由一条报警信息发现的一系列问题
今天看到一条报警短信,提示是某个表空间的问题。
ZABBIX-监控系统:
------------------------------------
报警内容: Tablespace Usage warning
------------------------------------
报警级别: PROBLEM
------------------------------------
监控项目: showtsps:-->TS_NAME:UNDOTBS1 :4.8% Free
------------------------------------
报警时间:2016.01.03-17:02:44
如果出现这种问题,而且是undo表空间的,我们是不是可以直接忽略了,一般情况下还是可以的,但是如果频频出现这种问题,那么还是需要来分析一下,倒底是什么原因。因为服务器归属不是我,我就帮忙看了一下环境,但是查看过程中发现了很多的问题,很多问题还是值得借鉴的。
首先查看表空间的使用情况,目前这个库有近1.5T,undo的设置了一个数据文件,也就意味着空间大小在30G左右,具体处理的业务我不太清楚,但是查看报告的内容来看还是偏OLAP.
那么为什么会在某一个时间段里有大量的undo报警呢,主要原因应该是在这个时间范围内发生了大量的dml,尤其是delete级的操作。
带着疑问,首先查看了归档的情况。可以很清晰的看到在一个小时内归档进行了频繁的切换,大概切换了近300多次。每个日志member大小为200M
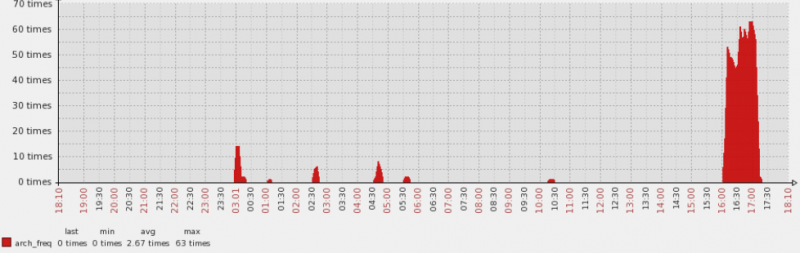
而DB time的情况呢,印象中么有报负载突然暴增的短信报警。
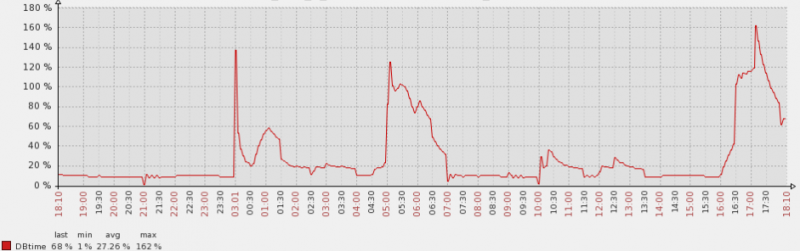
可以看出来,虽然短时间内负载从20%提高到了160%,对于多CPU的服务器而言,这个DB time提升还是不够明显,目前设定的阀值在300%~400%左右。所以没有收到报警。
那么这么看来是在短时间内发生了频繁的dml操作,对于数据库负载而言没有很明显的影响。
然后就查看了一番awr报告。
可以看出redo的生成量还是不少,查看top等待事件,发现近一半多的DB time在DB CPU上,那么剩下的加起来还不到60%,可见还是很可能是sql执行时间过长导致了DB time的计算出现二来一些偏差。
查看top sql的情况如下:
可以看到top1的sql是在做一个scheduler的任务,执行了近一个小时,时间情况和问题情况是相符的。
通过scheduler可以看到正在调用的job
select dbms_metadata.get_ddl('PROCOBJ', 'EVERYDAY_CALL_DAY_BO',SCHEMA=>'QUERY_ORG_TESTS') from dual;
job会中调用一个存储过程,而这个存储过程里面会间接调用若干个子存储过程,所以调用关系看起来还是蛮复杂的。
可以直接查看dba_tab_modifications看到一个概要的信息。
$ sh showtabstat.sh QUERY_ORG_TESTS MONTH_BILL_OUT_BO
*******************************************
OWNER TABLE_NAME
------------------------------ ------------------------------
QUERY_ORG_TESTS MONTH_BILL_OUT_BO
*******************************************
PARTITION_NAME SUBPARTITION_NAME INSERTS UPDATES DELETES CHG_TIMESTAMP TRU DROP_SEGMENTS
-------------------- -------------------- --------- --------- --------- -------------------- --- -------------
300001 0 300000 2016-01-03 17:23:13 NO 0
MONTH_BILL_OUT_BO_DEFAULT 1 0 0 2016-01-03 18:04:56 NO 0
可以看到在今天的时间段内,发生了30万次的insert,30万次的delete操作,可见这种实现方式中还是在做旧数据的删除然后再重新插入数据,逻辑上看起来似乎还是有点问题,看看代码里面是怎么写的吧,里面用到了bulk collect,insert all这样的用法,里面会递归调用大批量的insert values这样的语句,其实这种方式还是不够好,insert select其实可以更快。
然后上面的信息不知道各位还看出什么端倪了吗,操作中设计的表有一个分区为MONTH_BILL_OUT_BO_DEFAULT,这个分区从字面意思来看似乎有些不对劲啊。
查看分区的规则。可以赫然看到最近的一次分区是2014年,也就是前年的分区了,2015年的数据都放在了默认的分区中,看起来还是不太应该啊。
MONTH_BILL_OUT_BO_201412 TO_DATE(' 2014xxxx') MONTH_BILL 1 YES DISABLED YES 04-DEC-14 285585
MONTH_BILL_OUT_BO_DEFAULT MAXVALUE USERS 1 YES DISABLED YES 04-JUL-15 1040915
好了,这个也算是一个问题,那么历史数据能否通过truncate partition清理呢,我查看了一下分区索引的情况,发现索引都是清一色的global index,那么这种方式看来都得重建索引了。又是一个问题。
那么还有什么问题吗?看看数据库日志里面怎么说。可以看到在问题时间段里进行了频繁的日志切换,那么标黑的部分又是一个问题了。
LNS: Standby redo logfile selected for thread 1 sequence 181128 for destination LOG_ARCHIVE_DEST_2
Sun Jan 03 17:08:16 2016
Archived Log entry 287889 added for thread 1 sequence 181127 ID 0x953bfa86 dest 1:
Thread 1 advanced to log sequence 181129 (LGWR switch)
Current log# 4 seq# 181129 mem# 0: /home/app/oracle/oradata/test/redo04.log
LNS: Standby redo logfile selected for thread 1 sequence 181129 for destination LOG_ARCHIVE_DEST_2
Deleted Oracle managed file /U01/app/oracle/oradata/test/arch/testX/archivelog/2016_01_01/o1_mf_1_180672_c8d4j7df_.arc
Deleted Oracle managed file /U01/app/oracle/oradata/test/arch/testX/archivelog/2016_01_01/o1_mf_1_180673_c8ddmy75_.arc
Sun Jan 03 17:08:28 2016
Archived Log entry 287891 added for thread 1 sequence 181128 ID 0x953bfa86 dest 1:
这是11g对于归档的一种保护性清理,在使用闪回区并且大小在80%左右的时候,会开始清理已经应用的归档,那么通过这个日志信息可以看出来其实归档的删除策略也存在一些问题。
那么目前的归档删除策略是什么样的。
CONFIGURE ARCHIVELOG DELETION POLICY TO APPLIED ON ALL STANDBY;
crosscheck archivelog all;
delete noprompt expired archivelog all;
delete noprompt archivelog until time "sysdate-1";
目前是只删除1天以前的归档,那么在今天的情况下,生成了大量的归档,
目前的crontab频率为
50 * * * * (. $HOME/.bash_profile;$HOME/dbadmin/scripts/rman_trun_arch.sh)
也就是每个小时触发一次,那么归档的删除策略是删除一天以前的,短时间内的归档肯定删除不了,这也就涉及一个归档的删除策略的设计方式,归档的删除如果有执行窗口,设定的时间还是要保留一定的延时,其实这种情况在10gR2中比较多,就是因为备库需要在online,read-only之间切换,11gR2不存在这类问题了。
所以这个问题也可以重视一下。
然后再做一个简单的测试,查看备库的ADG是否启用,结果这一次还让我猜中了。
SQL> conn testdba/xxxxx
ERROR:
ORA-01033: ORACLE initialization or shutdown in progress
Process ID: 0
Session ID: 0 Serial number: 0
也就意味着备库在mount,不是read only。原因就在于compatible的参数设置所限。
SQL> show parameter compa
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
compatible string 10.2.0.3.0
看来一个小小的报警信息辐射开来还是能够发现不少的问题来,还是需要多加注意。
ZABBIX-监控系统:
------------------------------------
报警内容: Tablespace Usage warning
------------------------------------
报警级别: PROBLEM
------------------------------------
监控项目: showtsps:-->TS_NAME:UNDOTBS1 :4.8% Free
------------------------------------
报警时间:2016.01.03-17:02:44
如果出现这种问题,而且是undo表空间的,我们是不是可以直接忽略了,一般情况下还是可以的,但是如果频频出现这种问题,那么还是需要来分析一下,倒底是什么原因。因为服务器归属不是我,我就帮忙看了一下环境,但是查看过程中发现了很多的问题,很多问题还是值得借鉴的。
首先查看表空间的使用情况,目前这个库有近1.5T,undo的设置了一个数据文件,也就意味着空间大小在30G左右,具体处理的业务我不太清楚,但是查看报告的内容来看还是偏OLAP.
那么为什么会在某一个时间段里有大量的undo报警呢,主要原因应该是在这个时间范围内发生了大量的dml,尤其是delete级的操作。
带着疑问,首先查看了归档的情况。可以很清晰的看到在一个小时内归档进行了频繁的切换,大概切换了近300多次。每个日志member大小为200M
而DB time的情况呢,印象中么有报负载突然暴增的短信报警。
可以看出来,虽然短时间内负载从20%提高到了160%,对于多CPU的服务器而言,这个DB time提升还是不够明显,目前设定的阀值在300%~400%左右。所以没有收到报警。
那么这么看来是在短时间内发生了频繁的dml操作,对于数据库负载而言没有很明显的影响。
然后就查看了一番awr报告。
| | Per Second | Per Transaction | Per Exec | Per Call |
|---|---|---|---|---|
| DB Time(s): | 1.2 | 1.7 | 0.03 | 0.07 |
| DB CPU(s): | 0.6 | 0.8 | 0.01 | 0.03 |
| Redo size: | 11,675,379.4 | 16,550,679.0 | ||
| Logical reads: | 88,012.5 | 124,764.0 | ||
| Block changes: | 67,547.0 | 95,752.7 | ||
| Physical reads: | 2,804.4 | 3,975.4 | ||
| Physical writes: | 1,236.4 | 1,752.7 | ||
| User calls: | 17.7 | 25.1 |
| Event | Waits | Time(s) | Avg wait (ms) | % DB time | Wait Class |
|---|---|---|---|---|---|
| DB CPU | 2,081 | 48.72 | |||
| db file scattered read | 403,937 | 247 | 1 | 5.78 | User I/O |
| db file sequential read | 40,286 | 159 | 4 | 3.72 | User I/O |
| enq: RO - fast object reuse | 3,259 | 150 | 46 | 3.51 | Application |
| log file switch (checkpoint incomplete) | 295 | 121 | 409 | 2.83 | Configuration |
| Elapsed Time (s) | Executions | | %Total | %CPU | %IO | SQL Id | SQL Module | SQL Text |
|---|---|---|---|---|---|---|---|---|
| 2,334.45 | 1 | | 54.65 | 74.10 | 14.43 | b5mvd0c0n042y | DBMS_SCHEDULER | DECLARE job BINARY_INTEGER := ... |
| 311.81 | 6 | | 7.30 | 48.02 | 63.04 | 8fswm0xac24qw | DBMS_SCHEDULER | SELECT COUNT(DISTINCT CN) FROM... |
| 228.24 | 6 | | 5.34 | 70.22 | 31.59 | bqcq22gdua2c0 | JDBC Thin Client | select total from ( select STA... |
可以看到top1的sql是在做一个scheduler的任务,执行了近一个小时,时间情况和问题情况是相符的。
通过scheduler可以看到正在调用的job
select dbms_metadata.get_ddl('PROCOBJ', 'EVERYDAY_CALL_DAY_BO',SCHEMA=>'QUERY_ORG_TESTS') from dual;
job会中调用一个存储过程,而这个存储过程里面会间接调用若干个子存储过程,所以调用关系看起来还是蛮复杂的。
可以直接查看dba_tab_modifications看到一个概要的信息。
$ sh showtabstat.sh QUERY_ORG_TESTS MONTH_BILL_OUT_BO
*******************************************
OWNER TABLE_NAME
------------------------------ ------------------------------
QUERY_ORG_TESTS MONTH_BILL_OUT_BO
*******************************************
PARTITION_NAME SUBPARTITION_NAME INSERTS UPDATES DELETES CHG_TIMESTAMP TRU DROP_SEGMENTS
-------------------- -------------------- --------- --------- --------- -------------------- --- -------------
300001 0 300000 2016-01-03 17:23:13 NO 0
MONTH_BILL_OUT_BO_DEFAULT 1 0 0 2016-01-03 18:04:56 NO 0
可以看到在今天的时间段内,发生了30万次的insert,30万次的delete操作,可见这种实现方式中还是在做旧数据的删除然后再重新插入数据,逻辑上看起来似乎还是有点问题,看看代码里面是怎么写的吧,里面用到了bulk collect,insert all这样的用法,里面会递归调用大批量的insert values这样的语句,其实这种方式还是不够好,insert select其实可以更快。
然后上面的信息不知道各位还看出什么端倪了吗,操作中设计的表有一个分区为MONTH_BILL_OUT_BO_DEFAULT,这个分区从字面意思来看似乎有些不对劲啊。
查看分区的规则。可以赫然看到最近的一次分区是2014年,也就是前年的分区了,2015年的数据都放在了默认的分区中,看起来还是不太应该啊。
MONTH_BILL_OUT_BO_201412 TO_DATE(' 2014xxxx') MONTH_BILL 1 YES DISABLED YES 04-DEC-14 285585
MONTH_BILL_OUT_BO_DEFAULT MAXVALUE USERS 1 YES DISABLED YES 04-JUL-15 1040915
好了,这个也算是一个问题,那么历史数据能否通过truncate partition清理呢,我查看了一下分区索引的情况,发现索引都是清一色的global index,那么这种方式看来都得重建索引了。又是一个问题。
那么还有什么问题吗?看看数据库日志里面怎么说。可以看到在问题时间段里进行了频繁的日志切换,那么标黑的部分又是一个问题了。
LNS: Standby redo logfile selected for thread 1 sequence 181128 for destination LOG_ARCHIVE_DEST_2
Sun Jan 03 17:08:16 2016
Archived Log entry 287889 added for thread 1 sequence 181127 ID 0x953bfa86 dest 1:
Thread 1 advanced to log sequence 181129 (LGWR switch)
Current log# 4 seq# 181129 mem# 0: /home/app/oracle/oradata/test/redo04.log
LNS: Standby redo logfile selected for thread 1 sequence 181129 for destination LOG_ARCHIVE_DEST_2
Deleted Oracle managed file /U01/app/oracle/oradata/test/arch/testX/archivelog/2016_01_01/o1_mf_1_180672_c8d4j7df_.arc
Deleted Oracle managed file /U01/app/oracle/oradata/test/arch/testX/archivelog/2016_01_01/o1_mf_1_180673_c8ddmy75_.arc
Sun Jan 03 17:08:28 2016
Archived Log entry 287891 added for thread 1 sequence 181128 ID 0x953bfa86 dest 1:
这是11g对于归档的一种保护性清理,在使用闪回区并且大小在80%左右的时候,会开始清理已经应用的归档,那么通过这个日志信息可以看出来其实归档的删除策略也存在一些问题。
那么目前的归档删除策略是什么样的。
CONFIGURE ARCHIVELOG DELETION POLICY TO APPLIED ON ALL STANDBY;
crosscheck archivelog all;
delete noprompt expired archivelog all;
delete noprompt archivelog until time "sysdate-1";
目前是只删除1天以前的归档,那么在今天的情况下,生成了大量的归档,
目前的crontab频率为
50 * * * * (. $HOME/.bash_profile;$HOME/dbadmin/scripts/rman_trun_arch.sh)
也就是每个小时触发一次,那么归档的删除策略是删除一天以前的,短时间内的归档肯定删除不了,这也就涉及一个归档的删除策略的设计方式,归档的删除如果有执行窗口,设定的时间还是要保留一定的延时,其实这种情况在10gR2中比较多,就是因为备库需要在online,read-only之间切换,11gR2不存在这类问题了。
所以这个问题也可以重视一下。
然后再做一个简单的测试,查看备库的ADG是否启用,结果这一次还让我猜中了。
SQL> conn testdba/xxxxx
ERROR:
ORA-01033: ORACLE initialization or shutdown in progress
Process ID: 0
Session ID: 0 Serial number: 0
也就意味着备库在mount,不是read only。原因就在于compatible的参数设置所限。
SQL> show parameter compa
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
compatible string 10.2.0.3.0
看来一个小小的报警信息辐射开来还是能够发现不少的问题来,还是需要多加注意。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

