一则备库CPU报警的思考
今天收到一封报警邮件,这引起了我的注意。当然过了一会,有收到了CPU使用率恢复的邮件。
报警邮件内容如下:
报警邮件内容如下:
ZABBIX-监控系统:
------------------------------------
报警内容: Disk I/O is overloaded on ora_statdb2_s_xxx@xxxxx
------------------------------------
报警级别: PROBLEM
------------------------------------
监控项目: CPU iowait time:14.1 %
------------------------------------
报警时间:2016.01.05-03:31:26
看到这封报警邮件,不知道大家作何感想,有什么疑问吗?
首先第一个疑问,为什么备库会报出CPU异常的邮件,到底是什么操作导致。
第二,为什么是备库报警,主库为什么没有报警。
第三,怎么去杜绝或者减少这类报警。
其实对这个问题做了分析,就会发现里面还是有一些治标治本的含义。
首先来逐步分析这个问题,为什么备库会报出CPU异常,这是一个OLAP的数据库,11gR@,CPU使用异常,是否是因为备库在做大量的报表查询?
要想验证这个问题,可以用一个直接了当的sql来说明。
SQL> select username,count(*)from v$session group by username;
USERNAME COUNT(*)
------------------------------ ----------
32
PUBLIC 3
SYS 1
所以其他的设想都不存在,这个库没有其它的应用程序连接,可以简单来说就是在默默接收归档。
那么备库的CPU使用率为什么这么高,我们也可以结合很多原因来看,当然从数据库日志里面也能看出一些端倪来,那就是归档切换频率还是蛮高的。
可以看到网卡的繁忙程度,其实在一个时间段里还是比较集中的。
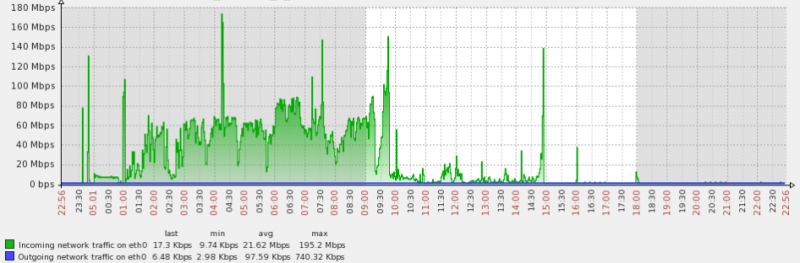
那么就可以从主库来分析一下归档的情况了。
当然我也确实比较懒,能看到图形报告就肯定不愿意多去拿更多的命令去分析了。
主库的归档切换频率如下,可以看到系统在特定的时间段里还是比较繁忙的。
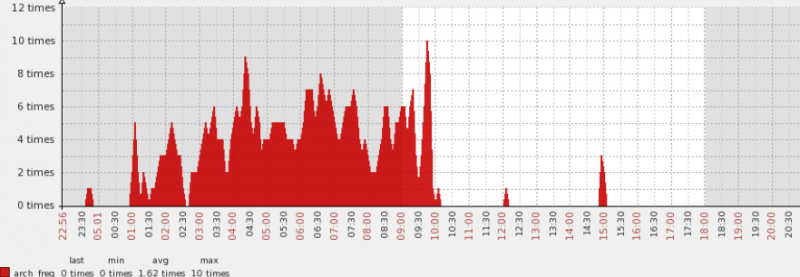
但是话说回来,这是一个OLAP,怎么比OLTP还繁忙。
如果排除系统的原因,那么更多的可能性就是sql语句了。不过还有一个问题需要弄明白,是不是每天都会这样,因为不是每天都收到报警邮件。
我们来看看七天之内的归档情况。可以看到在每天的固定时间段里,归档切换还是比较频繁的,尤其在今天更为明显。
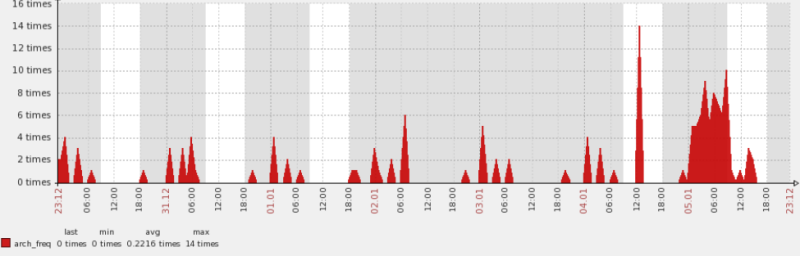
当然这个地方我还要补充一下,图形结果都是片面的,更好的说明还有一个文本的报告。
也是下面的文本报告给我了思路。
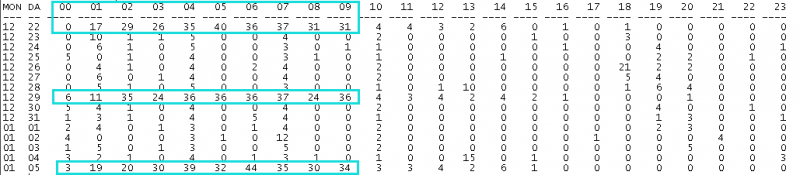
如果仔细看看,发现其实在每周的周二都会有一个时间段产生大量的归档。
如此一来,想必有些朋友应猜出来了,应该是scheduler导致,这个也是我最后定位问题的一个很好的方向。结合一个星期还不够,结合了大半个月的数据才发现了这个规律。
那么可以去查看awr报告看看哪些scheduler在运行。
还是用脚本吧。62033是问题时间段附近的快照号。就得到了下面的sql列表。
$ sh showsnapsql.sh 62033
---------- ------------- ---------------- ---------- ----------
62033 75ubgcf0pdrkr 0 1802s 19%
62033 36s5j5zrztscz 0 1802s 19%
62033 882jz57wm9cj7 0 1802s 19%
62033 gab74zwuduz76 0 1678s 18%
62033 0fhgdzus0hu2t 0 1628s 17%
毫无疑问,这几个里面应该就有我们需要找到的目标,可以看到top 5的sql语句都是执行了近半个小时,executions都为0.所以还是有很大的可能性。
抓取到了几个大查询sql,几个update,当然最重要的就是其中的一个scheduler了。
SQL_FULLTEXT
----------------------------------------------------------------------------------------------------
BEGIN proc_update_cardinfo(); END;
其实top 5中的sql语句都会直接间接在这个scheduler中调用的存储过程中存在。而这个语句的一个核心语句就是下面的形式。
SQL_FULLTEXT
----------------------------------------------------------------------------------------------------
UPDATE TESTINFO A SET A.MAX_LEVEL = NVL((SELECT USER_CLASS FROM ROLE_CLASS_INFO B WHERE A.GROUPID =
B.GROUP_ID AND B.CN_GUID = A.ROLE_GUID), A.MAX_LEVEL) WHERE DRAWED = 'Y'
表里的数据都在亿级,所以全表也会很长时间,消耗也是非常的大。
当然后续就是看看这个语句,还有什么改进的空间,这个还是得和开发的同学好好讨论一下。
然后最后的问题,为什么主库没有这类的报错。
有两个数据可以佐证,那就是主库的内存是132G,备库是32G,主库的CPU是24,而备库是8,相差比较悬殊,也难怪会出现这样的问题。
所以通过备库的CPU报警我们发现备库存在大量的日志切换,然后把注意力很自然转移到主库,发现在特定的时间段里会产生大量的归档,而大量的归档的产生会给备库造成一些系统压力,导致CPU负载过高,但是根本的是为什么主库的归档产生非常多,和主库中的而一个scheduler有关,所以最后的根本就是调优这个scheduler看看,有多大的改进空间。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

