OpenAI研究负责人:应用于深度学习和自然语言处理的注意机制和记忆模型
深度学习近期的一个趋势是使用注意机制(Attention Mechanism),OpenAI研究负责人Ilya Sutskever在最近的一次采访中提到了注意机制是最令人激动的进步之一,而且它们将就此扎根下来。这听起来令人兴奋不已,但注意机制到底是什么?
神经网络中的注意机制大体是基于从人类视觉中发现的注意机制。对人类视觉注意力的研究较为透彻,目前存在几个不同模型,但归根结底,它们在本质上都是能够聚焦于图像中「高分辨率」的特定区域,同时又可以感知到周围的「低分辨率」区域,然后不断的调整焦点。
注意机制在神经网络中的使用由来已久,特别是用在图像识别中。例如,Hugo Larochelle和Geoffrey E. Hinton于2010年发表的论文《Examples include Learning to combine foveal glimpses with a third-order Boltzmann machine》,以及Misha Denil2011年的论文《Learning where to Attend with Deep Architectures for Image Tracking》。但直到最近,外界才将注意机制应用在一些递归神经网络架构(尤其是用于自然语言处理,对于视觉的应用也在增加)上。这就是本文所关注的重点。
注意机制可以解决哪些问题?
为了更好的理解注意机制的作用,我们以神经机器翻译(NMT)为例。传统的机器翻译系统通常都是依靠复杂的基于文本统计属性的特征工程。简单来说,这些系统非常复杂,建造它们需要在工程上付诸大量努力。神经机器翻译系统的工作原理有些不同,我们会将一个句子的含义映射到一个固定长度的向量表示上,然后基于那个向量再进行翻译。NMT系统不是依赖于文法计数,而是试图获取更加高级的文本含义,这样就可以比其他方法更好的概括出新句子。更加重要的是,NMT系统在建造和训练方面更加容易,它们不需要人工添加特征。事实上,Tensorflow中的一个简单应用已经都不会超过100行代码了。
大多数NMT系统的工作原理是通过递归神经网络将源句子(比如说一句德语)编码成向量,然后同样使用递归神经网络将这个向量解码成一句英语。
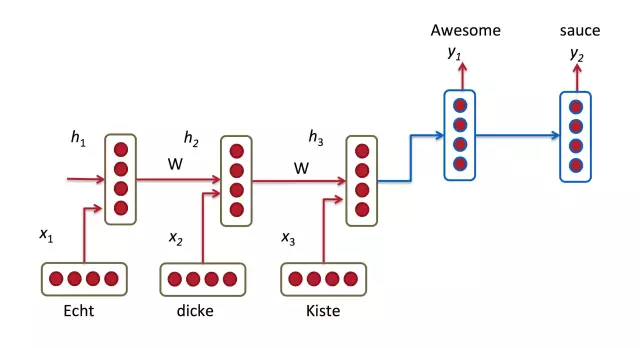
在上图中,单词「Echt」、「Dicke」和「Kiste」被输入进编码器,经过一个特殊的信号(图中未显示)之后,解码器开始生成翻译完成的句子。解码器持续不断的生成词汇,直到遇到一个特殊的代表句子结束的符号。在这里,向量表现出了编码器的内部状态。
如果你看的足够仔细,你会发现,解码器是被用来基于编码器中的最后一个隐状态来单独完成翻译的。这个向量必须将我们所需要了解的源句子的一切都进行编码,它必须能够完全捕捉到句子的含义。用个技术术语来表示,那个向量是在进行句式嵌入(sentence embedding)。事实上,你如果使用PCA或t-SNAE等降维方法将不同句式嵌入绘制出来的话,你会发现最终语义相似的句子会离得比较近。这令人非常惊奇。
上文提到,我们可以将一个非常长的句子的所有信息都编码成单一向量,然后解码器仅基于这个向量就能完成一次很好的翻译,但这个假设看起来还有些不够合理。让我们拿一个由50个单词组成的源句子举例。英语翻译的第一个词可能和源句子的第一个词高度相关。但这意味着解码器不得不考虑50步之前的信息,以及需要在这个向量中进行解码的信息。我们都知道,递归神经网络在处理这类远程依赖性时会遇到问题。理论上来说,类似于长短时记忆模型(LSTMs)的架构应该可以应对这些问题,但事实上远程依赖性依然会存在问题。例如,研究者已经发现,颠倒源句子的顺序(将它逆向输入编码器)能够产生更好的结果,因为这缩短了从解码器到编码器相关部分的路径。同样的,将一个顺序输入两次也可能帮助神经网络更好的进行记忆。
我认为这种颠倒句子顺序的方法属于「hack」。这在实际应用中更有效,但却不是一种从根本上出发的解决方案。大部分翻译基准是基于法语和德语所做出来的,它们和英语比较类似。但在某些语言(例如日语)的英语翻译中,一句话的最后一个词有可能是第一个词的预测因子。在这种情况下,逆向输入就会使结果变的更差。对此,还有什么可选方案?答案就是注意机制。
有了注意机制,我们不再试图将一个完整的源句子编码成一个固定长度的向量。相反,我们在形成输出的每一步都允许解码器「关注」到源句子的不同部分。重要的是,我们会让这个模型基于输入的句子以及到目前为止产生的结果去学习应该「关注」什么。因此,在那些高度一致的语言(例如英语和德语)中,解码器将可能选择按照顺序进行「关注」。如果需要翻译第一个英语单词,就「关注」第一个单词,等等。这就是神经机器翻译中借助于对匹配和翻译的联合学习所获得的成果。

这里,y’是解码器翻译出来的dan ci,x’是源句子的单词。上图用了一个双向的递归网络,但这个不重要,你可以忽视反向部分。重要的部分在于,解码器输出的每一个单词y都依赖于所有输入状态的加权组合,而不仅是最后一个状态。a’是权重,用来定义对于每一个输出值,每个输入状态应该被考虑的程度。因此,如果a(3,2)很大,则意味着解码器在生成目标句子第三个单词的翻译结果时,应该更多的「注意」源句子的第二个状态。
注意力的一大优点是它使我们能够解释和想象出模型的工作状态。例如,当一个句子正在被翻译时,我们可以将注意力权重矩阵进行可视化处理,因此,就能理解这个模型是怎样进行翻译的。

这里我们看到,当从法语翻译成英语时,神经网络按照顺序「关注」了每一个输入状态,但有时它会一次性「关注」两个单词,比如在将「la Syrie」翻译成「Syria」(叙利亚)时。
注意机制的代价
如果我们更仔细地观察注意机制的方程,我们会发现它是有代价的。我们需要结合每个输入和输出的单词来计算注意值。如果你输入50个词,输出50个词,那么注意值将会是2500。这还不算糟,但是如果你做字符级的计算,处理由数以百计的标记组成的序列,那么上述注意机制的代价将变得过于昂贵。
事实上,这是反直觉的。人类的注意力是节省计算资源的。当我们专注于一件事时,会忽略许多其他事。但那不是我们上述模型所真正做的事。在我们决定关注什么之前,必须确定每一个细节。直觉上等效输出一个翻译的单词,要通过所有内在记忆中的文本来决定下一步生成什么单词,这似乎是一种浪费,完全不是人类所擅长的事情。事实上,它更类似于记忆的使用,而不是注意,这在我看来有点用词不当。然而,这并不影响注意机制变得非常流行,而且在许多任务中表现良好。
另一种注意机制的方法是使用强化学习来预测一个需要专注的近似位置。这听起来更像人类的注意力,这就是视觉注意递归模型( Recurrent Models of Visual Attention)所完成的事情。然而,强化学习模型不能用反向传播进行首尾相连的训练,因此它们并不能广泛应用于NLP问题中。
超越机器翻译的注意机制
目前我们看到了注意机制应用于机器翻译中,但它可以用于任意递归模型,让我们看更多的例子。
如图所示,在《Attend and Tell:Neural Image Caption Generation with Visual Attention》论文中,作者使用了注意机制来解决图像描述生成问题。他们用卷积神经网络来「编码」图像,然后用带有注意机制的递归神经网络来生成描述。通过将注意权重可视化,我们来解释一下,模型在生成一个单词时所表现出来的样子:
 在论文《Grammar as a Foreign Language》中,作者用带有注意机制的递归神经网络生成句子分析树。将注意矩阵可视化,可以让我们洞悉神经网络是如何生成这个分析树的:
在论文《Grammar as a Foreign Language》中,作者用带有注意机制的递归神经网络生成句子分析树。将注意矩阵可视化,可以让我们洞悉神经网络是如何生成这个分析树的:
 在论文《Teaching Machines to Read and Comprehend》中,作者使用RNN来阅读文本和(合成的)问题,然后输出答案。通过将注意矩阵可视化,我们能看到,当神经网络试图寻找答案时,它在「看」什么:
在论文《Teaching Machines to Read and Comprehend》中,作者使用RNN来阅读文本和(合成的)问题,然后输出答案。通过将注意矩阵可视化,我们能看到,当神经网络试图寻找答案时,它在「看」什么:

注意力=(模糊的)记忆?
注意机制所解决的基本问题是允许神经网络参考输入序列,而不是专注于将所有信息编码为固定长度的向量。正如我上面提到的,我认为注意力有点用词不当。换句话说,注意机制是简单的让神经网络使用其内部记忆(编码器的隐状态)。在这个解释中,不是选择去「关注」什么,而是让神经网络选择从记忆中检索什么。不同于传统的记忆,这里的记忆访问机制更加灵活,这意味着神经网络根据所有记忆的位置赋予其相应的权重,而不是从单个离散位置得出某个值。让记忆的访问更具灵活性,有助于我们用反向传播对神经网络进行首尾相连的训练(虽然有非模糊的方法,即使用抽样方法来代替反向传播进行梯度计算。)
记忆机制有着更长的历史。标准递归神经网络的隐状态就是一种内部记忆。梯度消失问题使RNNs无法从远程依赖性中进行学习。长短时记忆模型通过使用允许明确记忆删除和更新)改善了上述情况。
形成更加复杂记忆结构的趋势仍在继续。论文《End-to-End Memory Networks》中可以(End-to-End Memory Networks)使神经网络先多次读取相同的输入序列,然后再进行输出,每一个步骤都更新记忆内容。例如,通过对输入内容进行多次推理从而回答某个问题。但是,当神经网络参数的权重以一种特定方式联系在一起时,端对端记忆网络中的记忆机制等同于注意机制,这在记忆中创造了多重跃点(因为它试图从多个句子中集成信息)。
在论文《神经图灵机》中使用了和记忆机制类似的形式,但有着更加复杂的访问类型,后者既使用了基于内容的访问,又使用了基于位置的访问,从而使神经网络可以学习访问模式来执行简单的计算机程序,例如排序算法。
在不久的将来,我们非常有可能看到对记忆和注意机制的更加清晰的区分,它可能会沿着「强化学习神经图灵机」(正试着学习访问模式来处理外部接口)的路线发展下去。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

