95188:BLSTM-DNN hybrid语音识别声学模型的第一个工业应用
双十一当天,蚂蚁金服客户中心整体服务量超过500万人次,94%以上都是通过人工智能技术驱动的自助服务解决。在整个自助服务中,非常重要的一环是呼叫中心的语音转文本服务,这是一个典型的电话语音识别问题。
电话语音识别是当今语音识别领域最复杂最困难的问题之一。对话过程中说话人风格自然随意、口音、不流利(重复、修改自己的说法)、传输信道复杂多样等各种不利因素都集中在这个场景中。随着深度学习等技术的发展,当今电话语音识别的准确率已经达到了不错的水平,这在几年前都是难以想象的。
我们使用的是基于LC-BLSTM-DNN hybrid的语音识别声学模型,为了检测该模型的效果,我们特别邀请一位技术特别牛、普通话口音也挺牛的同学,拨打支付宝95188客服热线,体验了一次阿里巴巴iDST于不久前升级上线的最新语音识别技术。结果让人惊讶。据我们所知(to the best of our knowledge),这也是该种模型结构在语音识别领域上线的第一个工业界应用。本文将会介绍这一声学模型的背景,及我们的具体实现工作。
传统上语音识别声学模型一般采用GMM-HMM进行建模。近年来,随着深度学习技术的发展,基于DNN-HMM的建模方法取得了长足发展,相比传统方法可以使语音识别的准确率相对提升20%-30%,已取代前者成为学术界和工业界的主流配置。DNN的优点在于通过增加神经网络的层数和节点数,扩展了网络对于复杂数据的抽象和建模能力,但同时DNN也存在一些不足,例如DNN中一般采用拼帧来考虑上下文相关信息对于当前语音帧的影响,这并不是反映语音序列之间相关性的最佳方法。自回归神经网络(RNN)在一定程度上解决了这个问题,它通过网络节点的自连接达到利用序列数据间相关性的目的。进一步有研究人员提出一种长短时记忆网络(LSTM-RNN),它可以有效减轻简单RNN容易出现的梯度爆炸和梯度消散问题,而后研究人员又对LSTM进行了扩展,使用双向长短时记忆网络(BLSTM-RNN)进行声学模型建模,以充分考虑上下文信息的影响。
BLSTM可以有效地提升语音识别的准确率,相比于DNN模型,相对性能提升可以达到15%-20%。但同时BLSTM也存在两个非常重要的问题:
- 句子级进行更新,模型的收敛速度通常较慢,并且由于存在大量的逐帧计算,无法有效发挥GPU等并行计算工具的计算能力,训练会非常耗时;
- 由于需要用到整句递归计算每一帧的后验概率,解码延迟和实时率无法得到有效保证,很难应用于实际服务。
对于这两个问题,文献[1]首先提出Context-Sensitive-Chunk BLSTM(CSC-BLSTM)的方法加以解决,而此后文献[2]又提出了Latency Controlled BLSTM(LC-BLSTM)这一改进版本,更好、更高效的减轻了这两个问题。我们在此基础上采用LC-BLSTM-DNN混合结构配合多机多卡、16bit量化等训练和优化方法进行声学模型建模,取得了相比于DNN模型约17-24%的相对识别错误率下降。目前该套模型已在电话语音识别中率先应用,并将陆续在我们支持的其他语音识别业务上线。
什么是“Latency Controlled BLSTM”
典型的LSTM节点结构下图所示,与一般DNN或simple RNN采用简单的激活函数节点不同,LSTM由3个gate:input gate、forget gate、output gate和一个cell组成,输入、输出节点以及cell同各个门之间都存在连接;input gate、forget gate同cell之间也存在连接,cell内部还有自连接。这样通过控制不同门的状态,可以实现更好的长短时信息保存和误差传播。

LSTM可以像DNN一样逐层堆积成为Deep LSTM,为了更好的利用上下文信息,还可以使用BLSTM逐层堆积构造Deep LSTM,其结构如下图所示,网络中沿时间轴存在正向和反向两个信息传递过程,每一个时间帧的计算都依赖于前面所有时间帧和后面所有时间帧的计算结果,对于语音信号这种时序序列,该模型充分考虑了上下文对于当前语音帧的影响,能够极大的提高音素状态的分类准确率。
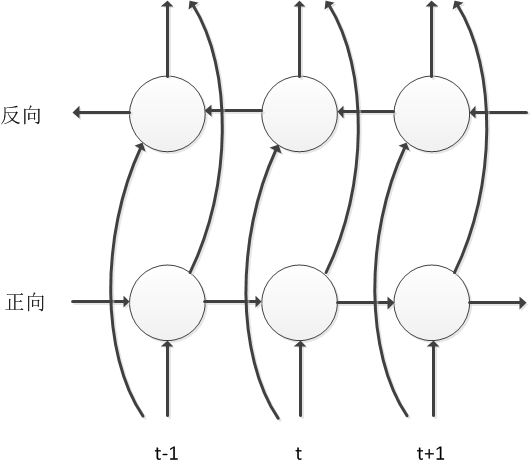
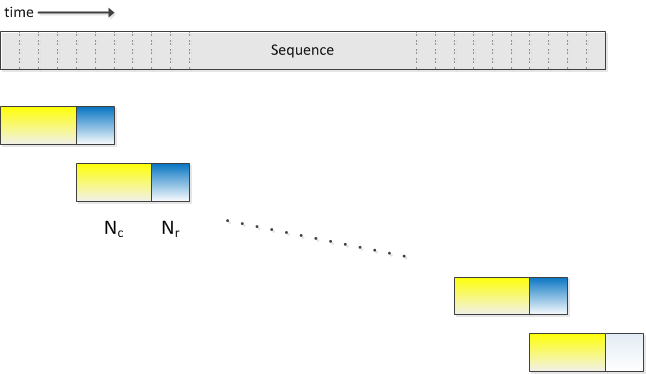
然而由于标准的BLSTM是对整句语音数据进行建模,训练和解码过程存在收敛慢、延迟高、实时率低等问题,针对这些弊端我们采用了Latency Controlled BLSTM进行解决,与标准的BLSTM使用整句语音进行训练和解码不同,Latency Control BLSTM使用类似truncated BPTT的更新方式,并在cell中间状态处理和数据使用上有着自己的特点,如下图所示,训练时每次使用一小段数据进行更新,数据由中心chunk和右向附加chunk构成,其中右向附加chunk只用于cell中间状态的计算,误差只在中心chunk上进行传播。时间轴上正向移动的网络,前一个数据段在中心chunk结束时的cell中间状态被用于下一个数据段的初始状态,时间轴上反向移动的网络,每一个数据段开始时都将cell中间状态置为0。该方法可以很大程度上加快网络的收敛速度,并有助于得到更好的性能。解码阶段的数据处理与训练时基本相同,不同之处在于中心chunk和右向附加chunk的维度可以根据需求进行调节,并不必须与训练采用相同配置。
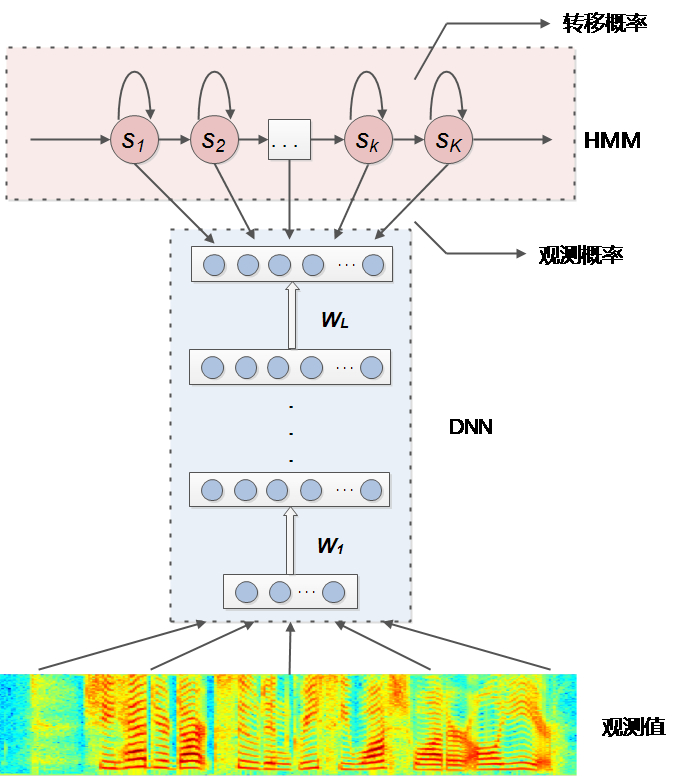
基于LC-BLSTM-DNN混合模型结构的声学模型
一般的基于DNN的语音识别声学模型结构如下图所示,DNN 的输入一般采用传统频谱特征及其改进特征 (如 MFCC、PLP、Filterbank 等) 经过帧拼接得到,拼接长度一般选择 9-15 帧之间,时间上约 10ms左右。而输出则一般采用各种粒度的音素声学单元,常见的有单音子音素 (Monophone)、单音子音素的状态以及三音子音素 (Triphone) 绑定状态等。输出层的标注一般采用 GMM-HMM 基线系统经强对齐( Forced-alignment)得到。
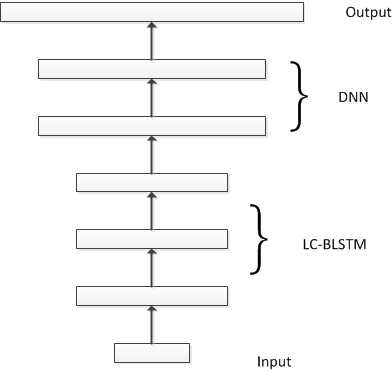
与DNN类似,我们可以通过堆积LC-BLSTM得到Deep LC-BLSTM,但是单纯使用多层LC-BLSTM来构成声学模型不仅在计算复杂度上会带来很大压力,更为重要的是并不能取得最优的识别性能。经过多组实验尝试,我们决定采用LC-BLSTM-DNN混合模型结构,输入语音特征先经过3层节点数为1000(正向+反向) LC-BLSTM变换,再经过2层节点数为2048的DNN全连接和softmax层得到输出,如下图所示。识别结果与最好的DNN基线比较如下表所示,目前网络规模和参数配置还在不断优化中。
| CER% | 产品线A | 产品线B | 产品线C |
|---|---|---|---|
| DNN | 15.4 | 11.1 | 12.4 |
| LC-BLSTM-DNN | 12.7(17.5%) | 8.51(23.4%) | 9.4(24.2%) |
多机多卡实现大数据下的模型训练
我们采用团队内部同学开发的多机多卡训练工具进行LC-BLSTM-DNN声学模型训练,在使用6机12卡,训练数据集大小为2100小时的情况下,加速效果如下表所示:
| 处理一个 epoch 所需时间(小时) | |
|---|---|
| 单机单卡 (Baseline) | 65.6 |
| 6机12卡(Middleware) | 6.5(10.1x加速) |
可以看到6机12卡的加速比约为10.1倍,通常在5-6次epoch迭代后即可收敛,即一天半以内即可完成模型的训练,可以预期即使未来达到一万小时的训练数据,模型训练也可以在一周内完成。如果进一步增加机卡数目,加速比还会进一步的提高。可以说LC-BLSTM-DNN的训练高耗时问题已通过该多机多卡训练工具很好的解决。
解码延迟和实时率的优化
DNN由于需要使用拼帧技术,解码延迟通常在5-10帧,大约50-100ms。标准的BLSTM则需要整句的延迟,而在LC-BLSTM-DNN中由于使用了chunk数据计算的技术,解码的延迟可以控制在20帧左右,大约200ms,对于对延迟要求更为严格的线上服务类任务,还可以在少量损失识别性能的情况下(0.2%-0.3%绝对值左右),将延迟控制在100ms,完全可以满足各类任务的需求。
在解码实时率方面,虽然我们设计的LC-BLSTM-DNN模型结构相比普通Deep BLSTM已经减少了很多的计算复杂度,但未经任何优化的LC-BLSTM-DNN仍不能满足需求,为此我们从两方面着手尝试解决这一问题。一方面,我们通过许多工程技术进行优化,包括使用16bit量化技术对特征数据和网络权重进行处理,在基本不损失识别性能的情况下,大大提高了计算效率;我们还使用了lazy技术对最后一个softmax层的计算进行优化,进一步提高了实时率。现有的模型在一台普通笔记本电脑上已经可以取得约1.1倍实时率。另一方面,我们从模型结构和算法层面入手,尝试使用跳帧、projection层、SVD分解、模型分辨率调整等技术来加速模型的计算,初步已取得不错的效果,目前许多工作正在进行中。
技术讨论和展望
近一两年语音识别技术在原有DNN技术基础上又取得了可喜的进展。例如CTC技术,一般认为CTC与LSTM结合可以有助于模型学习到下文Context信息,取得与BLSTM相当的识别效果,而由于BLSTM已经可以学习到下文的Context信息,因此CTC与BLSTM结合并不能再带来明显的性能提升。LSTM+CTC在计算复杂度和解码速度上相比BLSTM具有一定的优势,但许多研究人员也发现LSTM+CTC模型存在对音素时间边界估计不准确的问题,这对某些需要准确估计音素边界的任务,如语音数据脱敏等,是一个不小的问题。还有一些诸如Attention-based模型等技术同样在研究中取得了不错的进展。相信未来会有更为优异的模型结构和算法来不断的提高语音识别的准确率,智能语音交互亦会在此基础上取得不断的进步。
参考文献
[1] Chen K, Yan Z J, Huo Q. A context-sensitive-chunk BPTT approach to training deep LSTM/BLSTM recurrent neural networks for offline handwriting recognition[C]. 2015 13th International Conference on Document Analysis and Recognition (ICDAR). IEEE Computer Society, 2015:411-415.
[2] Yu Zhang, Guoguo Chen, Dong Yu, Kaisheng Yao, Sanjeev Khudanpur, James GlassHighway Long Short-Term Memory RNNs for Distant Speech Recognition. http://arxiv.org/abs/1510.08983
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

