSkus(skus); restrictions.put(state, stateRestriction); } br.close(); } } 在这个简单的例子中,该文件的全部内容都加载到该图中,将数据过滤工作推送到 BOM 或规则。如果内容庞大,可以对要加载和保留在内存中的内容采取一种更加区别性的方法。
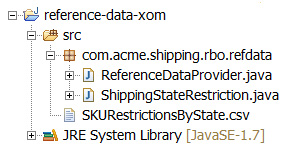
参考数据文件本身包含在 XOM 项目中,可在 Java 类路径中找到它。图 5 显示了一个包含 SKURestrictionsByState.csv 资源文件和 ReferenceDataProvider 类的示例项目结构。
图 5. 示例 XOM 项目组织
在 BOM 中,可以使用各种模式来向规则公开相关的实体。对于清单 1 中的示例规则,可以为 Item 类使用一个动词化的虚拟 BOM 方法来评估该商品是否受到限制。图 6 演示了此方法的定义。
图 6. 访问参考数据的 BOM 方法定义示例

清单 4 中的 BOM-to-XOM 代码段显示了使用 ReferenceDataProvider 类的方法主体。它从哈希图获取适当的州限制并酌情返回 true 或 false 。
清单 4. 访问参考数据的 BOM-to-XOM 代码
ReferenceDataProvider provider = ReferenceDataProvider.getInstance(); ShippingStateRestriction restriction = provider.getRestriction(state); return(restriction.getSkus().contains(this.getSku()));
捕获参考数据的托管 XOM 应与支持上下文数据的核心 XOM 类集独立。然后,参考数据 XOM 归档文件可与其他托管 XOM 资源独立地部署。图 7 显示了购买订单验证决策服务的部署,该服务使用了两个不同的资源: acme-shipping-xom.zip (包含核心 XOM 类集)和 reference-data-xom.zip (封装需要的参考数据)。
图 7. Rule Execution Server 中的托管 XOM 示例
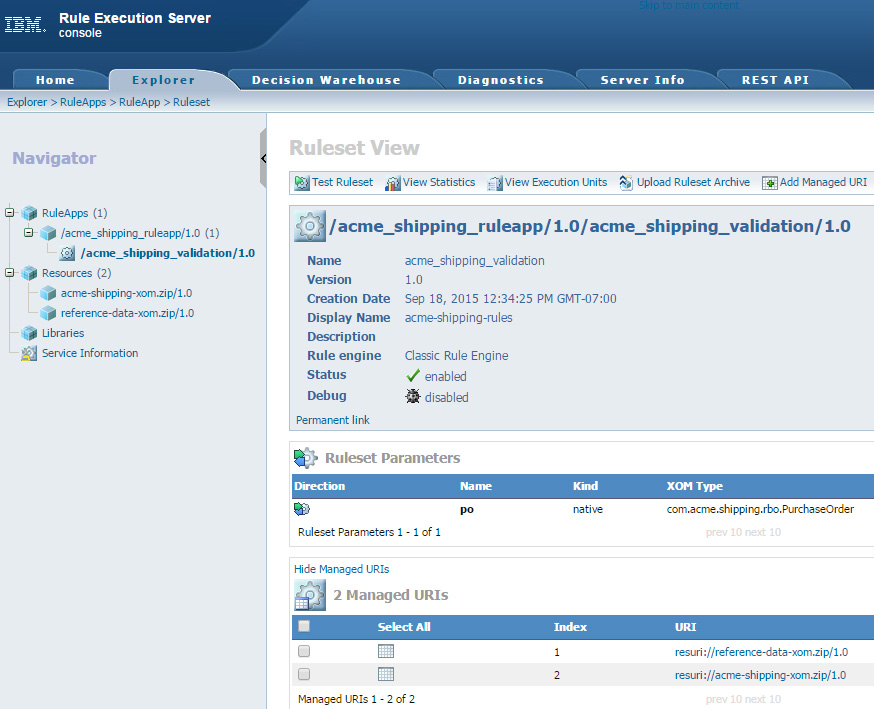
点击查看大图
关闭 [x]
图 7. Rule Execution Server 中的托管 XOM 示例
设计考虑因素
检查以下考虑因素,以决定是否采用文件资源解决方案作为参考数据的存储库:
- 更改的影响 : 更改参考数据涉及到更改可部署的 Java 工件。它不会影响服务实现,后者不需要再部署。更新始终局限于 Rule Execution Server 组件所管理的工件。
- 参考数据过滤逻辑 : 参考数据过滤规则需要更改或很复杂时,将数据加载到规则集中与在决策服务中硬编码数据过滤相比具有一定的优势。它允许规则演变而不重新部署服务实现,而且它不会将业务逻辑放在服务层代码中。但是,过滤规则的巨大复杂性使得可能需要将它们放入一个单独的规则集中。
- 更改频率 : 更改参考数据的频率应很低,可能一年几次。因为更改参考数据需要重新部署 XOM,这通常需要一些批准程序和代码更改,所以不要对高度动态的数据集使用此方法。另外,治理流程应为如何实现参考数据的更改提供具体的指引。
- 参考数据大小 : 参考数据的典型大小为数 MB。所有或部分参考数据通常在运行时加载,而不会耗尽 Java 虚拟机 (JVM) 堆内存。Excel 电子表格或纯文本文件通常有助于轻松地操作大量数据。
- 资源可用性 : 有时,为参考数据实现和管理一个数据库的硬件资源和人力资源稀缺,很难保护或不可用。在这些类型的环境中或在业务用户无法承担额外的治理开销时,基于文件的方法为业务用户提供了一种快捷方式来维护与它们相关的数据,将更改保留在规则范围内。
- 数据可用性 : 如果数据部署在 XOM 中,则没有对远程数据来源的依赖性。此方法克服了规则集中的远程数据访问的一些不足(比如异常管理)。如果参考数据的大小不利于在 Decision Center 中实现为规则,这种方法可以作为替代方案。
回页首
在规则中捕获参考数据
初看起来,IBM ODM 中的决策表类似于参考数据表。所以您可能会想是否可以仅利用规则来捕获其参考数据,通过规则集来部署该数据。出于以下原因,您可以选择此方法:
- 保留一个单一存储库 (Decision Center) 来存储和管理所有与业务策略的实现相关联的工件:业务用户只需学习一个用户界面即可管理他们的业务决策,可以通过一个接口执行他们的所有更新。
- 包含和管理单个运行时工件 (RuleApp) 来部署和运行业务策略:此方法简化了架构和变更管理。
- 避免规则和参考数据之间的任何同步问题:因为参考数据是使用规则集部署的,所以对业务规则的定义而言不存在参考数据更新太早或太迟的风险。
如果使用本教程中的排除受限商品的规则示例,则组件组织结构类似于图 8。
图 8. 在规则集中捕获参考数据
实现示例
因为规则集(也可能是多个规则集)中的多个规则任务可能需要参考数据,所以决策表的实现不应受一个特定的 BOM 类束缚。可以将它与通用规则集变量相关联来让它可重用。我们来看图 9 中的示例中的以下可能的实现:
图 9. 支持参考数据决策表的变量
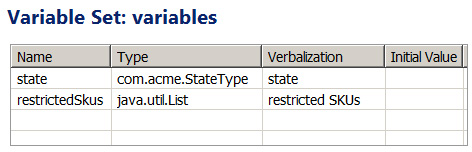
为了支持图 1 中的决策表示例的定义,这个实现示例使用了两个规则集变量 state 和 restricted SKUs ,后者是 SKU 字符串值的一个集合。
使用这些变量,您可以构建图 10 中的决策表来表示参考数据:
图 10. 实现参考数据的决策表
然后可以将该表封装到一个可根据需要重用的简单子流中。为了正确地触发该表,在运行该子流之前,必须使用目标州来初始化 state 变量。在该例中,通过以下语句,使用购买者的居住州的值来初始化 state 变量:
set state tothe state of residence of 'the buyer';
参考数据表运行后,您可以利用结果来收集排除的商品。清单 1 中最初给出的规则然后类似于清单 5 中的示例:
清单 5. 在规则中捕获参考数据的实现示例
definitions set item to an item in the line items of 'the PO';
if the SKU of itemis one of 'restricted SKUs'
then add itemto the exclusions of 'the PO'; with reason "cannot ship item to the buyer's state";
设计考虑因素
在考虑在规则中捕获参考数据时,仔细权衡以下方面:
- 参考数据的更改频率应合理。理想情况下,该频率应与其他业务规则的频率相当或更低。尽管部署一项规则更改是一个比应用程序代码更改轻量得多的流程,但它仍比更新数据库的内容更复杂。
- 参考数据的大小应合理。尽管 IBM ODM 可轻松地容纳涉及数万个规则的规则集(使用 IBM ODM V8.5.1 中的 Decision Engine 会更加高效),但您不会希望规则集大小和执行时间受到参考数据的左右。
- 表示为参考数据的信息不应直接和唯一地与来自输入上下文数据的元素相关联。例如,一个收集涉嫌存在欺诈的账号的黑名单不是决策表的良好候选者。因为它直接依赖于上下文数据(客户账号),所以该列表很可能不利于前面提到的两个方面:它的更改频率比业务策略更高,而且它的大小最终会增长到非常大。
- 规则的所有者也应拥有该参考数据。否则,参考数据所有者必须参与 IBM ODM 决策治理流程,还要了解如何创建和维护规则,或者规则所有者必须主动收集和更新参考数据表。
- 理想情况下,规则所捕获的参考数据仅应在使用它们的规则集的范围内相关。具体来讲,参考数据不应从另一个存储库(比如外部数据库或文档)复制,这可能导致数据不一致,除非规则是从外部来源自动生成的。
- 相反地,一定要认识到规则所捕获的参考数据不容易由其他系统或应用程序查询,因为它来自一个数据库。尽管 Decision Center API 允许检索和访问规则和决策表实体的定义,但它需要相对复杂的自定义代码,而且导致报告活动以外的任何活动的性能无法接受。
除了通过 Decision Center 对参考数据规则进行直观地管理,以下两节还提出了对大型数据或自动从数据来源拉入的数据很有用的替代方案。
Rule Solutions for Office
IBM ODM 的 Rule Solutions for Office 组件提供了 Microsoft Office 插件,以支持在 Microsoft Office 文档中创建和编辑业务规则。从 Decision Center 中,业务用户可通过一个规则项目向名为 RuleDocs 的 Microsoft Office 文档发布规则,通过 Microsoft Word 和 Microsoft Excel 离线处理这些文档,以及在以后通过将 RuleDocs 导入回 IBM ODM 中来更新 Decision Center 项目。对于已使用 Rule Solutions for Office 来管理规则的项目,也可以使用它来管理参考数据决策表。
考虑 Rule Solutions for Office 的以下优势:
- 参考数据由一个未直接参与决策服务的维护的部门拥有时,RuleDocs 提供了一种简单方式来让这个外部部门调整数据,而无需花时间学习如何使用 Decision Center 用户界面和它的关联治理流程。
- 经证明,在 Excel 电子表格中管理大型决策表是一种比使用 Decision Center 更高效的用户体验。您和您的团队可能会发现,在滚动和调整列和行方面,使用 Excel 导航大型表比 Decision Center 更容易。如果处理大型表,Rule Solutions for Office 提供了一种更容易的方式来一次性查看表中的所有数据,但它不一定比在 Decision Center 中完成同样的操作更快。
请考虑 Rule Solutions for Office 的以下限制:
- 面向 IBM ODM V 8.7 和更早版本的 Rule Solutions for Office 为 Microsoft Excel 和 Word Versions 2007 和 2010 提供了官方支持。Microsoft Office 2013 不受官方支持。
- Rule Solutions for Office 不受 IBM ODM on Cloud 支持。
自动化的规则生成
无需手动创建和管理,表示参考数据的规则可在提取规则集之前从一个数据来源自动生成。自动化的规则生成流程可使用 Decision Center API,如 示例:决策表的数据来源 中所示。规则生成可按需执行或作为规则集提取脚本的第一步而即时执行。
在大多数时候,您会发现用于生成规则的数据来自一个数据库。但是,在应用程序需要所有数据文件时,可以将这些文件存储为规则项目中的资源。此方法可以保证参考数据文件始终与规则同步,并在 Decision Center 存储库中得到适当的版本控制。
清单 6 展示了,在给定文件基础名称和扩展名,并且假设 Decision Center 会话参数已正确连接到预定的规则项目时,如何从 Decision Center 存储库中的一个规则项目检索一个资源元素。
清单 6. 从规则项目获取资源元素
IlrResource getTableResource(IlrSession session, String basename, String extension) throwsIlrRoleRestrictedPermissionException, IlrObjectNotFoundException { EClass eclass = session.getBrmPackage().getResource(); IlrSearchCriteria criteria = newIlrDefaultSearchCriteria(eclass); for(IlrElementDetails element : session.findElementDetails(criteria)) { IlrResource resource = (IlrResource) element; if(resource.getName().equals(basename) && resource.getExtension().equals(extension)) { returnresource; } } return null; } 清单 6 中示例中的方法返回的资源对象的 getBody 方法允许检索该文件的内容(参见 IlrResource 类文档)。有了参考数据文件的内容,您就可使用 Decision Center API 来创建和填充决策表。
性能影响
不出所料,捕获参考数据作为规则,会同时影响规则管理和规则执行时间。
创建和维护
非常大的决策表(例如几千行)需要花大量时间来加载到 Rule Designer 或 Decision Center 中。例如,打开一个包含 10,000 行的决策表来在示例应用服务器上的 Decision Center 中编辑可能会花 5 到 10 分钟,这还不包括对工件的交互式编辑。打开较大的表也可能导致 Rule Designer、Decision Center 或 Rule Solutions for Office 中的内存不足异常。
一条已发布的决策表创建和管理最佳实践是将它们保持在 500 行以下(参见 “参考资料” 部分中的 “决策表中的行数限制”)。对于行数是推荐的 500 行限制的多倍的表,一个简单的解决办法是,可以将原始表分解为更小、更容易管理的数据块。
执行
一般而言,如果使用 Decision Engine,决策表的性能会随着表中的行数的增加而良好地扩展。探究以下测试的结果:使用一种结构与图 11 中所示结构类似的决策表(基本来讲有一个条件列和一个操作列),使用不同的行数,并且在整个表中查找大量不同的值。
在本教程中用作参考的执行时间基于一个包含 10 行的示例表。图 11 显示了其他表的执行时间(分别包含 100、1000 和 10000 行),采用与 10 行的执行时间的相对形式表示。
图 11. 不同大小的参考表的执行时间比较
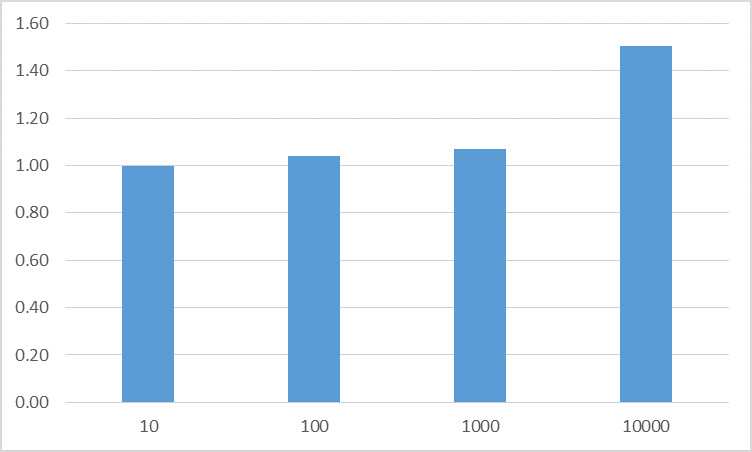
该图显示,在包含 10、100 或 1000 行的表中查找一个值没有显著差异。在 10,000 行的表中查找一个值的时间仅是包含 10 行的表中的 1.5 倍。
作为执行性能的最后一个参考点,可考虑使用一个 Java 哈希表来实现参考数据表比使用决策表快约 400 倍。
回页首
混合方法
除了将参考数据作为 Rule Execution Server 可部署工件来管理,一种备用方案是混合使用前几节中的两种选择。这包括使用规则存储库来以决策表的形式创建和管理参考数据,然后基于这些表生成参考数据 XOM 资源来在需要更新时重新部署它。此方法基于以下步骤:
- 根据 “在规则中捕获参考数据” 中的描述,在决策表中捕获和维护参考数据。
- 使用一个从规则集归档文件中过滤掉参考数据表的规则集提取器来生成规则集。
- 基于决策表的内容而生成参考数据 XOM 资源归档文件,并使用 Decision Center API 检索来源表。然后,可使用 Decision Table API 解析和处理它们(参见
IlrDTModel和关联的类)。
考虑混合方法的优势:
- 捕获并管理参考数据,在规则存储库中创建版本。您不需要为参考数据提供外部管理系统,这简化了整体决策治理流程。
- 在运行时,参考数据通过 XOM 访问,这比通过执行决策表来访问更高效。这样可以更干净地集成到 BOM 中。
但是,混合方法需要投入时间为 Decision Center API 编写一些重要的自定义代码,以将决策表转换为 XOM 归档文件并自动化 XOM 归档文件向 Rule Execution Server 的部署。
另外,IBM ODM on Cloud 不允许部署自定义的 Decision Center 企业归档 (EAR) 文件,而且 IBM ODM on Cloud Decision Center 不允许通过 IlrSession API 打开远程连接。因此,此选项无法应用于 IBM ODM on Cloud。
回页首
在规则中利用参考数据
选择一种为决策存储参考数据的方法后,考虑如何进行设计来将参考数据合并到规则集中。
第一个选择包括在一定程度上过滤参考数据并使用结果集扩充上下文数据。例如,过滤和扩充可以是您添加到上下文数据中的一个或多个属性或标志,用于表示从参考数据得到的上下文数据的更多特征。在本教程中的示例中,想象每个商品实例都使用对它加以限制的州列表来扩充。基本来讲,上下文 BOM 对象通过转换从参考数据得到填充。对于这种方法,您必须注意避免在转换中暗含业务逻辑。
作为一种变体,另一种选择是创建更多业务对象,并将它们添加到模型中来表示参考数据。这些对象可从参考数据填充并注入到规则执行上下文中。
无论选择何种设计,都将对参考数据的访问推迟到决策中需要它时。业务决策在其逻辑中通常有许多路径,而且不是所有路径都需要访问所有参考数据元素。可以考虑即时访问参考数据并在检索该数据后适当地缓存它。
回页首
结束语
本教程介绍了在 Rule Execution Server 无法访问外部数据来源时,使用资源文件来管理参考数据的两种方法。第一种方法依靠规则项目资源来生成参考数据,作为规则集中的决策表。第二种方法使用通过 XOM 资源部署的文件来初始化一种 Java 对象单体模式。
您可应用所学的示例和方法来处理决策服务。
致谢
感谢 Franck Delporte 和 Peter Holtzman 对本教程的评审和建议。
正文到此结束
- 本文标签: apr 生命 需求 apache list provider 数据 Enterprise 解析 测试 REST 贷款 http 代码 zip value ip 开源 UI Office App ssl 软件 线程 src API java Excel 自动化 final map Word CTO 服务器 插件 数据库 企业 管理 rmi 实例 IBM 开发 安全 Microsoft Office 2013 时间 web 组织 find 同步 IDE 免费 云 parse tab 参数
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

