Apache Kylin在百度地图的实践
1. 前言
百度地图开放平台业务部数据智能组主要负责百度地图内部相关业务的大数据计算分析,处理日常百亿级规模数据,为不同业务提供单条SQL毫秒级响应的OLAP多维分析查询服务。
对于Apache Kylin在实际生产环境中的应用,在国内,百度地图数据智能组是最早的一批实践者之一。Apache Kylin在2014年11月开源,当时,我们团队正需要搭建一套完整的大数据OLAP分析计算平台,用来提供百亿行级数据单条SQL毫秒到秒级的多维分析查询服务,在技术选型过程中,我们参考了Apache Drill、Presto、Impala、Spark SQL、Apache Kylin等。对于Apache Drill和Presto因生产环境案例较少,考虑到后期遇到问题难以交互讨论,且Apache Drill整体发展不够成熟。对于Impala和Spark SQL,主要基于内存计算,对机器资源要求较高,单条SQL能够满足秒级动态查询响应,但交互页面通常含有多条SQL查询请求,在超大规模数据规模下,动态计算亦难以满足要求。后来,我们关注到了基于MapReduce预计算生成Cube并提供低延迟查询的Apache Kylin解决方案,并于2015年2月左右在生产环境完成了Apache Kylin的首次完整部署。
Apache Kylin是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区,并于2015年11月正式毕业成为Apache顶级项目。
2. 大数据多维分析的挑战
我们在Apache Kylin集群上跑了多个Cube测试,结果表明它能够有效解决大数据计算分析的3大痛点问题。
痛点一:百亿级海量数据多维指标动态计算耗时问题,Apache Kylin通过预计算生成Cube结果数据集并存储到HBase的方式解决。
痛点二:复杂条件筛选问题,用户查询时,Apache Kylin利用router查找算法及优化的HBase Coprocessor解决;
痛点三:跨月、季度、年等大时间区间查询问题,对于预计算结果的存储,Apache Kylin利用Cube的Data Segment分区存储管理解决。
这3个痛点的解决,使我们能够在百亿级大数据规模下,且数据模型确定的具体多维分析产品中,达到单条SQL毫秒级响应。因此,我们对Apache Kylin产生了较高的兴趣,大数据计算查询分析的应用中,一个页面通常需要多条SQL查询,假设单条SQL查询需要2秒响应,页面共有5个SQL请求,总共就需要10秒左右,这是不可接受的。而此时,Apache Kylin对于一个页面多条SQL查询响应的优势就尤为突出。
在实践过程中,根据公司不同业务的需求,我们数据智能团队的大数据OLAP平台后台存储与查询引擎采用了由Apache Kylin、Impala及Spark SQL组成,在中小数据规模且分析维度指标较为随机的情况下,平台可提供Impala或Spark SQL服务;在超大规模百亿级行数据的具体产品案例上,因查询性能需求较高,同时具体产品对其需要分析的维度和指标较为明确,我们使用Apache Kylin解决方案。下文将主要介绍Apache Kylin在百度地图内部的实践使用。
3. 大数据OLAP平台系统架构
(点击放大图像)

主要模块
数据接入:主要负责从数据仓库端获取业务所需的最细粒度的事实表数据。
任务管理:主要负责Cube的相关任务的执行、管理等。
任务监控:主要负责Cube任务在执行过程中的状态及相应的操作管理。
集群监控:主要包括Hadoop生态进程的监控及Kylin进程的监控。
集群环境
因业务特殊性,我们并未采用公司内部的Hadoop集群进行计算、存储和查询,而是独立部署一台完整的集群,并独立维护。
集群机器:共4台,1台master(100G内存) + 3台slaves(30G内存)。
软件环境:CDH + Hive + HBase + Kylin 0.71
4. 基于Apache Kylin的二次开发
4.1 数据接入模块二次开发
对于任何一个数据计算处理平台,数据的接入十分关键,就像熟知的Spark,对数据接入也是十分重视。目前,我们的大数据OLAP平台可以支持2种数据源的引入: MySQL数据源及HDFS数据源。在实践中,我们遇到一个问题,假设MySQL及HDFS数据源没有标识表示T-1天的数据已经计算完成的情况下,如何确定T-1天的数据已经准备就绪。对于Hive数据源,查询数据所在Hive Meta的partition是否就绪;对于MySQL,我们目前想到的办法是间隔一定时间循环探测当天数据行数是否变化,如果没有变化,我们基本能够简单认为第T-1天的数据已经由数据仓库计算完毕,接下来就可以触发数据拉取模块逻辑将数据拉取到Master节点的本地文件系统中,根据业务判断是否需要对这些数据细加工,然后,导入到Master的Hive中,触发事实表对应任务涉及到的所有cube,启动MapReduce计算,计算结束后,前端可以刷新访问最新数据。另外,如果到了指定时间,发现数据仓库端的数据仍旧没有准备好,数据接入模块会短信报警给仓库端,并继续循环检测直至指定时刻退出。
(点击放大图像)

数据引入模块
4.2 任务管理模块二次开发
任务管理对于计算型平台服务十分重要,也是我们大数据OLAP多维分析平台的核心扩展工作之一。对于用户而言,Apache Kylin对于Cube的最小存储单位为data segment,类似于Hive的partition,data segment采用左闭右开区间表示,如[2015-11-01,2015-11-02)表示含有2015-11-01这一天的数据。对于Cube数据的管理主要基于data segment粒度,大致分为3种操作: 计算(build)、更新(refresh)、合并(merge)。对于一个具体产品来说,它的数据是需要每天例行计算到cube中,正常例行下,每天会生成1个data segment,但可能会因为数据仓库的任务延迟,2天或多天生成1个segment。随着时间推移,一方面,大量的data segment严重影响了性能,另一方面,这也给管理带来了困难和麻烦。因此,对于1个cube,我们按照1个自然月为1个data segment,清晰且易管理。
假设我们有1个月30天的数据,共23个data segment数据片段,如:[2015-11-01,2015-11-02), [2015-11-02,2015-11-04), [2015-11-04,2015-11-11), [2015-11-11,2015-11-12), [2015-11-12,2015-11-13), 。。。[2015-11-30,2015-12-01)
问题1: 假设因为数据有问题,需要回溯2015-11-01的数据,因为我们能够在cube中找到[2015-11-01,2015-11-02)这样一个data segment,满足这个时间区间,于是,我们可以直接界面操作或者Rest API启动这个data segment的refresh更新操作。
问题2: 假设我们需要回溯2015-11-02到2015-11-03的数据,同理,可以找到一个符合条件的data segment [2015-11-02,2015-11-04),然后refresh更新这个data segment。
问题3: 假设我们需要回溯2015-11-01到2015-11-02的数据,我们找不到直接满足时间区间的data segment。于是我们有2种解决方案,第1种方案是分别依次refresh更新 [2015-11-01,2015-11-02), [2015-11-02,2015-11-04)这2个data segment实现;第2种方案是先合并(merge)[2015-11-01,2015-11-02), (2015-11-02,2015-11-04)这两个data segment,合并后得到[2015-11-01,2015-11-04)这样1个data segment,然后我们再拉取新数据后执行更新操作,即可满足需求。
问题4: 假设我们需要刷新2015-11-01~2015-11-30这1个月的数据,我们在另1套集群上基于Kylin 1.1.1对同一个cube进行测试,如果采用问题3中的第1种方案,我们需要逐步刷新cube的23个data segment,大约耗时17.93min X 30=537分钟; 如果我们采用问题3中的第2种方案, 那么我们只需要将23个data segment合并成[2015-11-01,2015-12-01)这1个data segment,计1次操作。然后再执行1次更新操作,共2次操作即可完成需求,总体上,耗时约83.78分钟,较第1种方法性能上提高很多。
基于上面的问题,目前我们平台对Apache Kylin进行了二次开发,扩展出了任务管理模块。
对于cube的计算(build)操作,假设数据仓库2015-11-29~2015-12-02的数据因故延迟,在2015年12-03天产出了(T-1天的数据),如果不判断处理,就会例行计算生成一个时间区间为[2015-11-29,2015-12-03)的data segment。所以,在每个cube计算前,我们的逻辑会自动检测跨自然月问题,并生成[2015-11-29,2015-12-01)和[2015-12-01,2015-12-03)两个data segment.
对于cube的更新(refresh)操作,我们会采用问题3、问题4中提到的第2种方案,自动合并(merge)data segment后再执行更新refresh操作。因为上面已经保证了不会有跨月data segment的生成,这里的自动合并也不会遇到生成跨自然月的情况。
对于cube的合并(merge)操作,如果每天都自动合并该自然月内前面日期已有的所有data segment,假设我们想回溯更新2015-11-11这一天的数据,那么就需要回溯(2015-11-01,2015-11-12)(因为这个时间区间的data segment每天都被自动合并了),其实,我们没有必要回溯2015-11-01~2015-11-10这10天的数据。所以,对于1个自然月内的cube的数据,在当月,我们先保留了1天1个data segment的碎片状态,因为在当月发现前面某几天数据有问题的概率大,回溯某个data segment小碎片就更加合理及性能更优。对于上个月整个月的数据,在下个月的中上旬时数据已经比较稳定,回溯的概率较小,通常要回溯也是上个月整月的数据。因此,在中上旬整体合并上1个月的数据而不是每天合并更合理。
(点击放大图像)

任务管理模块
4.3 平台监控模块二次开发
4.3.1 任务监控
通常,1个产品对应多个页面,1页面对应1个事实表,1个事实表对应多个cube,那么一个产品通常会包含多个cube,上面提到的cube基于data segment的3种任务状态,很难人为去核查,所以对于任务执行的监控是非常必要的,当任务提交后,每隔一段时间检测一次任务的状态,任务状态中间失败或者最后成功后,则会发送邮件或者短信报警通知用户。
4.3.2 集群监控
由于我们的服务器是团队内部独自部署维护,为了高效监控整套Hadoop集群、Hive,HBase、Kylin的进程状态,以及处理海量临时文件的问题,我们单独开发了监控逻辑模块。一旦集群出现问题,能够第一时间收到报警短信或者邮件。
(点击放大图像)
平台监控模块
4.4 资源隔离二次开发
由于我们以平台方式提供给各个业务线使用,当某个业务线的业务数据计算规模较大,会造成平台现有资源紧张时,我们会根据实际情况,要求业务方提供机器资源,随之而来的就是如何根据业务方提供的机器资源分配对应的计算队列的资源隔离问题。目前,官方的Apache Kylin版本对于整个集群只能使用1个kylin_job_conf.xml, 平台上所有项目的所有Cube的3种操作只能使用同一个队列。于是,我们基于kylin-1.1.1-incubating这个tag的源码做了相关修改,支持了以项目为粒度的资源隔离功能,并提交issue到 https://issues.apache.org/jira/browse/KYLIN-1241 ,方案对于我们平台管理员自身也参与项目开发的应用场景下非常适用。对于某个项目,如果不需要指定特定计算队列,无需在$KYLIN_HOME下指定该项目的kylin_job_conf.xml文件,系统会自动调用官方原有的逻辑,使用默认的Hadoop队列计算。
(点击放大图像)

资源隔离
4.5 Hadoop及HBase优化
因独立部署的Hadoop集群硬件配置不高,内存十分有限,所以,在项目实践过程中也遇到不少问题。
4.5.1 Hadoop任务内存资源不够,cube计算失败
调整MapReduce分配资源参数:在cube计算过程中,会出现mr任务失败,根据日志排查,主要因mr的内存分配不足导致,于是,我们根据任务实际情况整体调整了yarn.nodemanager.resource.memory-mb,mapreduce.map.memory.mb, mapreduce.map.java.opts, mapreduce.reduce.memory.mb及mapreduce.reduce.java.opts等参数。
4.5.2 HBase RegionServer在不同节点随机down掉
由于机器整体资源限制,我们给HBase配置的HBASE_HEAPSIZE值较小,随着时间推移,平台承载的项目越来越多,对内存及计算资源要求也逐步提高。后来平台在运行过程中,HBase的RegionServer在不同节点上出现随机down掉的现象,导致HBase不可用,影响了Kylin的查询服务,这个问题困扰了团队较长时间,通过网上资料及自身的一些经验,我们对HBase和Hadoop相关参数做了较多优化。
A. HBase的JVM GC相关参数调优,开启了HBase的mslab参数:可以通过GC调优获得更好的GC性能,减少单次GC的时间和FULL GC频率;
B. HBase的ZK连接超时相关参数调优:默认的ZK超时设置太短,一旦发生FULL GC,极其容易导致ZK连接超时;
C. ZK Server调优,提高maxSessionTimeout:ZK客户端(比如Hbase的客户端)的ZK超时参数必须在服务端超时参数的范围内,否则ZK客户端设置的超时参数起不到效果;
D. HBASE_OPTS参数调优:开启CMS垃圾回收期,增大了PermSize和MaxPermSize的值;Hadoop及HBase优化
(点击放大图像)
Hadoop及HBase优化
5. Apache Kylin项目实践
5.1 基于仓库端join好的fact事实表建Cube,减少对小规模集群带来的hive join压力
对于Cube的设计,官方有专门的相关文档说明,里面有较多的指导经验,比如: cube的维度最好不要超过15个, 对于cardinality较大的维度放在前面,维度的值不要过大,维度Hierarchy的设置等等。
实践中,我们会将某个产品需求分为多个页面进行开发,每个页面查询主要基于事实表建的cube,每个页面对应多张维度表和1张事实表,维度表放在MySQL端,由数据仓库端统一管理,事实表计算后存放在HDFS中,事实表中不存储维度的名称,仅存储维度的id,主要基于3方面考虑,第一:减少事实表体积;第二:由于我们的Hadoop集群是自己单独部署的小集群,MapReduce计算能力有限,join操作希望在仓库端完成,避免给Kylin集群带来的Hive join等计算压力;第三:减少回溯代价。 假设我们把维度名称也存在Cube中,如果维度名称变化必然导致整个cube的回溯,代价很大。这里可能有人会问,事实表中只有维度id没有维度name,假设我们需要join得到查询结果中含有维度name的记录,怎么办呢?对于某个产品的1个页面,我们查询时传到后台的是维度id,维度id对应的维度name来自MySQL中的维度表,可以将维度name查询出来并和维度id保存为1个维度map待后续使用。同时,一个页面的可视范围有限,查询结果虽然总量很多,但是每一页返回的满足条件的事实表记录结果有限,那么,我们可以通过之前保存的维度map来映射每列id对应的名称,相当于在前端逻辑中完成了传统的id和name的join操作。
5.2 Aggregation cube辅助中高维度指标计算,解决向上汇总计算数据膨胀问题
比如我们的事实表有个detail分区数据,detail分区包含最细粒度os和appversion两个维度的数据(注意: cuid维度的计算在仓库端处理),我们的cube设计也选择os和appversion,hierarchy层次结构上,os是appversion的父亲节点,从os+appversion(group by os, appversion)组合维度来看,统计的用户量没有问题,但是按照os(group by os)单维度统计用户量时,会从基于这个detail分区建立的cube向上汇总计算,设上午用户使用的是android 8.0版本,下午大量用户升级到android 8.1版本,android 8.0组合维度 + android 8.1组合维度向上计算汇总得到os=android(group by os, where os=android)单维度用户,数据会膨胀且数据不准确。因此我们为事实表增加一个agg分区,agg分区包含已经从cuid粒度group by去重后计算好的os单维度结果。这样,当用户请求os维度汇总的情况下,Apache Kylin会根据router算法,计算出符合条件的候选cube集合,并按照权重进行优选级排序(熟悉MicroStrategy等BI产品的同学应该知道这类案例),选择器会选中基于agg分区建立的os单维度agg cube,而不从detail这个分区建立的cube来自底向上从最细粒度往高汇总,从而保证了数据的正确性。
5.3 新增留存类分析,如何更高效更新历史记录?
对应小规模集群,计算资源是非常宝贵的,假设我们对于某个项目的留存分析到了日对1日到日对30日,日对1周到日对4周,日对1月到日对4月,周对1周到周对4周,月对1月到月对4月。那么对于传统的存储方案,我们将遇到问题。
5.3.1 传统方案
假如 今天是2015-12-02 ,我们计算 实际得到的是2015-12-01的数据
(点击放大图像)
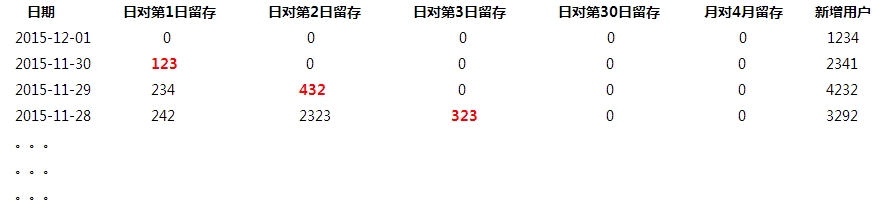
上面数据存储方案的思路是,当今天是2015-12-02,那么2015-12-01可以计算活跃用户了,于是,我们会将2015-11-30的日对第1日留存, 2015-11-29的日对第2日, 2015-11-28的日对第3日等的这些列指标数据进行更新( 如上红色对角线部分 ),这是因为每天数据的每1列都是以当天为基准,等今后第n天到了,再 回填 这1天的这些第x日留存,如此,对于1个任务会级联更新之前的多天历史数据,如上 红色对角线 的数据。
此方案的优势:
a, 如果要查看某个时间范围内的某一个或者多个指标,可以直接根据时间区间,选择需要的列指标即可。
b, 如果要查看某1天的多个指标,也可以直接选择那1天的多个指标即可
此方案的缺点:
a, 每天都需要更新历史数据,如上红色对角线的数据,造成大量MapReduce任务预计算cube,需要较多的机器计算资源支持。
b, 如果今后增加新的留存,比如半年留存,年留存,那么对角线长度就更长,每天就需要回溯更新更多天数的历史数据,需要更多时间跑任务。
c, 对于级联更新的大量的历史数据任务,其实依赖性很强,如何保证留存项目多个cube每一天的多个data segment级联更新正确,非常复杂,难以维护和监控,对于数据仓库端也易遇到如此问题。
d, 对于需要批量回溯一个较大时间区间的历史数据时,问题3中涉及的任务计算难点和困难尤为突出。
5.3.2 变通方案
假如今天是2015-12-02,我们计算实际得到的是2015-12-01的数据(可和上面的结构对比)
(点击放大图像)
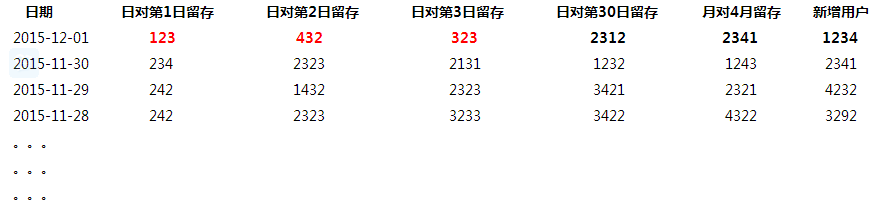
此方案的思路是,当今天是2015-12-02, 实际是2015-12-01的数据 ,如上示例存储, 但日对第n日的留存表示的是n日前对应的那个日期的留存量,相当于旋转了红色对角线。
此方案的优势:
a, 如果要查看某个时间范围内的某1个指标,直接选择该范围的该列指标即可
b, 如果今后增加新的留存,比如半年留存,年留存等指标,不需要级联更新历史天数的数据,只需要更新2015-12-01这1天的数据,时间复杂度O(1)不变,对物理机器资源要求不高。
此方案的缺点:
a, 如果涉及到某1天或者某个时间范围的多列指标查询,需要前端开发留存分析特殊处理逻辑,根据相应的时间窗口滑动,从不同的行,选择不同的列,然后渲染到前端页面。
目前,我们在项目中采用变通的存储方案。
6. 总结
目前,我们大数据OLAP多维分析平台承载百度地图内部多个基于Apache Kylin引擎的亿级多维分析查询项目,共计约80个cube,平均半年时间的历史数据,共计约50亿行的源数据规模,单表最大数据量为20亿+条源数据,满足大时间区间、复杂条件过滤、多维汇总聚合的单条SQL查询毫秒级响应,较为高效地解决了亿级大数据交互查询的性能需求,非常感谢由eBay贡献的Apache Kylin,从预计算和索引的思路为大数据OLAP开源领域提供了一种朴素实用的解决方案,也非常感谢Apache Kylin社区提供的支持和帮助。
作者简介
王冬,百度地图数据智能组成员,北京理工大学计算机本硕毕业,2012加入Microstrategy,负责BI Server核心组件SQL Engine相关开发。并于2014年加入百度地图数据智能组,主要负责大数据OLAP多维分析计算方向研究,热爱大数据离线、实时平台建设应用、Spark生态应用等。
感谢郭蕾对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入InfoQ读者交流群  (已满),InfoQ读者交流群(#2) )。
(已满),InfoQ读者交流群(#2) )。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

