使用 Couchdb-python 操作 CouchDB
简介
Couchdb-python 是目前最常用的操作 CouchDB 的第三方 Python 库,其提供了几乎所有 CouchDB RESTful 接口的功能,主要包括三个模块:
- Client 模块:提供与 CouchDB server 的交互,对数据库的基本操作如增删改查,操作 temporary view 等功能包括在该模块中
- View 模块:为用户提供操作 CouchDB 中预定义视图的接口
- Mapping 模块:将 Python 对象与 CouchDB 的 JSON 文档映射在一起,在进行面向对象编程时十分有用
本文将重点介绍前两个模块中的重要方法的使用。
Couchdb-python 下载地址 。
安装方法同普通的第三方 Python 库,安装后只需使用 import couchdb 语句即可导入全部 couchdb-python 中的所有模块。
回页首
Client.server 中提供的方法
该模块提供了一系列获取 CouchDB server 信息的方法,通过这些方法用户可以获取关于 server 的各种状态信息。但在使用这些方法之前,首先要获取 server 实体,方法如下:
server = couchdb.Server('http://yourhost:5984/') CouchDB 默认使用 5984 端口,我们可根据实际情况填入不同参数,如需获取 admin 账户权限,可使用带有用户名密码的 host 地址:
server=couchdb.Server('http://couchdb:passw0rd@10.120.138.211:5984/') 通过以上两种方法获取到 server 实体后,即可使用其他方法获得 server 相关信息。
表格 1 中描述了 server 中提供的常用方法:
表 1.server 中提供的方法
| 方法名 | 用途 | 参数 | 样例 |
|---|---|---|---|
| create(name) | 创建一个名为 name 的数据库 | name-数据库名 | db = server.create(‘test’) |
| server[name] | 获取名为 name 的现存数据库 | name-数据库名 | db= server[‘test] |
| delete(name) | 删除名为 name 的数据库 | name-数据库名 | server.delete(‘test’) |
| version() | 获取 CouchDB server 版本号 | None | myversion=server.version() |
| tasks() | 获取正在运行的任务状态,如数据压缩、数据库复制等 | None | taskJson=server.tasks() |
| stats(name) | 返回 server 的相关统计数据 | Name-统计数据名, 主要有 couchdb 和 httpd 两种 None 将返回所有 Couchdb 下的统计参数有 7 种: auth_cache_hits auth_cache_misses database_reads database_writes open_databases open_os_files request_time httpd 下的统计参数有 5 种: bulk_requests clients_requesting_changes requests temporary_view_reads view_reads | statsJson=server.stats('couchdb/open_os_files') statsJson=server.stats('httpd/ view_reads') |
| Replicate(source,target) | 从源数据库复制数据到目标数据库,源数据库和目的数据必须已经存在 | Source-源数据库地址 Target-目的数据库地址 | server.replicate("http://localhost:5984/testdb", "http://coucdb-remote:5984/recipes") |
通过表格中所列的 db=server[name] 或 db=create(name)获取数据库实体 db 后,即可使用其他方法对数据库中的各种数据进行操作, 这里我们创建一个名为”test”的数据库。
回页首
使用 update(documents) 批量插入和更新数据
尽管我们可以通过创建一个 dict 类型的数据并使用 db.save(dict) 方法将一条记录插入数据库,但实际的项目中使用 update(documents) 方法可以更加高效地插入、更新一条或多条数据,因为 update(documents) 方法将多条记录的数据包裹在一个 request 请求中一次性地发送给 CouchDB server。
update(documents) 的参数及返回值说明如下:
参数:documents--包含一组 dict 对象的数组,dict 对象即为要插入或更新的数据。
返回值:三元组列表 (success, docid, rev_or_exc)--列表元素依次对应 documents 中的元素,success 为布尔型,表示是否更新成功,docid 表示对应的文档“_id”,rev_or_exc 表示新纪录的版本号“_rev”或更新失败的异常信息。
这里需要明确一个概念,CouchDB 中“_id”字段用来唯一地标识一条记录,“_rev”字段用来表示一条记录的更新版本号。任何的数据修改操作(除了 delete)都将在原数据的基础上 append 一条新数据,并递增原数据的“_rev”字段。也就是说,CouchDB 中不存在数据覆盖,旧数据仍然保存在数据库中,并可通过之前的“_rev”值找到,这也是 CouchDB 本身的一个特性。如图 1 所示:
图 1. 未经任何修改的一条新记录
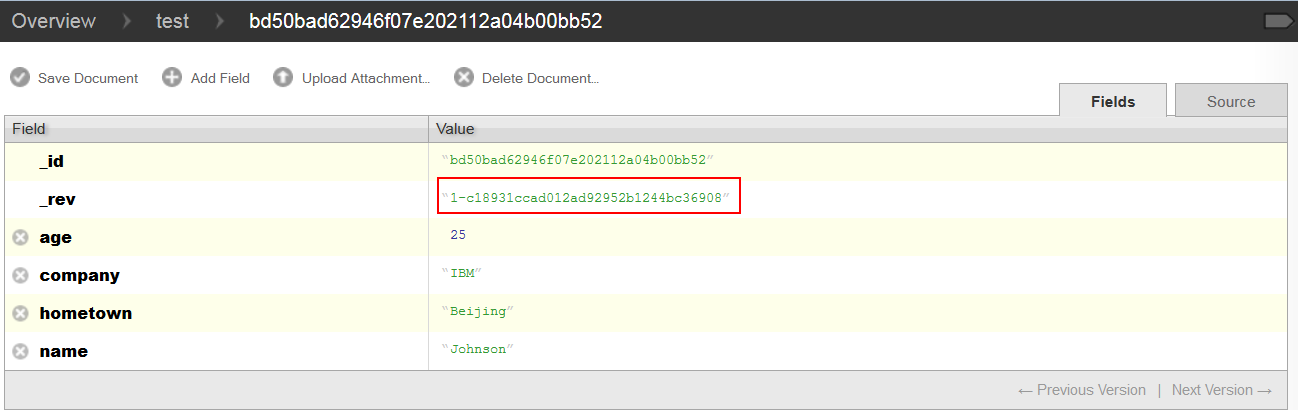
我们在 test 数据库中建立了一条记录,除“_id”和”_rev”外,此记录还有 age,company,hometown 和 name 字段。此时该记录未经任何修改,其“_rev”字段的首位为 1。将其 hometwon 字段修改后, 此时“_rev”字段的首位递增为 2,但之前“_rev”字段首位为 1 的记录仍可通过点击 futon 中记录左下角的“previous version”按钮找到,如图 2 所示:
图 2. 记录更新后“_rev”字段递增
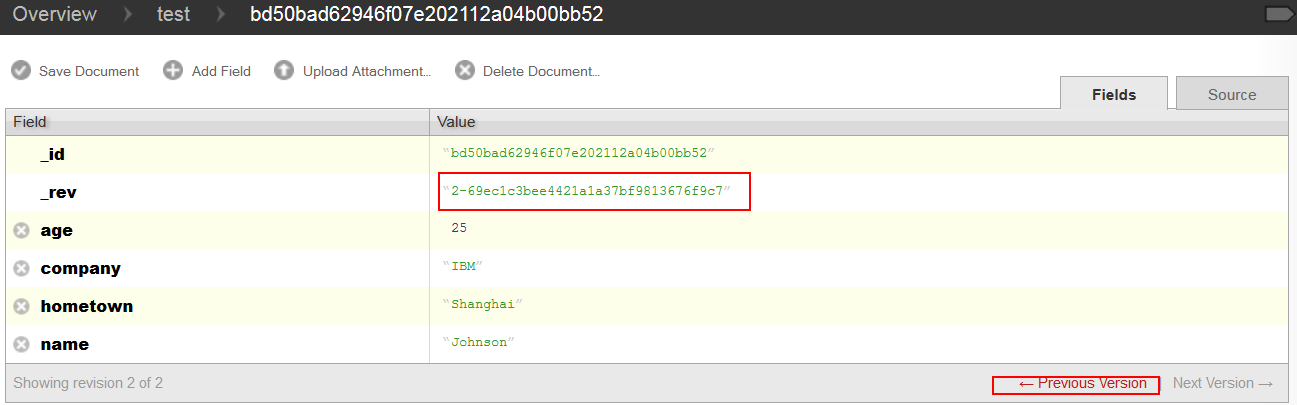
基于 CouchDB 的这种特性,当我们想要通过 update(documents) 批量插入数据时,只需将要插入的数据 dict 加入 documents 数组,如若未指定“_rev”和“_id”字段,系统将自动产生;当需要批量更新数据时,不论更新哪个字段,除赋予该字段新值外,都必须完整地在 dict 中加入该记录所有其他字段(包括“_rev”和“_id”),否则记录被更新后将丢失未列出的字段。至于如何一次性地将包含“_rev”和“_id”字段的整条记录取出为一个 dict, 将在介绍 view 时提到。插入和更新的示例代码如下:
插入三条记录:
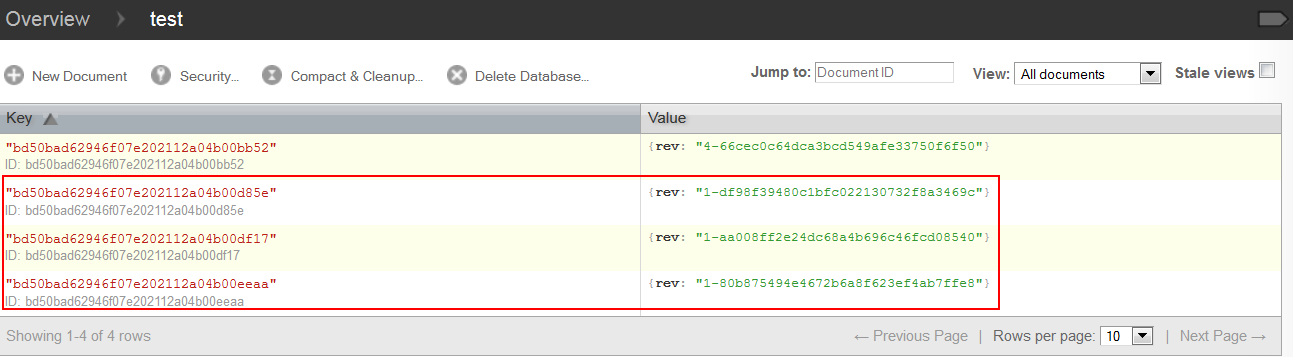
docs = [ dict(name='Mary',age='20',hometown='Shenzhen',company='NEC' ), dict(name='Leo',age='45',hometown='Wuhan',company='MS' ), dict(name='Kata',age='22',hometown='Chengdu',company='IBM' ) ] resultList=db.update(docs) updateNum=0 for item in resultList: if(item[0]): updateNum+=1 else: log.info('%s db[%s]' %(item[2],item[1])) log.info('%s update successfully/n' %updateNum) 循环遍历 update() 的返回值 list 是为了记录日志,明确地知道是否数据全部插入成功,如若失败,是什么原因导致了哪些记录插入失败。
如图 3,通过 futon 可以看到,三条新纪录产生。
图 3. 插入 3 条记录成功,“_rev”值首位均为 1
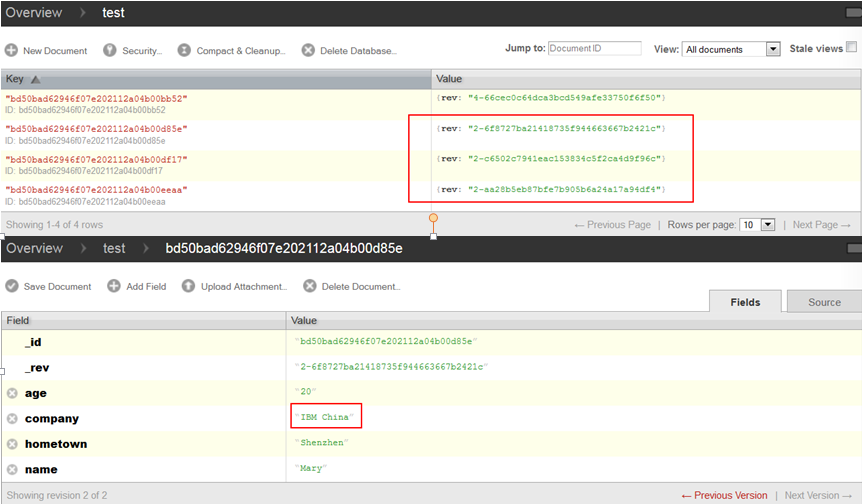
更新上面三条记录的 company 为“IBM China”,获取三条记录的完整字段,存入一个列表 docs,之后调用 update 方法即可。
代码如下:
docs = [dict( _id='bd50bad62946f07e202112a04b00d85e', _rev='1-df98f39480c1bfc022130732f8a3469c' name='Mary',age='20',hometown='Shenzhen',company='IBM China' ), dict( _id='bd50bad62946f07e202112a04b00df17', _rev='1-aa008ff2e24dc68a4b696c46fcd08540', name='Leo',age='45',hometown='Wuhan',company='IBM China' ), dict( _id='bd50bad62946f07e202112a04b00eeaa', _rev='1-80b875494e4672b6a8f623ef4ab7ffe8, name='Kata',age='22',hometown='Chengdu',company='IBM China' ) ] resultList=db.update(docs) updateNum=0 for item in resultList: if(item[0]): updateNum+=1 else: log.info('%s db[%s]' %(item[2],item[1])) log.info('%s update successfully/n' %updateNum) 如图 4,可以看到更新成功,且更新后的“_rev”值首位已经递增为 2
图 4. 更新 3 条记录成功,“_rev”值首位递增为 2
在实际开发过程中,如若需要批量插入数据,只需将每条数据拼成 Python 的 dict 格式,然后将所有 dict 放进列表并调用一次 update 方法即可;如若要更新数据,需要首先从数据库中获取带有完整字段的记录,CouchDB 提供了一种功能强大的视图功能,借助视图就可以将需要的记录完整的取出,下面我们介绍视图相关的方法。
回页首
使用 query() 和 view() 查询视图
CouchDB 中的 view 使得用户可以灵活快速地查询数据,实现类似 SQL 中 select 的功能,同时 view 也是 CouchDB 中实现数据 index 的一个过程,通过 JavaScript 语言编写的的 map function 来实现。view 分为 temporary view 和 predefined view 两种。
temporary view
由于 temporary view 所定义的 map function 和数据的 index 文件并没有真正保存在数据库中,用户可在程序中即写即用。因此它常用来快速地验证 map function 的功能。但正因为如此,每次调用 temporary view 都将对数据临时建立一次 index,在验证数据量比较大的数据库时,temporary view 的查询时间将会很慢。
test 数据库中现在有 4 条记录,其中有两条记录的 hometown 字段为“Shenzhen”,我们可以在 Python 中编写如下的 map function 来构建一个简单的 temporary view。尽管是在 Python 中,但 map function 的部分仍然需要使用 JavaScript 的语法:
map_fun ='''function(doc){ if(doc.hometown=="Shenzhen"){ emit(doc.age, doc); } }''' Map function 以 doc 作为唯一的参数,代表数据库中的一条记录。函数将查看记录中的 hometown 字段是否为“Shenzhen”,如果是,将调用内建的 emit(arg1,arg2) 方法。emit() 函数的两个参数中,第一个为 key,也即 index,可以是单一字段,也可以是多个字段组成的数组,这里我们以 age 字段作为 key;第二个为 value,即将要 emit 出的结果,如果设为 doc,将 emit 整条记录;如果设为 doc 的某个字段,如 doc.name, 将只 emit 该字段。这里我们将 emit 出整条记录 doc。
Couchdb-python 中用来执行 temporary view 的方法是 query(), 其参数如下:
query(map_fun, reduce_fun=None, language='javascript', wrapper=None, **options)
map_fun :map 函数名
reduce_fun:reduce 函数名 (可选)
language :函数语言,默认为 JavaScript
wrapper : 一个可选的参数,用来包裹查询结果,默认为空
options : 可选的查询参数,如 key=’yourkey’,descending=True
返回类型:List
此时就可以使用 query() 方法来获取 temporary view 的结果了
for row in db.query(map_fun,descending=True): print row.key print row.value print row
这里我们遍历 temporary view 的结果并依次打印出 key,value 和整条记录。options 参数使用 descending =True 将结果进行降序排序。
打印结果如下:
点击查看代码清单
关闭 [x]
25 {u'name': u'Johnson', u'hometown': u'Shenzhen', u'age': u'25', u'_id': u'bd50bad62946f07e202112a04b00bb52', u'company': u'IBM', u'_rev': u'5-6b8e641ab94b58c7782461f2d657de3d'} <Row id=u'bd50bad62946f07e202112a04b00bb52', key=u'25', value={u'name': u'Johnson', u'hometown': u'Shenzhen', u'age': u'25', u'_id': u'bd50bad62946f07e202112a04b00bb52', u'company': u'IBM', u'_rev': u'5-6b8e641ab94b58c7782461f2d657de3d'}> 20 {u'name': u'Mary', u'hometown': u'Shenzhen', u'age': u'20', u'_id': u'bd50bad62946f07e202112a04b00d85e', u'company': u'IBM China', u'_rev': u'2-6f8727ba21418735f944663667b2421c'} <Row id=u'bd50bad62946f07e202112a04b00d85e', key=u'20', value={u'name': u'Mary', u'hometown': u'Shenzhen', u'age': u'20', u'_id': u'bd50bad62946f07e202112a04b00d85e', u'company': u'IBM China', u'_rev': u'2-6f8727ba21418735f944663667b2421c'}> Predefined view
Predefined view 需要用户先在数据库中建立对应的 design doc,map function 作为 design doc 的一部分写在 design doc 中。design doc 的结构如下:
design_doc = {'_id': '_design/yourDisgnName, 'views': { 'yourViewName1': { 'map': 'function(doc){emit(doc.age,doc);' }, 'yourViewName2': { 'map': 'function(doc){emit(doc.hometown,doc);' } ... } } 每个 design doc 必须包括‘_id’和‘view’字段,且‘_id’字段的值必须为‘_design/yourDesignName’的格式,‘view’字段中可定义多个 map function, 每个 map function 拥有自己的名字,map function 的具体定义写在 map 字段的值中。这里我们定义了两个 map function, 分别在 age 和 hometown 字段建立了 index,emit 出所有的记录。之后只需使用 db.save(design_doc)方法即可将写好的 design doc 保存在数据库中。如图 5 所示。
图 5.design document 样例
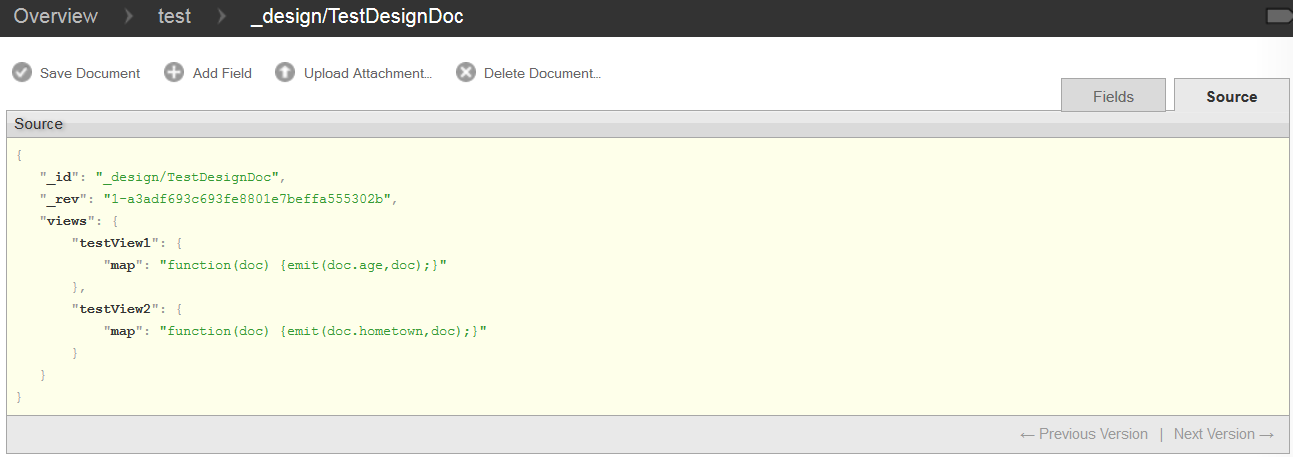
Couchdb-python 中用来执行 predefined view 的方法是 view(),
其参数如下:
view(name, wrapper=None, **options)
map_fun – design_docid/viewname
wrapper – 一个可选的参数,用来包裹查询结果,默认为空
options – 可选的查询参数,如 key=’yourkey’,descending=True 等
返回类型:List
使用 view() 来查询 hometown 为”Shenzhen”和”Wuhan”的记录:
results=db.view('yourDisgnName/yourViewName2',keys=['Shenzhen','Wuhan']) for row in results: dic=row.value print dic 这里的 options 参数我们使用了 keys=[key1,key2,...],在 CouchDB HTTP API 中列举了所有其他可选的查询参数,读者可灵活选择。
回页首
使用 changes() 监听数据库更新
changes() 方法即是对 CouchDB API 中_changes 的封装,它提供了一种监听数据库中数据变更的操作,并以时间顺序返回变更信息列表,可以用于构建类似消息通知和推送的服务。其常用方法参数列表如下:
- doc_ids (array) – 记录的 ID 列表,用于监听指定记录的改变。
- conflicts (boolean) –在返回值中包含冲突信息,默认值为 false。
- descending (boolean) – 以时间降序顺序返回数据变更结果,默认为 false。
- feed (string) –默认为 normal,这里我们设置为 continuous。
- include_docs (boolean) –在返回结果中包含每条记录的内容,默认为 false。
- limit (number) – 指定返回结果的数量。
- view (string) – 允许使用视图作为搜索条件。
ch = db.changes(feed='continuous', include_docs=True) counter=0 for each in ch: counter+=1 if (counter > 20): print each T=datetime.datetime.now print T counter=0
除非人为终止程序的运行,否则 feed=’continuous’将一直保持一个与 CouchDB 的连接(CouchDB 的并发机制可以很容易地在不影响效率的前提下支持这种长连接),只要有数据更新(包括删除)都将返回给 ch 列表,include_docs=True 将返回已更新的数据本身。Counter 计数器的作用是,在数据库中的更新操作大于 20 时返回被更新的记录。
回页首
总结:
通过本文的介绍相信读者可以在实际的开发工作中快速地编写 Python 脚本操作 CouchDB,希望文中提到的概念和示例代码对读者的开发工作提供一定的帮助。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

