为什么越来越多的公司在使用Spark Streaming
Databricks最近对1400多家Spark用户进行了一次调查,结果显示这些用户对Spark Streaming的使用率与2014年相比增长了56%,另外,有48%的受访者将Spark Streaming标记为最常用的Spark组件。在Spark Streaming不断增长的用户群中,Uber、Netflix和Pinterest等家喻户晓的公司赫然在列,那么为什么使用Spark Streaming加速业务发展的公司越来越多呢?最近Spark Streaming的主要开发人员Tathagata Das在DataNami上发表了一篇文章, 从需求、功能以及用户场景等方面对此进行了介绍 。
流分析的需求
现在,几乎所有的公司都是一家软件公司,它们实时地监控传感器、物联网设备、社交网络和在线事务系统产生的数据,然后通过大规模、实时的流处理系统对其进行分析从而实现快速响应。此外,公司还会使用这些数据生成日报和业务模型。也就是说,现代流处理框架不仅需要应对实时场景,还需要处理预处理和后处理等非实时场景。
例如,电商需要对用户在线购买时产生的数据(包括日期、时间、物品、价格等)进行实时分析完成广告推送和相关性推荐。银行需要使用训练好的欺诈模型实时地对每一笔交易进行检测从而定位欺诈行为。
Spark Streaming不仅能够非常好地解决这些问题,同时它还统一了技术框架,使用了与Spark一致的编程模型和处理引擎。而在Spark Streaming出现之前,用户需要借助多种开源软件才能构建出具有流处理、批处理和机器学习能力的系统。
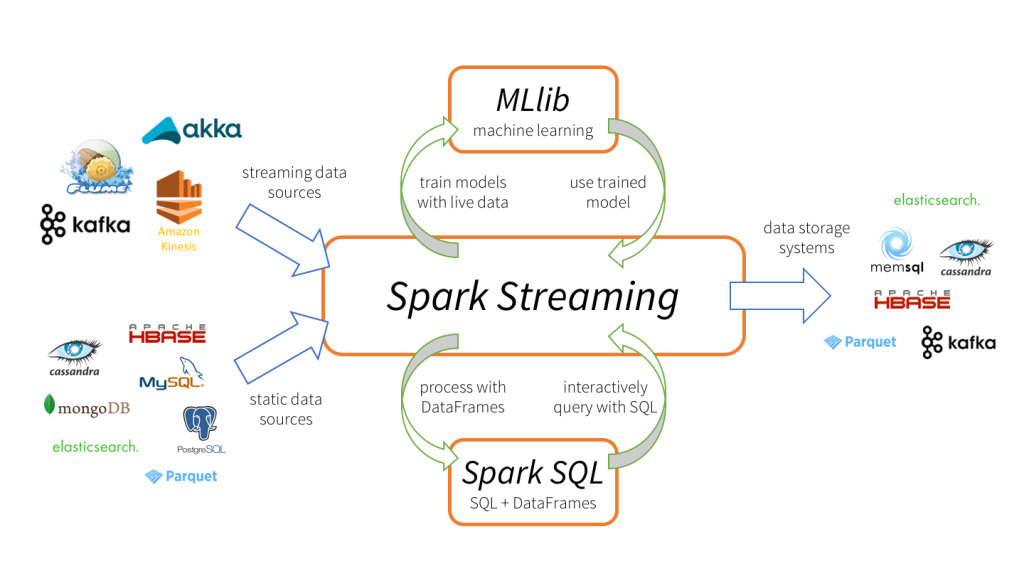
Spark Streaming的能力
Spark Streaming是在2013年被添加到Apache Spark中的,作为核心Spark API的扩展它允许数据工程师和数据科学家实时地处理来自于Kafka、Flume以及Amazon Kinesis等多种源的数据。这种对不同数据的统一处理能力就是Spark Streaming会被大家迅速采用的关键原因之一。
Spark Streaming能够按照batch size(如1秒)将输入数据分成一段段的离散数据流(Discretized Stream,即DStream),这些流具有与RDD一致的核心数据抽象,能够与MLlib和Spark SQL等Spark组件无缝集成。
通过Spark Streaming开发者能够容易地使用一种框架满足所有的处理需求,例如通过MLlib离线训练模型,然后直接在Spark Streaming中使用训练好的模型在线处理实时数据。同时,开发者编写的代码和业务逻辑也能够在流处理、批处理和交互式处理引擎中共享和重用。此外,流数据源中的数据还可以与很多其他的Spark SQL能够访问的静态数据源进行联合。例如,在将Amazon Redshift的静态数据推送到下游系统之前,可以先将其加载到Spark的内存中进行处理以丰富流数据。
用例——从Uber到Pinterest
虽然针对不同的目标和业务案例使用Spark Streaming的方式也不同,但其主要场景包括:
- 流ETL——将数据推入存储系统之前对其进行清洗和聚合
- 触发器——实时检测异常行为并触发相关的处理逻辑
- 数据浓缩——将实时数据与静态数据浓缩成更为精炼的数据以用于实时分析
- 复杂会话和持续学习——将与实时会话相关的事件(例如用户登陆Web网站或者应用程序之后的行为)组合起来进行分析。
例如,Uber通过Kafka、Spark Streaming和HDFS构建了持续性的ETL管道,该管道首先对每天从移动用户那里收集到的TB级的事件数据进行转换,将原始的非结构化事件数据转换成结构化的数据,然后再进行实时地遥测分析。Pinterest的ETL数据管道始于Kafka,通过Spark Streaming将数据推入Spark中实时分析全球用户对Pin的使用情况,从而优化推荐引擎为用户显示更相关的Pin。Netflix也是通过Kafka和Spark Streaming构建了实时引擎,对每天从各种数据源接收到的数十亿事件进行分析完成电影推荐。
感谢杜小芳对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入InfoQ读者交流群  (已满),InfoQ读者交流群(#2) )。
(已满),InfoQ读者交流群(#2) )。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

