分布式健康检查:实现OpenStack计算节点高可用
一、问题的背景
所谓计算节点高可用,是指在计算节点发生硬件故障,如磁盘损坏、CPU温度过高导致宕机、物理网络故障时,自动将该节点关闭,并让其上的虚拟机在剩下的健康节点上重启,如果可能,最好执行动态迁移。本文是在 今年OpenStack东京峰会上 分享的计算节点高可用话题的整理。
OpenStack最初定位面向公有云,没有考虑计算节点的高可用问题。理想情况下,在公有云上运行的应用有自己的集群和负载均衡,能在一定程度上容忍计算节点宕机带来的不可用,并能自动迁移负载。随着OpenStack的成熟,越来越多的企业客户开始在自己的私有云里采用OpenStack,将企业部署在虚拟化平台上的应用迁移到私有云中,计算节点高可用的特性需求越发迫切。但社区只提供了一些配合外部监控服务一起工作的机制,并没有提供完整的解决方案。因此厂家都可以根据自己的客户特点设计和部署自己的高可用方案。
在中国的虚拟化市场上,主流虚拟化平台都提供计算节点的高可用功能,以保证计算节点不可用时,虚拟机能迁移到其他计算节点。很多企业应用因此十分依赖于计算节点的高可用,缺乏计算节点高可用已经成为企业实施OpenStack的一个障碍。
二、社区的状态
OpenStack社区也意识到了这个问题,但是计算节点高可用的具体机制和策略与客户的IT基础设施环境、需求高度相关,所以社区并没有在OpenStack本身提供计算节点高可用。按照社区的构想,计算节点高可用由一个外部的系统实现,可以是Pacemaker或者Zookeeper。在Liberty中,OpenStack实现、改进了Nova的API,以便更好的配合外部高可用系统实现对Nova服务状态的改变和对虚拟机的漂移。
我们考察了Pacemaker和Zookeeper,这两个项目都是成熟的集群编排软件。其中红帽的RDO提供了基于Pacemaker-remote实现的高可用方案。社区里也有基于Zookeeper实现的Nova-compute的服务状态监控。但通过研究我们认为这两个项目都不适用于计算节点高可用的实现。
我们先来看一个典型的OpenStack部署架构。

在上面的OpenStack集群中,包含3个控制节点,3个计算节点,同时还部署了Ceph分布式存储作为Cinder的后端存储。控制节点和计算节点之间使用管理网互联,虚拟机全部从Cinder Volume启动,运行在Ceph存储上。虚拟机访问Ceph存储时,使用存储网。虚拟机之间通信,使用租户网。虚拟机和外网通信,先使用租户网连接到控制节点,控制节点再NAT到外网。
首先无论是Pacemaker-remote还是Zookeeper,监控计算节点状态时,使用的是服务器和计算节点之间互传心跳的方式。而默认的心跳网只有一个,通常部署在管理网上。这会导致两个问题,首先管理网断网会影响到Nova的控制面。用户无法再在有问题的节点上开启、关闭虚拟机,但虚拟机的存储、业务网依然完好。但Pacemaker在节点心跳网失效的默认动作是远程关闭物理机电源,这反而会导致虚拟机的业务中断。再者,如果心跳只运行在管理网上,那么存储网或者租户网故障时,通常检查不到,会错失迁移的良机。虽然可以在Pacemaker里配制多个心跳网络,但是多个心跳网络的状态并不能暴露给上层的监控服务使用。在Zookeeper里虽然可以通过变通的方式加多个心跳网,但是Zookeeper并没有内置对计算节点其他业务的检测和监控的支持,需要用户自己实现。对于这两个项目,也都存在一些扩展性问题。一般Pacemaker和Zookeeper的服务器的数量是3~5个,但是OpenStack集群中计算节点的数量可能是非常多的,计算节点的心跳会汇聚在少数几台服务器上。
三、分布式健康检查
我们基于 Consul 提出了一套分布式的健康检查的方案。Consul是一个在容器和微服务技术圈子里比较有名的项目,主要的功能是提供服务注册和发现、配制变更。但是Consul不仅可以做这些,它还提供了一个分布式的键值存储服务,支持分布式锁和领导节点的选举,并提供了事件的触发和订阅功能。Consul比较有趣的是其管理的集群规模可达数千个节点。Consul的集群拓扑结构如下图。
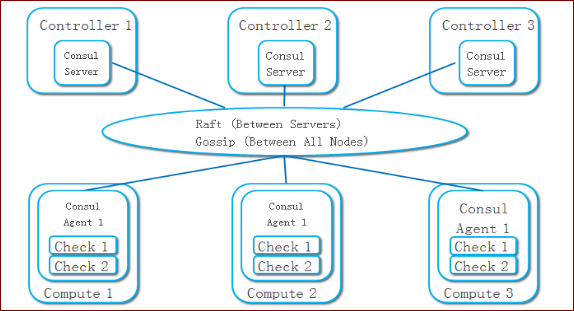
通常一个Consul集群会部署3~5个服务节点,其上的Consul Agent使用服务器模式运行,被管节点上的Consul Agent以普通模式运行。Consul的服务节点之间,使用Raft协议,实现一个强一致的集群,并实现了一个键值数据库。在一个Consul服务节点上成功存储的数据,马上可以从其他的Consul节点上读出来。在节点间维护状态强一致的成本比较高,因此Consul的服务节点数不会很多。
Consul的普通Agent在每台计算节点上运行,可以在每个Agent上添加一些健康检查的动作,Agent会周期性的运行这些动作。用户可以添加脚本或者请求一个URL链接。一旦有健康检查报告失败,Agent就把这个事件上报给服务器节点。用户可以在服务器节点上订阅健康检查事件,并处理这些报错消息。
在所有的Consul Agent之间(包括服务器模式和普通模式)运行着Gossip协议。服务器节点和普通Agent都会加入这个Gossip集群,收发Gossip消息。每隔一段时间,每个节点都会随机选择几个节点发送Gossip消息,其他节点会再次随机选择其他几个节点接力发送消息。这样一段时间过后,整个集群都能收到这条消息。示意图如下。
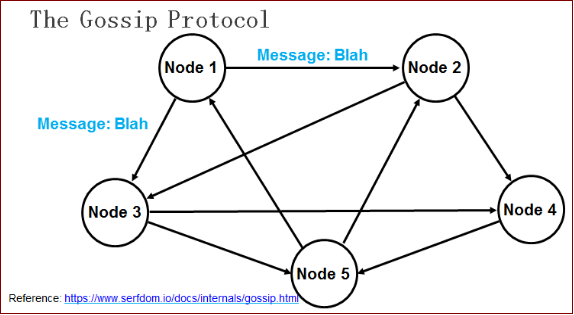
乍看上去觉得这种发送方式的效率很低,但在数学上已有论文论证过其可行性,并且Gossip协议已经是P2P网络中比较成熟的协议了。大家可以查看 Gossip的介绍 ,里面有一个模拟器,可以告诉你消息在集群里传播需要的时间和带宽。Gossip协议的最大的好处是,即使集群节点的数量增加,每个节点的负载也不会增加很多,几乎是恒定的。这就允许Consul管理的集群规模能横向扩展到数千个节点。
Consul的每个Agent会利用Gossip协议互相检查在线状态,本质上是节点之间互Ping,分担了服务器节点的心跳压力。如果有节点掉线,不用服务器节点检查,其他普通节点会发现,然后用Gossip广播给整个集群。具体的机制可以 参考这里 。
四、监控服务
利用Consul的这些特性,我们设计的分布式健康检查的架构如下图。
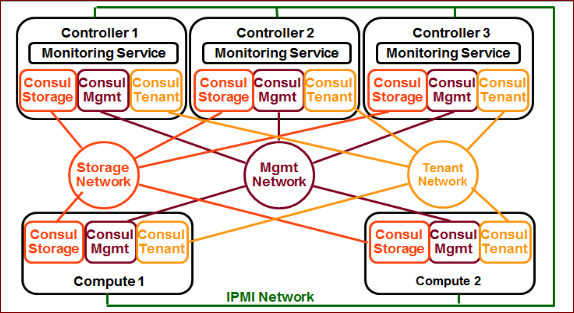
我们分别在管理、存储、租户网络上运行三个独立的Consul集群。所有的节点都运行三个Consul Agent,分别接入管理、存储、租户网的集群。控制节点的Consul Agent运行于服务器模式,计算节点的Consul Agent运行于普通模式。
由于分布式Ping机制的存在,Consul服务器节点上几乎没有什么负载,但是我们可以随时从任何一台服务器节点上的三个Consul Agent上分别取出每个计算节点在每个服务网络上的在线信息,并汇总。
我们在所有控制节点上都运行着一个监控服务,三个监控服务的实例使用Consul提供的分布式锁机制选举出一个领导。被选举成领导的监控服务实例实际执行高可用事件的处理,其他的监控服务实例热备待机。这样我们保证任意一台控制节点宕机,不会影响监控服务的运行。同时,我们的监控服务还监视本控制节点在每个业务网上的在线状态。假如某个控制节点的存储网掉线,从这个控制节点的存储网Agent得到的信息将是所有其他节点在存储网掉线,集群成员只剩自己。这个结果显然是不可信的。在这种情况下,监控服务会主动释放出集群锁,让领导角色漂移到其他节点上。
对检测到的每个计算节点的在线状态和健康检查指标,我们的监控服务会检查一个矩阵,矩阵综合考虑了各个指标综合作用下,异常情况的处理办法。示例矩阵如下图。
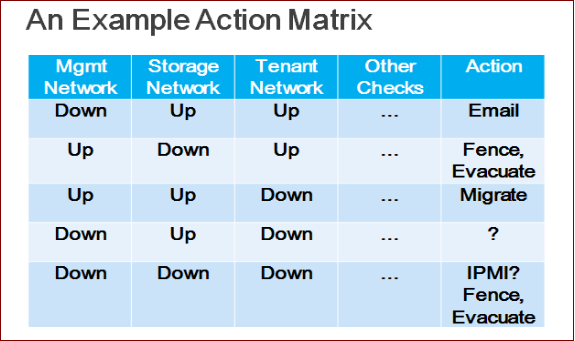
根据示例矩阵的第一行,如果某计算节点只有管理网掉线,只需要向管理员发送邮件,不应该对虚拟机做操作,否则会影响用户的应用。
矩阵的第二行的意思是,如果某计算节点存储网掉线,即使其他网络状态健康,我们运行在Ceph之上的虚拟机可能已经崩溃,并且该计算节点也不可能再成功运行新的虚拟机。这时我们应该做的是把计算节点隔离出集群、关机,并将其上的虚拟机“驱散”到其他健康的计算节点上。
对于不同的OpenStack部署模式和用户的需求,这个矩阵的内容可以是不同的,我们需要针对每个具体的OpenStack环境配置这个矩阵。
五、对Nova的改进
在Nova方面,Liberty版本引入一个新的API “os-services/force-down”。Nova默认的服务监控状态只监控管理网,并且监控的周期比较长。引入这个API后,外部监控服务通过其他的方式(譬如分布式Ping)监控到计算节点异常后,可以直接调用这个API,将计算节点的服务状态标记为“forced_down: true”。这样的好处是,不用等Nova发现自己的计算节点服务掉线,就可以直接“驱散”虚拟机。
另外,Liberty之前,调用Evacuate API时需要指定一个目的主机,作为“驱散”虚拟机的目的计算节点。对于外部的监控服务来说,指定一个目的主机很不方便,无从得知所有计算节点的资源使用情况,而且也可能违反Nova的调度策略。因此在Liberty中,对Nova的这个API进行了改进,可以不指定目的主机,而是由Nova的调度器自行决定应该将虚拟机“驱散”到哪些计算节点上。
关于作者
周征晟,任职于北京海云捷迅科技有限公司,负责自动化部署方面的开发和支持。
联系邮箱:zhengsheng@awcloud.com
感谢魏星对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入InfoQ读者交流群  (已满),InfoQ读者交流群(#2) )。
(已满),InfoQ读者交流群(#2) )。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

