迭代、递归与Tail Call Optimization
在程序设计的世界里面有两种很基本的设计模式,那就是迭代(iterative)和递归(recursive)。这两种模式之间存在着很强的一致性和对称性。
现在让我来设计一段程序,计算 n! , 不能使用任何循环结构 。我们把这个过程封装成一个函数 calc ,假设 n=4 ,整个计算的 过程(Process) 是这样的。
calc(4)=4*calc(3)
calc(3)=3*calc(2)
calc(2)=2*calc(1)
calc(1)=1*calc(0)
calc(0)=1
对应的 程序(Procedure) 可以被写成:
def calc(n):
"""
Calculate n!
:param n: N
"""
if n == 0:
return 1
if n < 0:
raise ValueError
return n * calc(n - 1)
我在上面特别强调了过程和程序的差别,这对后文很重要。Procedure一般也被翻译成过程,为了避免冲突,我将它翻译成程序。过程实际上是一个数学的模型,用文字表述,是比较抽象的;而程序相对而言就是具象化的。程序可以用来实现过程。
将上面的过程展开后可以变成下面这样,我们将之称作 过程A 。
calc(4)=4*calc(3)
=4*(3*calc(2))
=4*(3*(2*calc(1)))
=4*(3*(2*(1*calc(0))))
=4*(3*(2*(1*1)))
=4*(3*(2*1))
=4*(3*2)
=4*6
24
计算 n! 的过程不止一种。我们还可以想到另外一种计算过程来计算 4! 。设 result 为最后的结果。
result=1
n=4
result=result*n=4
n=n-1=3
result=result*n=12
n=n-1=2
result=result*n=24
n=n-1=1
result=result*n=24
n=n-1=0
相应的程序实现可以为
def calc(n):
"""
Calculate n!
"""
if n < 0:
raise ValueError
return calc_iter(n, 1)
def calc_iter(n, result):
if n == 0:
return result
return calc_iter(n - 1, result * n)
整个过程展开就变成了
calc(4)=calc_iter(4, 1)
calc_iter(4, 1)
calc_iter(3, 4)
calc_iter(2, 12)
calc_iter(1, 24)
calc_iter(0, 24)
这个展开后的过程我们称之为 过程B 。
递归与迭代
对比过程A和B,过程A看起来比较“浪费空间”,至少我得打更多的字表达它。它们之间最大的区别是,在过程A中,前一次计算的结果要靠后一次计算的结果以及它本身的参数结合才能得出来。例如在计算 calc(4)=4*calc(3) 的时候, calc(3) 就是下一次计算的结果,而 4 是 calc(4) 本身的参数。
反之,在过程B中,前一次计算的结果和后一次计算的结果都通过参数传递。每次计算的参数就是这次计算所需的所有 状态 。如果你读过我写的 “函数是一等公民”背后的含义 ,你就会发现这是函数式编程里面纯函数的特性。
过程A,这类前一次计算依赖于自身状态和后一次计算的结果的过程我们就称之为递归过程(Recursive Process),因为它最后总要回到之前的计算中才能获得最后结果;而过程B,这类每次计算结果仅依赖于自身状态的过程我们就称之为迭代过程(Iterative Process)。
Tail Call Optimization (TCO)
如果我们观察上面的第二段程序,我们会说这是一个递归函数,因为它用了函数的递归调用。但是我们已经提到了,它实际上是一个迭代过程,而不是递归过程。因为每一次调用 calc_iter 的时候,本次计算的结果都能由自身状态得出来。它完全可以被重写为
def calc(n):
"""
Calculate n!
"""
if n < 0:
raise ValueError
result = 1
while n > 0:
result, n = result * n, n - 1
return result
因此,尽管有些函数被写成了递归的形式,它依然可能是表示一个迭代的过程。很有趣的是,尽管它是迭代过程,但是它还是占用了栈空间。如果 n 足够大的话,这个迭代过程依然可能跟传统的递归函数实现一样产生栈溢出。

既然每次计算都包含着本次计算所需的所有状态,那就说明我们实际上没有必要把前面一次计算的函数调用推入栈中。因为无论如何,我们都不会再用到之前的调用了。这种不将前一次函数调用推入栈中的优化就被称作Tail Call Optimization。之所以叫Tail Call是因为在用递归函数实现迭代过程的时候,对下一次计算过程的调用都在尾部。理由很简单,因为我们不再需要回到这个函数,所以在递归调用之后就不需要有其他的逻辑了。
TCO的实现
目前TCO的实现还局限在一些纯函数式编程语言例如Common Lisp。大部分常用的语言并没有实现TCO,但是认识到TCO可以帮助我们更好地理解我们所设计的迭代或者递归过程。
Python、Java之类的非纯函数式编程语言没有实现TCO的表面原因是因为Stack trace。如果实现了TCO,那么在执行被TCO的函数期间遇到错误的时候就无法打印出Stack trace,因为这样的函数执行时不存在推入Stack的说法。
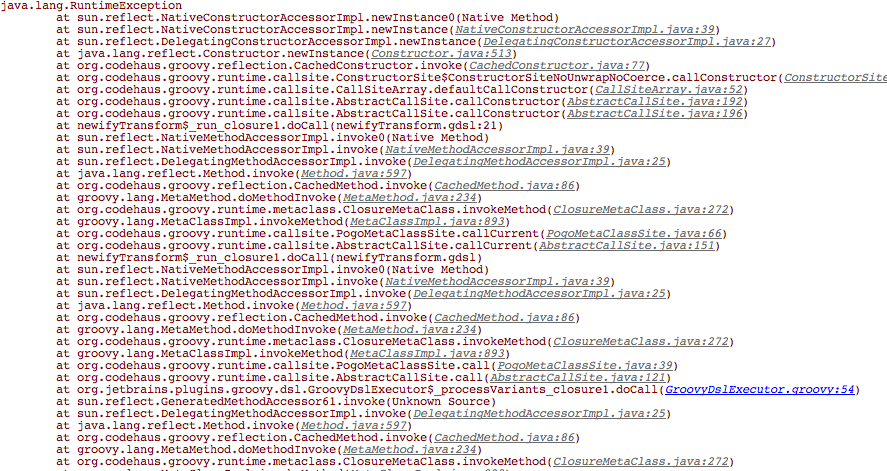
图片来源
阅读书目
- Structure and Interpretation of Computer Program, Chapter 1
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

