使用Whoosh实现的社工库应用

整理电脑的时候翻出了之前用 Python 写的一个社工库,使用 Whoosh 对社工库文件按行分词建立索引,直接利用索引来查密码,返回 json 格式结果。
以前收集了很多泄露的数据库,包含txt、sql、csv、html、xlsx、xls等文件类型,文件内容也是多种多样。想把这些数据处理一下做个社工库,方便以后自用。网上大多都是利用PHP+Mysql来搭建社工库,把数据分类处理一下格式,然后将格式化之后的存入数据库再进行搜索。
本打算搭建一个试试,后来仔细想想放弃了。首先对这些数据进行整理是一个非常耗时的事情,还需要对不同格式的数据做相应的处理;其次数据整理后存储入数据库,数据多了,查询效率可能也不是很高,所以就放弃了。
后来看到关于Whoosh的介绍,一个完全由python实现的全文搜索引擎,基础架构和 Lucene 比较像,使用KinoSearch的索引算法,部分评分算法来自Terrier。虽然性能上跟xapian等的差距还是挺大的,但是纯python实现,集成和扩展起来比较容易。
Whoosh还提供了很多预定义域类型,方便创建索引:
v ID:仅能为一个单元值,即不能分割为若干个词,如文件路径,URL,日期,分类。
v STORED:该字段随文件保存,但是不能被索引,也不能被查询。
v KEYWORD:用空格或者逗号分割的关键词,可被索引和搜索。不支持词汇搜索。
v TEXT:文本内容。建立文本的索引并存储,支持词汇搜索。
v NUMERIC:数字类型
v BOOLEAN:布尔类值
v DATETIME:时间对象类型
下图是一个例子,用Whoosh创建要给索引schema,然后建立索引,非常简单。
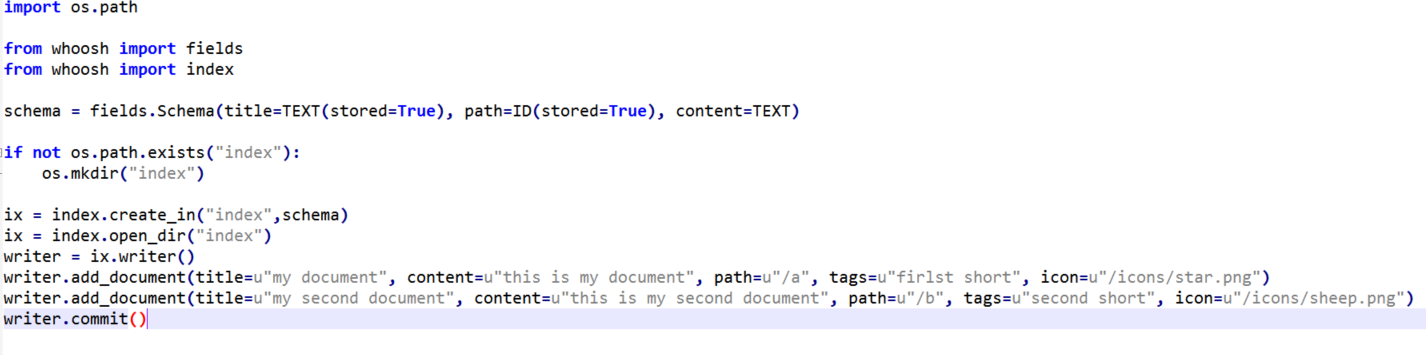
然后打算使用Whoosh为核心来搭建一个社工库应用,毕竟是自用,查询效率上稍微慢一点也能接受。简单的规划了几个自己比较在意的功能:
1、实现断点索引;
2、自动识别txt、html、sql、csv等社工库文件的编码;
3、自动去除重复的文件;
4、创建一个web接口作为查询接口使用;
5、创建一个文件夹用来存储社工库,对这个文件夹中的新增文件自动创建索引;
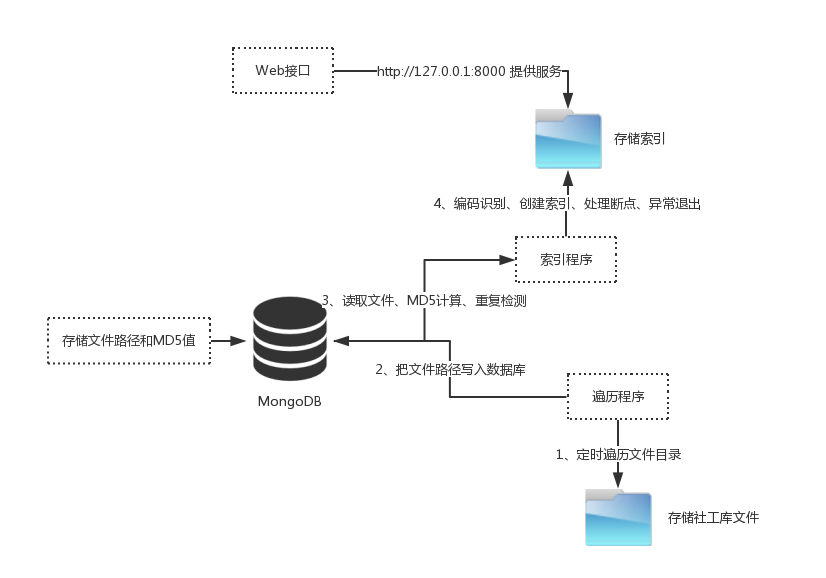
大致思路如下:
1、创建一个MongoDB集合,用来存储文件的路径和MD5值;
2、创建一个配置文件,配置存储泄露数据库的文件夹和索引存储文件夹和断点位置;
3、创建二个文件夹,一个用来存储收集的泄露数据库文件,另一个专门用来存储索引文件。
4、程序每隔几秒遍历一次存储数据库的文件夹,将文件的路径按顺序写到MongoDB中。然后索引程序按顺序从MongoDB中读取文件,计算文件MD5值,比较一下该MD5值在MongoDB中是否存在,存在就跳过这个文件。


5、存储文件的MD5值,检测文件编码,根据文件格式调用不同的索引模块建立索引,分词功能用结巴分词来实现;

6、如果索引过程中出现异常中断或者人为中断索引,记录索引文件在Mongodb中的objectID值和行号;


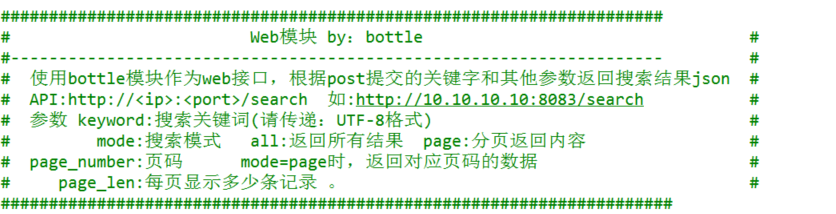
7、创建利用Bottle来创建一个web接口,对外提供搜索服务,搜索时为了优化查询效率,可将@ . – _等分隔符全部替换为空格来做模糊查询;

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

