每日一博 | 利用 pgpool 实现 PostgreSQL 高可用
基于流复制的方式,两节点自动切换:
1、单pgpool
a.环境:
pgpool:192.168.238.129 data1:192.168.238.130 data2:192.168.238.131
b.图例
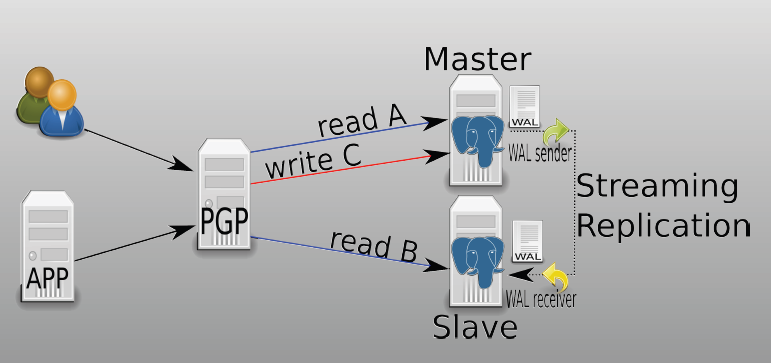
c.配置互信
ssh-copy-id ha@node1 ssh-copy-id ha@node2d.数据库节点配置,请参照《 使用pg_basebackup搭建PostgreSQL流复制环境
》。
e.pgpool配置:
listen_addresses = '*' backend_hostname0 = 'node1' backend_port0 = 5432 backend_weight0 = 1 backend_data_directory0 = '/home/ha/pgdb/data' backend_flag0 = 'ALLOW_TO_FAILOVER' backend_hostname1 = 'node2' backend_port1 = 5432 backend_weight1 = 1 backend_data_directory1 = '/home/ha/pgdb/data' backend_flag1 = 'ALLOW_TO_FAILOVER' enable_pool_hba = on pool_passwd = 'pool_passwd' pid_file_name = '/home/ha/pgpool/pgpool.pid' logdir = '/home/ha/pgpool/log' health_check_period = 1 health_check_user = 'ha' health_check_password = 'ha' failover_command = '/home/ha/pgdb/fail.sh %H' recovery_user = 'ha' recovery_password = 'ha'
f.fail.sh
# Failover command for streaming replication. # This script assumes that DB node 0 is primary, and 1 is standby. # # If standby goes down, do nothing. If primary goes down, create a # trigger file so that standby takes over primary node. # # Arguments: $1: failed node id. $2: new master hostname. $3: path to # trigger file. new_master=$1 trigger_command="/home/ha/pgdb/bin/pg_ctl -D /home/ha/pgdb/data promote -m fast" # Do nothing if standby goes down. if [ $failed_node = 1 ]; then exit 0; fi # Create the trigger file. /usr/bin/ssh -T $new_master $trigger_command exit 0;
g.建立pool_passwd
pg_md5 -m -p -u postgres pool_passwd
PS:在9.1之前一直用的是trigger_file,这里建议用promote -m fast的方式,因为
pg_ctl promote -m fast will skip the checkpoint at end of recovery so that we can achieve very fast failover when the apply delay is low. Write new WAL record XLOG_END_OF_RECOVERY to allow us to switch timeline correctly for downstream log readers. If we skip synchronous end of recovery checkpoint we request a normal spread checkpoint so that the window of re-recovery is low. Simon Riggs and Kyotaro Horiguchi, with input from Fujii Masao. Review by Heikki Linnakangas
h.测试
pgpool节点
[ha@node0 pgdb]$ pgpool -n -d > /tmp/pgpool.log 2>&1 & [1] 22928 [ha@node0 pgdb]$ psql -h 192.168.238.129 -p 9999 -d postgres -U ha Password for user ha: psql (9.4.5) Type "help" for help. postgres=# insert into test values (8); INSERT 0 1 postgres=# select * from test ; id ---- 1 2 3 4 6 8 (6 rows)
node1节点:
[ha@localhost pgdb]$ ps -ef | grep post root 2124 1 0 Dec26 ? 00:00:00 /usr/libexec/postfix/master postfix 2147 2124 0 Dec26 ? 00:00:00 qmgr -l -t fifo -u postfix 13295 2124 0 06:01 ? 00:00:00 pickup -l -t fifo -u ha 13395 1 0 06:06 pts/3 00:00:00 /home/ha/pgdb/bin/postgres ha 13397 13395 0 06:06 ? 00:00:00 postgres: checkpointer process ha 13398 13395 0 06:06 ? 00:00:00 postgres: writer process ha 13399 13395 0 06:06 ? 00:00:00 postgres: wal writer process ha 13400 13395 0 06:06 ? 00:00:00 postgres: autovacuum launcher process ha 13401 13395 0 06:06 ? 00:00:00 postgres: stats collector process ha 13404 13395 0 06:07 ? 00:00:00 postgres: wal sender process rep 192.168.238.131(59415) streaming 0/21000060 ha 13418 4087 0 06:07 pts/3 00:00:00 grep post [ha@localhost pgdb]$ kill -9 13395
pgpool节点:
postgres=# insert into test values (8); server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. The connection to the server was lost. Attempting reset: Succeeded. postgres=# insert into test values (8); INSERT 0 1 postgres=# insert into test values (8); INSERT 0 1 postgres=# select * from test ; id ---- 1 2 3 4 6 8 8 8 (8 rows)
2.两个pgpool节点
a.环境
pgpool:192.168.238.129 pgpool:192.168.238.131 node1:192.168.238.130 node2:192.168.238.131
b.图例
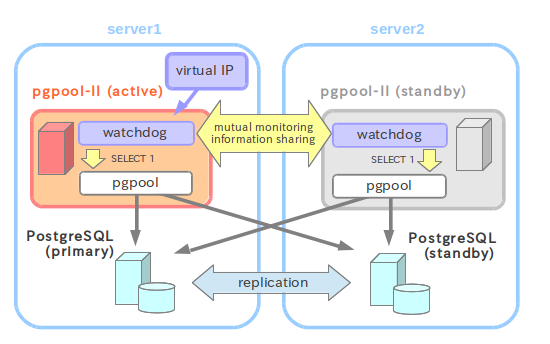
c.配置互信,同上。
d.数据库节点配置,同上。
e.pgpool配置
node1
f.配置pgpool(主)
listen_addresses = '*' backend_hostname0 = 'node1' backend_port0 = 5432 backend_weight0 = 1 backend_data_directory0 = '/home/ha/pgdb/data/' backend_flag0 = 'ALLOW_TO_FAILOVER' backend_hostname1 = 'node2' backend_port1 = 5432 backend_weight1 = 1 backend_data_directory1 = '/home/ha/pgdb/data/' backend_flag1 = 'ALLOW_TO_FAILOVER' enable_pool_hba = on authentication pool_passwd = 'pool_passwd' pid_file_name = '/home/ha/pgpool/pgpool.pid' logdir = '/tmp/log' master_slave_mode = on master_slave_sub_mode = 'stream' sr_check_period =2 sr_check_user = 'ha' sr_check_password = 'ha' health_check_period = 1 health_check_timeout = 20 health_check_user = 'ha' health_check_password = 'ha' failover_command = '/home/ha/pgpool/fail.sh %H' recovery_user = 'ha' recovery_password = 'ha' use_watchdog = on wd_hostname = 'node1' #本端 delegate_IP = '192.168.238.151' #利用ifconfig,查看网卡 if_up_cmd = 'ifconfig eth1:0 inet $_IP_$ netmask 255.255.255.0' if_down_cmd = 'ifconfig eth1:0 down' heartbeat_destination0 = 'node2' #对端 heartbeat_device0 = 'eth0' other_pgpool_hostname0 = 'node2' #对端 other_pgpool_port0 =9999 other_wd_port0 = 9000
g.配置pgpool(从)
listen_addresses = '*' backend_hostname0 = 'node1' backend_port0 = 5432 backend_weight0 = 1 backend_data_directory0 = '/home/ha/pgdb/data/' backend_flag0 = 'ALLOW_TO_FAILOVER' backend_hostname1 = 'node2' backend_port1 = 5432 backend_weight1 = 1 backend_data_directory1 = '/home/ha/pgdb/data/' backend_flag1 = 'ALLOW_TO_FAILOVER' enable_pool_hba = on authentication pool_passwd = 'pool_passwd' pid_file_name = '/home/ha/pgpool/pgpool.pid' logdir = '/tmp/log' master_slave_mode = on master_slave_sub_mode = 'stream' sr_check_period =2 sr_check_user = 'ha' sr_check_password = 'ha' health_check_period = 1 health_check_timeout = 20 health_check_user = 'ha' health_check_password = 'ha' failover_command = '/home/ha/pgpool/fail.sh %H' recovery_user = 'ha' recovery_password = 'ha' use_watchdog = on wd_hostname = 'node2' #本端 delegate_IP = '192.168.238.151' #利用ifconfig,查看网卡 if_up_cmd = 'ifconfig eth1:0 inet $_IP_$ netmask 255.255.255.0' if_down_cmd = 'ifconfig eth1:0 down' heartbeat_destination0 = 'node1' #对端 heartbeat_device0 = 'eth1' other_pgpool_hostname0 = 'node1' #对端 other_pgpool_port0 =9999 other_wd_port0 = 9000
h.fail.sh
# Failover command for streaming replication. # This script assumes that DB node 0 is primary, and 1 is standby. # # If standby goes down, do nothing. If primary goes down, create a # trigger file so that standby takes over primary node. # # Arguments: $1: failed node id. $2: new master hostname. $3: path to # trigger file. new_master=$1 trigger_command="/home/ha/pgdb/bin/pg_ctl -D /home/ha/data start" # Do nothing if standby goes down. if [ $failed_node = 1 ]; then exit 0; fi # Create the trigger file. /usr/bin/ssh -T $new_master $trigger_command exit 0;i.建立pool_passwd
pg_md5 -m -p -u postgres pool_passwd
j.测试
#数据库、pgpool启动 [ha@node0 pgdb]$ psql -h 192.168.238.151 -p 9999 -d postgres -U ha Password for user ha: psql (9.4.5) Type "help" for help. postgres=# insert into test values (9); INSERT 0 1 postgres=# insert into test values (9); INSERT 0 1 postgres=# --杀掉node1的数据库进程 postgres=# insert into test values (9); server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. The connection to the server was lost. Attempting reset: Succeeded. postgres=# insert into test values (9); INSERT 0 1 postgres=# insert into test values (9); INSERT 0 1 postgres=# insert into test values (9); INSERT 0 1 postgres=# insert into test values (9); INSERT 0 1 postgres=# insert into test values (9); INSERT 0 1 postgres=# insert into test values (9); INSERT 0 1 postgres=# insert into test values (9); INSERT 0 1 postgres=# insert into test values (9); INSERT 0 1 --杀掉node1的pgpool进程 postgres=# insert into test values (9); server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. The connection to the server was lost. Attempting reset: Succeeded. postgres=# insert into test values (9); INSERT 0 1 postgres=# insert into test values (9); INSERT 0 1 postgres=#
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

