【R】支持向量机模型实现
许多机器学习文章中都提到支持向量机算法的神奇之处。然而,当我用它来处理真实数据以获得较高精度的分类模型时,我偶然发现了几个问题。
本文所提到的模型是基于 R 语言中的包 e1071 所实现的。 首先,你需要安装该软件包并加载之:
install.packages("e1071") library("e1071") 当你处理二分类问题时,SVM 算法的表现非常优异。该方法通过寻找最佳分割线从而将数据分成两个不同的数据集。SVM既可以处理线性分类问题,也可以处理非线性分类问题。其分类器被称为超平面。

变量标准化
在你开始建模前,你需要做的第一件事是:标准化变量数据。SVM 利用这些变量构建分类器从而将数据进行分类,需要注意的是:这些变量越好地刻画你的数据集,你所得到的分类结果将越精确。如果这些变量没有预先被标准化处理,那么绝对值较大的变量将会具有更大的影响力,这意味着某些参数将起主导作用。如果这不是你想要的结果,那么请务必做好数据标准化处理。
参数调整
调整 SVM 算法中的参数也是非常重要的一个步骤,我们需要调整 SVM 算法的参数以获得更优的拟合结果。我们必须明确一点:SVM 算法的表现取决于如何选择最佳参数,即使相当接近的参数值也有可能产生差异巨大的分类结果。因此,为了更好地解决问题,我们需要检验不同参数值下模型的表现情况。R 中有一个非常好的工具—— tune.svm() 。该工具可以利用十折交叉验证法计算不同参数值情况下的分类误差,并返回具有最小分类误差的参数值。
# Example of tune.svm() output: parameters = tune.svm(class~., data = train_set, gamma = 10^(-5:-1), cost = 10^(-3:1)) summary(parameters) Parameter tuning of ‘svm’: - sampling method: 10-fold cross validation - best parameters: gamma cost 0.1 1 - best performance: 0.1409453 - Detailed performance results: gamma cost error dispersion 1 1e-05 0.1 0.2549098 0.010693238 2 1e-04 0.1 0.2548908 0.010689828 3 1e-03 0.1 0.2546062 0.010685683 4 1e-02 0.1 0.2397427 0.010388229 5 1e-01 0.1 0.1776163 0.014591070 6 1e-05 1.0 0.2549043 0.010691266 7 1e-03 1.0 0.2524830 0.010660262 8 1e-02 1.0 0.2262167 0.010391502 9 1e-01 1.0 0.1409453 0.009898745 10 1e-05 10.0 0.2548687 0.010690819 11 1e-04 10.0 0.2545997 0.010686525 12 1e-03 10.0 0.2403118 0.010394169 13 1e-02 10.0 0.1932509 0.009984875 14 1e-01 10.0 0.1529182 0.013780632 参数 gamma 表示超平面的线性平滑度,因此当你使用线性核函数构建 SVM 时,模型中不存在 gamma 参数。我们知道:gamma 越小,超平面越接近于直线,但是如果 gamma 选取过大,超平面将会变得非常弯曲,这会导致过度拟合问题。
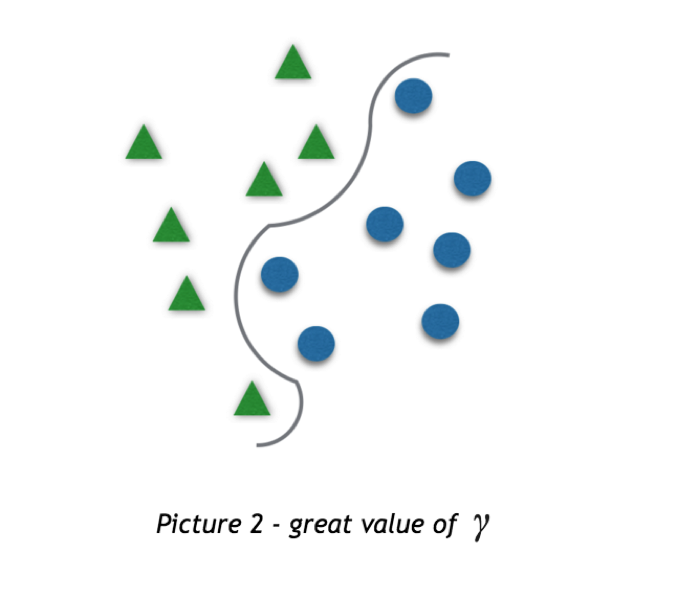
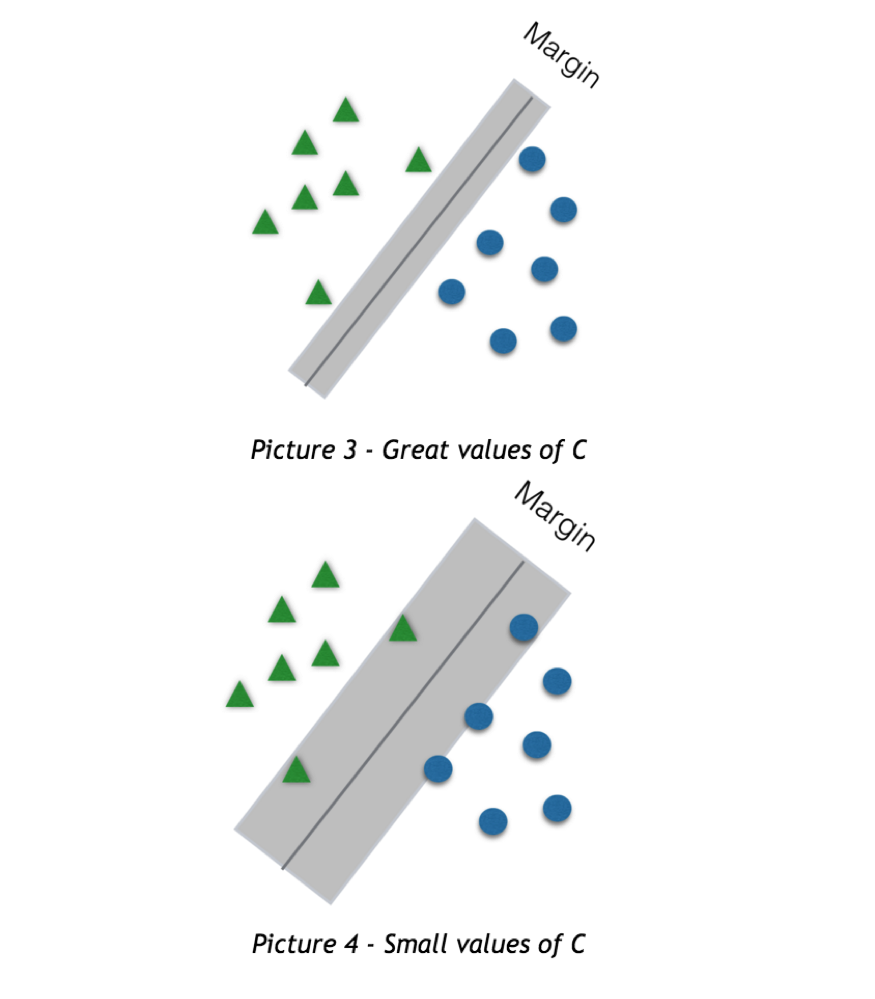
同时,我们还可以调整参数 C 来提高模型精度。参数 C 代表 SVM 模型 soft margin 的规模, soft margin 表示超平面周围的灰色区域面积。这意味着位于 soft margin 区域中的点将没有被分类。其中 C 越小,soft margin 的面积越大。
如何预处理数据
R语言中的 svm() 函数需要输入一个矩阵或者数据框格式的数据,如下表所示:其中包含一个分类变量和其他解释变量。
class f1 f2 f3 1 0 0.100 0.500 0.900 2 0 0.101 0.490 0.901 3 0 0.110 0.540 0.890 4 0 0.100 0.501 0.809 5 1 0.780 0.730 0.090 6 1 0.820 0.790 0.100 7 1 0.870 0.750 0.099 8 1 0.890 0.720 0.089 svm()的输入格式如下所示: svm(class~., data = my_data, kernel = "radial", gamma = 0.1, cost = 1) 其中class表示分类变量,my_data表示数据集。后续的参数值采用上述方法选择最优值。 <img class="cke_anchor" data-cke-realelement="%3Ca%20data-cke-saved-name%3D%22%E6%A3%80%E9%AA%8C%E7%BB%93%E6%9E%9C%22%20name%3D%22%E6%A3%80%E9%AA%8C%E7%BB%93%E6%9E%9C%22%3E%3C%2Fa%3E" data-cke-real-node-type="1" alt="锚点" title="锚点" align="" src="http://datartisan.com/packages/frozennode/administrator/js/ckeditor/plugins/fakeobjects/images/spacer.gif?t=E1QC" data-cke-real-element-type="anchor">检验结果 常见做法是将数据集分成训练集和测试集,其比例为2:1。利用测试集来计算拟合误差。 # 切分数据 data_index = 1:nrow(my_data) testindex = sample(data_index, trunc(length(data_index)*30/100)) test_set = my_data[testindex,] train_set = my_data[-testindex,] # 拟合模型 my_model = svm(class~., data = train_set, kernel = "radial", gamma = 0.1, cost = 1) # 预测结果 # test[,-1] 表示剔除class变量 my_prediction = predict(my_model, test_set[,-1]) 注意事项
-
tune.svm() 需要运行一定的时间,具体取决于数据集的大小。但是不管怎么说,这个过程是非常有意义的。
-
SVM 模型的参数优化过程中,我们通常取对数间隔值,从10^-6到10^6。 注释
3.如果你的标识变量是数值型变量(如本文中的 0-1 变量),那么你的预测结果将会是一个数值,该数值反映了测试集输出结果和某个类别之间相近程度。如果你想要得到原始的分类结果,你需要在 svm() 中设置 type = C-classification。
4.如果你的数据集的样本个数小于 10,此时你运行 tune.svm() 会出错:
Error in tune("svm", train.x = x, data = data, ranges = ranges, ...) : ‘cross’ must not exceed sampling size! 因此,利用 SVM 建模分析时要确保你的数据集足够大。
原文作者:Renata Ghisloti Duarte de Souza
原文链接: http://girlincomputerscience.blogspot.com/2015/02/svm-in-practice.html
译者:Fibears
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

