《深入理解Spark:核心思想与源码分析》(前言及第1章)
自己牺牲了7个月的周末和下班空闲时间,通过研究Spark源码和原理,总结整理的《深入理解Spark:核心思想与源码分析》一书现在已经正式出版上市,目前亚马逊、京东、当当、天猫等网站均有销售,欢迎感兴趣的同学购买。

京东: http://item.jd.com/11846120.html
当当: http://product.dangdang.com/23838168.html
天猫: https://detail.tmall.com/item.htm?spm=a220m.1000858.1000725.1.7A0Q7O&id=525738928528&areaId=131000&cat_id=2&rn=11dc74780fc5d8a25b7b09e3d932fe5f&standard=1&user_id=217042976&is_b=1
亚马逊: http://www.amazon.cn/gp/product/B01A5G5LHK/sr=8-1/qid=1452505597/ref=olp_product_details?ie=UTF8&me=&qid=1452505597&sr=8-1
为了让大家对本书有个大致了解,这里将本书的前言及第一章的内容附上:
前言
为什么写这本书
要回答这个问题,需要从我个人的经历说起。说来惭愧,我第一次接触计算机是在高三。当时跟大家一起去网吧玩CS,跟身边的同学学怎么“玩”。正是通过这种“玩”的过程,让我了解到计算机并没有那么神秘,它也只是台机器,用起来似乎并不比打开电视机复制多少。高考填志愿的时候,凭着直觉“糊里糊涂”就选择了计算机专业。等到真正学习计算机课程的时候却又发现,它其实很难!
早在2004年,还在学校的我跟很多同学一样,喜欢看Flash,也喜欢谈论Flash甚至做Flash。感觉Flash正如它的名字那样“闪光”。那些年,在学校里,知道Flash的人可要比知道Java的人多得多,这说明当时的Flash十分火热。此外Oracle也成为关系型数据库里的领军人物,很多人甚至觉得懂Oracle要比懂Flash、Java及其它数据库要厉害得多!
2007年,笔者刚刚参加工作不久。那时Struts1、Spring、Hibernate几乎可以称为那些用Java作为开发语言的软件公司的三驾马车。很快随着Struts2的诞生,很快替代了Struts1的地位,让我第一次意识到IT领域的技术更新竟然如此之快!随着很多传统软件公司向互联网公司转型,更让人吃惊的是,当初那个勇于技术更新的年轻人Gavin King,也许很难想象他创造的Hibernate也难以确保其地位,iBATIS诞生了!
2010年,有关Hadoop的技术图书涌入中国,当时很多公司用它只是为了数据统计、数据挖掘或者搜索。一开始,人们对于Hadoop的认识和使用可能相对有限。大约2011年的时候,关于云计算的概念在网上吵得火热,当时依然在做互联网开发的我,对其只是“道听途说”。后来跟同事借了一本有关云计算的书,回家挑着看了一些内容,之后什么也没有弄到手,怅然若失!上世纪60年代,美国的军用网络作为互联网的雏形,很多内容已经与云计算中的某些说法相类似。到上世纪80年代,互联网就已经开启了云计算,为什么如今又要重提这样的概念?这个问题笔者可能回答不了,还是交给历史吧。
2012年,国内又呈现出大数据热的态势。从国家到媒体、教育、IT等几乎所有领域,人人都在谈大数据。我的亲戚朋友中,无论老师、销售还是工程师们都可以对大数据谈谈自己的看法。我也找来一些Hadoop的书籍进行学习,希望能在其中探索到大数据的味道。
有幸在工作过程中接触到阿里的开放数据处理服务(Open Data Processing Service, 简称ODPS),并且基于ODPS与其他小伙伴一起构建阿里的大数据商业解决方案——御膳房。去杭州出差的过程中,有幸认识和仲,跟他学习了阿里的实时多维分析平台——Garuda和实时计算平台——Galaxy的部分知识。和仲推荐我阅读Spark的源码,这样会对实时计算及流式计算有更深入的了解。2015年春节期间,自己初次上网查阅Spark的相关资料学习,开始研究Spark源码。还记得那时只是出于对大数据的热爱,想使自己在这方面的技术能力有所提升。
从阅读Hibernate源码开始,到后来阅读Tomcat、Spring的源码,随着挖掘源码,从学习源码的过程中成长,我对源码阅读也越来越感兴趣。随着对Spark源码阅读的深入,发现很多内容从网上找不到答案,只能自己硬啃了。随着自己的积累越来越多,突然有天发现,我所总结的这些内容好像可以写成一本书了!从闪光(Flash)到火花(Saprk),足足有11个年头了。无论是Flash、Java,还是Spring、iBATIS我一直扮演着一个追随者,我接受这些书籍的洗礼,从未给予。如今我也是Spark的追随者,不同的是,我不再只想简单的攫取,还要给予。
最后还想说下2016年是我从事IT工作的第十个年头,此书特别作为送给自己的十周年礼物。
本书的主要特色
- 按照源码分析的习惯设计,从脚本分析到初始化再到核心内容,最后介绍Spark的扩展内容。整个过程遵循由浅入深,由深到广的基本思路。
- 本书涉及的所有内容都有相应的例子,以便于对源码的深入研究能有更好的理解。
- 本书尽可能的用图来展示原理,加速读者对内容的掌握。
- 本书讲解的很多实现及原理都值得借鉴,能帮助读者提升架构设计、程序设计等方面的能力。
- 本书尽可能保留较多的源码,以便于初学者能够在脱离办公环境的地方(如地铁、公交),也能轻松阅读。
本书面向的读者
源码阅读是一项苦差事,人力和时间成本都很高,尤其是对于Spark陌生或者刚刚开始学习的人来说,难度可想而知。本书尽可能保留源码,使得分析过程不至于产生跳跃感,目的是降低大多数人的学习门槛。如果你是从事IT工作1~3年的新人或者希望开始学习Spark核心知识的人来说,本书非常适合你。如果你已经对Spark有所了解或者已经使用它,还想进一步提高自己,那么本书更适合你。
如果你是一个开发新手,对Java、Linux等基础知识不是很了解的话,本书可能不太适合你。如果你已经对Spark有深入的研究,本书也许可以作为你的参考资料。 总体说来,本书适合以下人群:
- 想要使用Spark,但对Spark实现原理不了解,不知道怎么学习的人;
- 大数据技术爱好者,以及想深入了解Spark技术内部实现细节的人;
- 有一定Spark使用基础,但是不了解Spark技术内部实现细节的人;
- 对性能优化和部署方案感兴趣的大型互联网工程师和架构师;
- 开源代码爱好者,喜欢研究源码的同学可以从本书学到一些阅读源码的方式方法。
本书不会教你如何开发Spark应用程序,只是拿一些经典例子演示。本书会简单介绍Hadoop MapReduce、Hadoop YARN、Mesos、Tachyon、ZooKeeper、HDFS、Amazon S3,但不会过多介绍这些等框架的使用,因为市场上已经有丰富的这类书籍供读者挑选。本书也不会过多介绍Scala、Java、Shell的语法,读者可以在市场上选择适合自己的书籍阅读。本书实际适合那些想要破解一个个潘多拉魔盒的人!
如何阅读本书
本书分为三大部分(不包括附录):
第一部分为准备篇(第1 ~ 2章),简单介绍了Spark的环境搭建和基本原理,帮助读者了解一些背景知识。
第二部分为核心设计篇(第3 ~ 7章),着重讲解SparkContext的初始化、存储体系、任务提交与执行、计算引擎及部署模式的原理和源码分析。
第三部分为扩展篇(第8 ~ 11章),主要讲解基于Spark核心的各种扩展及应用,包括:SQL处理引擎、Hive处理、流式计算框架Spark Streaming、图计算框架GraphX、机器学习库MLlib等内容。
本书最后还添加了几个附录,包括:附录A介绍的Spark中最常用的工具类Utils;附录B是Akka的简介与工具类AkkaUtils的介绍;附录C为Jetty的简介和工具类JettyUtils的介绍;附录D为Metrics库的简介和测量容器MetricRegistry的介绍;附录E演示了Hadoop1.0版本中的word count例子;附录F 介绍了工具类CommandUtils的常用方法;附录G是关于Netty的简介和工具类NettyUtils的介绍;附录H列举了笔者编译Spark源码时遇到的问题及解决办法。
为了降低读者阅读理解Spark源码的门槛,本书尽可能保留源码实现,希望读者能够怀着一颗好奇的心,Spark当前很火热,其版本更新也很快,本书以Spark 1.2.3版本为主,有兴趣的读者也可按照本书的方式,阅读Spark的最新源码。
联系方式
本书内容很多,限于笔者水平有限,书中内容难免有错误之处。在本书出版的任何时间,如果你对本书有任何问题或者意见都可以通过邮箱beliefer@163.com或者博客 http://www.cnblogs.com/jiaan-geng/ 联系我,给我提交你的建议或者想法,我本人将怀着一颗谦卑之心与大家共同进步。
致谢
感谢苍天,让我生活在这样一个时代接触互联网和大数据;感谢父母,这么多年来,在学习、工作及生活上的帮助与支持;感谢妻子在生活中的照顾和谦让。
感谢杨福川编辑和高婧雅编辑给予本书出版的大力支持与帮助。
感谢冰夷老大和王贲老大让我有幸加入阿里,接触大数据应用;感谢和仲对Galaxy和Garuda耐心细致的讲解以及对Spark的推荐;感谢张中在百忙之中给本书写评语;感谢周亮、澄苍、民瞻、石申、清无、少侠、征宇、三步、谢衣、晓五、法星、曦轩、九翎、峰阅、丁卯、阿末、紫丞、海炎、涵康、云飏、孟天、零一、六仙、大知、井凡、隆君、太奇、晨炫、既望、宝升、都灵、鬼厉、归钟、梓撤、昊苍、水村、惜冰、惜陌、元乾等同学在工作上的支持和帮助。
耿嘉安
北京
第1章 环境准备
“凡事豫则立,不豫则废;言前定,则不跲;事前定,则不困;”
——《礼记·中庸》
本章导读:
在深入了解一个系统的原理、实现细节之前,应当先准备好它的源码编译环境、运行环境。如果能在实际环境安装和运行Spark,显然能够提升读者对于Spark的一些感受,对系统能有个大体的印象,有经验的技术人员甚至能够猜出一些Spark采用的编程模型、部署模式等。当你通过一些途径知道了系统的原理之后,难道不会问问自己?这是怎么做到的。如果只是游走于系统使用、原理了解的层面,是永远不可能真正理解整个系统的。很多IDE本身带有调试的功能,每当你阅读源码,陷入重围时,调试能让我们更加理解运行期的系统。如果没有调试功能,不敢想象阅读源码的困难。
本章的主要目的是帮助读者构建源码学习环境,主要包括以下内容:
- 在windows环境下搭建源码阅读环境;
- 在Linux搭建基本的执行环境;
- Spark的基本使用,如spark-shell。
1.1 运行环境准备
考虑到大部分公司在开发和生成环境都采用Linux操作系统,所以笔者选用了64位的Linux。在正式安装Spark之前,先要找台好机器。为什么?因为笔者在安装、编译、调试的过程中发现Spark非常耗费内存,如果机器配置太低,恐怕会跑不起来。Spark的开发语言是Scala,而Scala需要运行在JVM之上,因而搭建Spark的运行环境应该包括JDK和Scala。
1.1.1 安装JDK
使用命令getconf LONG_BIT查看linux机器是32位还是64位,然后下载相应版本的JDK并安装。
下载地址:
http://www.oracle.com/technetwork/java/javase/downloads/index.html 。
配置环境:
cd ~ vim .bash_profile
添加如下配置:
export JAVA_HOME=/opt/java export PATH=$PATH:$JAVA_HOME/bin export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
由于笔者的机器上已经安装过openjdk,安装命令:
$ su -c "yum install java-1.7.0-openjdk"
安装完毕后,使用java –version命令查看,确认安装正常,如图1-1所示。

图1-1 查看java安装是否正常
1.1.2 安装Scala
下载地址: http://www.scala-lang.org/download/
选择最新的Scala版本下载,下载方法如下:
wget http://downloads.typesafe.com/scala/2.11.5/scala-2.11.5.tgz
移动到选好的安装目录,例如:
mv scala-2.11.5.tgz ~/install/
进入安装目录,执行以下命令:
chmod 755 scala-2.11.5.tgz tar -xzvf scala-2.11.5.tgz
配置环境:
cd ~ vim .bash_profile
添加如下配置:
export SCALA_HOME=$HOME/install/scala-2.11.5 export PATH=$PATH:$SCALA_HOME/bin:$HOME/bin
安装完毕后键入scala,进入scala命令行,如图1-2所示。

图1-2 进入Scala命令行
1.1.3安装Spark
下载地址: http://spark.apache.org/downloads.html
选择最新的Spark版本下载,下载方法如下:
wget http://archive.apache.org/dist/spark/spark-1.2.0/spark-1.2.0-bin-hadoop1.tgz
移动到选好的安装目录,如:
mv spark-1.2.0-bin-hadoop1.tgz~/install/
进入安装目录,执行以下命令:
chmod 755 spark-1.2.0-bin-hadoop1.tgz tar -xzvf spark-1.2.0-bin-hadoop1.tgz
配置环境:
cd ~ vim .bash_profile
添加如下配置:
export SPARK_HOME=$HOME/install/spark-1.2.0-bin-hadoop1
1.2 Spark初体验
本节通过Spark的基本使用,让读者对Spark能有初步的认识,便于引导读者逐步深入学习。
1.2.1 运行spark-shell
要运行spark-shell,需要先对Spark进行配置。
进入Spark的conf文件夹:
cd ~/install/spark-1.2.0-bin-hadoop1/conf
拷贝一份spark-env.sh.template,命名为spark-env.sh,对它进行编辑,命令如下:
cp spark-env.sh.template spark-env.sh vim spark-env.sh
添加如下配置:
export SPARK_MASTER_IP=127.0.0.1 export SPARK_LOCAL_IP=127.0.0.1
启动spark-shell:
cd ~/install/spark-1.2.0-bin-hadoop1/bin ./spark-shell
最后我们会看到spark启动的过程,如图1-3所示:
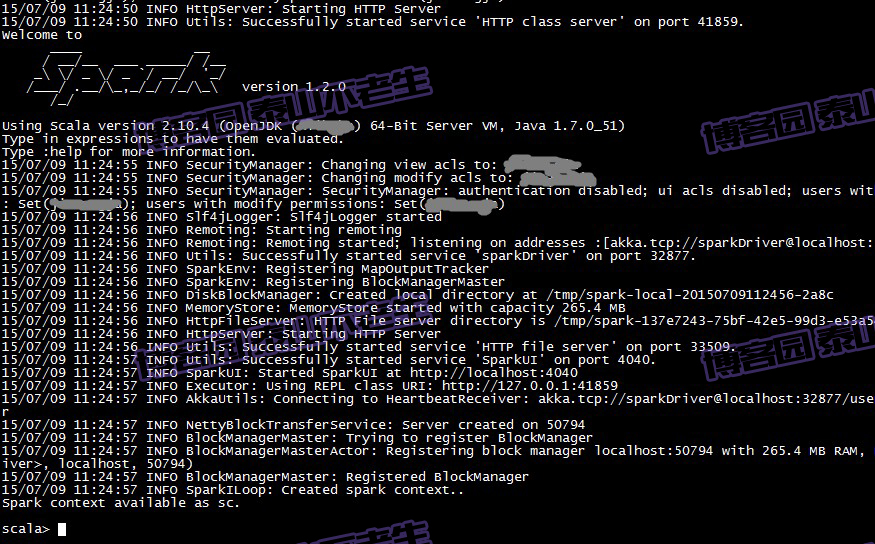
图1-3 Spark启动过程
从以上启动日志中我们可以看到SparkEnv、MapOutputTracker、BlockManagerMaster、DiskBlockManager、MemoryStore、HttpFileServer、SparkUI等信息。它们是做什么的?此处望文生义即可,具体内容将在后边的章节详细给出。
1.2.2 执行word count
这一节,我们通过word count这个耳熟能详的例子来感受下Spark任务的执行过程。启动spark-shell后,会打开Scala命令行,然后按照以下步骤输入脚本:
步骤1 输入val lines = sc.textFile("../README.md", 2),执行结果如图1-4所示。

图1-4 步骤1执行结果
步骤2 输入val words = lines.flatMap(line => line.split(" ")),执行结果如图1-5所示。

图1-5 步骤2执行结果
步骤3 输入val ones = words.map(w => (w,1)),执行结果如图1-6所示。

图1-6 步骤3执行结果
步骤4 输入val counts = ones.reduceByKey(_ + _),执行结果如图1-7所示。

图1-7 步骤4执行结果
步骤5 输入counts.foreach(println),任务执行过程如图1-8和图1-9所示。输出结果如图1-10所示。

图1-8 步骤5执行过程部分

图1-9 步骤5执行过程部分

图1-10 步骤5输出结果
在这些输出日志中,我们先是看到Spark中任务的提交与执行过程,然后看到单词计数的输出结果,最后打印一些任务结束的日志信息。有关任务的执行分析,笔者将在第5章中展开。
1.2.3 剖析spark-shell
通过word count在spark-shell中执行的过程,我们想看看spark-shell做了什么?spark-shell中有以下一段脚本,见代码清单1-1。
代码清单1-1 spark-shell
function main() { if $cygwin; then stty -icanonmin 1 -echo > /dev/null 2>&1 export SPARK_SUBMIT_OPTS="$SPARK_SUBMIT_OPTS -Djline.terminal=unix" "$FWDIR"/bin/spark-submit --class org.apache.spark.repl.Main "${SUBMISSION_OPTS[@]}" spark-shell "${APPLICATION_OPTS[@]}" sttyicanon echo > /dev/null 2>&1 else export SPARK_SUBMIT_OPTS "$FWDIR"/bin/spark-submit --class org.apache.spark.repl.Main "${SUBMISSION_OPTS[@]}" spark-shell "${APPLICATION_OPTS[@]}" fi } 我们看到脚本spark-shell里执行了spark-submit脚本,那么打开spark-submit脚本,发现其中包含以下脚本。
exec "$SPARK_HOME"/bin/spark-class org.apache.spark.deploy.SparkSubmit "${ORIG_ARGS[@]}" 脚本spark-submit在执行spark-class脚本时,给它增加了参数SparkSubmit 。打开spark-class脚本,其中包含以下脚本,见代码清单1-2。
代码清单1-2 spark-class
if [ -n "${JAVA_HOME}" ]; then RUNNER="${JAVA_HOME}/bin/java" else if [ `command -v java` ]; then RUNNER="java" else echo "JAVA_HOME is not set" >&2 exit 1 fi fi exec "$RUNNER" -cp "$CLASSPATH" $JAVA_OPTS "$@" 读到这,应该知道Spark启动了以SparkSubmit为主类的jvm进程。
为便于在本地能够对Spark进程使用远程监控,给spark-class脚本增加追加以下jmx配置:
JAVA_OPTS="-XX:MaxPermSize=128m $OUR_JAVA_OPTS -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=10207 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false"
在本地打开jvisualvm,添加远程主机,如图1-11所示:
图1-11 添加远程主机
右键单击已添加的远程主机,添加JMX连接,如图1-12:
图1-12添加JMX连接
选择右侧的“线程”选项卡,选择main线程,然后点击“线程Dump”按钮,如图1-13。

图1-13查看Spark线程
从dump的内容中找到线程main的信息如代码清单1-3所示。
代码清单1-3 main线程dump信息
"main" - Thread t@1 java.lang.Thread.State: RUNNABLE at java.io.FileInputStream.read0(Native Method) at java.io.FileInputStream.read(FileInputStream.java:210) at scala.tools.jline.TerminalSupport.readCharacter(TerminalSupport.java:152) at scala.tools.jline.UnixTerminal.readVirtualKey(UnixTerminal.java:125) at scala.tools.jline.console.ConsoleReader.readVirtualKey(ConsoleReader.java:933) at scala.tools.jline.console.ConsoleReader.readBinding(ConsoleReader.java:1136) at scala.tools.jline.console.ConsoleReader.readLine(ConsoleReader.java:1218) at scala.tools.jline.console.ConsoleReader.readLine(ConsoleReader.java:1170) at org.apache.spark.repl.SparkJLineReader.readOneLine(SparkJLineReader.scala:80) at scala.tools.nsc.interpreter.InteractiveReader$class.readLine(InteractiveReader.scala:43) at org.apache.spark.repl.SparkJLineReader.readLine(SparkJLineReader.scala:25) at org.apache.spark.repl.SparkILoop.readOneLine$1(SparkILoop.scala:619) at org.apache.spark.repl.SparkILoop.innerLoop$1(SparkILoop.scala:636) at org.apache.spark.repl.SparkILoop.loop(SparkILoop.scala:641) at org.apache.spark.repl.SparkILoop$$anonfun$process$1.apply$mcZ$sp(SparkILoop.scala:968) at org.apache.spark.repl.SparkILoop$$anonfun$process$1.apply(SparkILoop.scala:916) at org.apache.spark.repl.SparkILoop$$anonfun$process$1.apply(SparkILoop.scala:916) at scala.tools.nsc.util.ScalaClassLoader$.savingContextLoader(ScalaClassLoader.scala:135) at org.apache.spark.repl.SparkILoop.process(SparkILoop.scala:916) at org.apache.spark.repl.SparkILoop.process(SparkILoop.scala:1011) at org.apache.spark.repl.Main$.main(Main.scala:31) at org.apache.spark.repl.Main.main(Main.scala) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.spark.deploy.SparkSubmit$.launch(SparkSubmit.scala:358) at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:75) at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
从main线程的栈信息中看出程序的调用顺序:SparkSubmit.main→repl.Main→SparkILoop.process。SparkILoop.process方法中会调用initializeSpark方法,initializeSpark的实现见代码清单1-4。
代码清单1-4 initializeSpark的实现
def initializeSpark() { intp.beQuietDuring { command(""" @transient val sc = { val _sc = org.apache.spark.repl.Main.interp.createSparkContext() println("Spark context available as sc.") _sc } """) command("import org.apache.spark.SparkContext._") } } 我们看到initializeSpark调用了createSparkContext方法,createSparkContext的实现,见代码清单1-5。
代码清单1-5 createSparkContext的实现
def createSparkContext(): SparkContext = { val execUri = System.getenv("SPARK_EXECUTOR_URI") val jars = SparkILoop.getAddedJars val conf = new SparkConf() .setMaster(getMaster()) .setAppName("Spark shell") .setJars(jars) .set("spark.repl.class.uri", intp.classServer.uri) if (execUri != null) { conf.set("spark.executor.uri", execUri) } sparkContext = new SparkContext(conf) logInfo("Created spark context..") sparkContext } 这里最终使用SparkConf和SparkContext来完成初始化,具体内容将在“第3章SparkContext的初始化”讲解。代码分析中涉及的repl主要用于与Spark实时交互。
1.3 阅读环境准备
准备Spark阅读环境,同样需要一台好机器。笔者调试源码的机器的内存是8GB。源码阅读的前提是首先在IDE环境中打包、编译通过。常用的IDE有 IntelliJ IDEA、Eclipse,笔者选择用Eclipse编译Spark,原因有二:一是由于使用多年对它比较熟悉,二是社区中使用Eclipse编译Spark的资料太少,在这里可以做个补充。笔者在windows系统编译Spark源码,除了安装JDK外,还需要安装以下工具。
(1)安装Scala
由于Spark 1.20版本的sbt里指定的Scala版本是2.10.4,具体见Spark源码目录下的文件/project/plugins.sbt中,有一行:scalaVersion := "2.10.4"。所以选择下载scala-2.10.4.msi,下载地址:http://www.scala-lang.org/download/
下载完毕,安装scala-2.10.4.msi。
(2)安装SBT
由于Scala使用SBT作为构建工具,所以需要下载SBT。下载地址: http://www.scala-sbt.org/ ,下载最新的安装包sbt-0.13.8.msi并安装。
(3)安装Git Bash
由于Spark源码使用Git作为版本控制工具,所以需要下载Git的客户端工具,笔者推荐使用Git Bash,因为它更符合Linux下的操作习惯。下载地址:http://msysgit.github.io/,下载最新的版本并安装。
(4)安装Eclipse Scala IDE插件
Eclipse通过强大的插件方式支持各种IDE工具的集成,要在Eclipse中编译、调试、运行Scala程序,就需要安装Eclipse Scala IDE插件。下载地址: http://scala-ide.org/download/current.html 。
由于笔者本地的Eclipse版本是Eclipse 4.4 (Luna),所以我选择安装插件 http://download.scala-ide.org/sdk/lithium/e44/scala211/stable/site ,如图1-14:

图1-14 Eclipse Scala IDE插件安装地址
在Eclipse中选择“Help”菜单,然后选择“Install New Software…”选项,打开Install对话框,如图1-15所示:
图1-15 安装Scala IDE插件
点击“Add…”按钮,打开“Add Repository”对话框,输入插件地址,如1-16图所示:

图1-16 添加Scala IDE插件地址
全选插件的内容,完成安装,如图1-17所示:

图1-17 安装Scala IDE插件
1.4 Spark源码编译与调试
1.下载Spark源码
首先,访问Spark官网http://spark.apache.org/,如图1-18所示:

图1-18Spark官网
点击“Download Spark”按钮,在下一个页面找到git地址,如图1-19所示:

图1-19 Spark官方git地址
打开Git Bash工具,输入git clone git://github.com/apache/spark.git命令将源码下载到本地,如1-20图所示:

图1-20下载Spark源码
2.构建Scala应用
使用cmd命令行进到Spark根目录,执行sbt命令。会下载和解析很多jar包,要等很长的时间,笔者大概花费了一个多小时,才执行完。
3.使用sbt生成eclipse工程文件
等sbt提升符>出现后,输入eclipse命令,开始生成eclipse工程文件,也需要花费很长的时间,笔者本地大致花费了40分钟。完成时的状况,如图1-21所示:

图1-21 sbt编译过程
现在我们查看Spark下的子文件夹,发现其中都生成了.project和.classpath文件。比如mllib项目下就生成了.project和.classpath文件,如图1-22所示:
图1-22sbt生成的项目文件
4.编译Spark源码
由于Spark使用Maven作为项目管理工具,所以需要将Spark项目作为Maven项目导入到Eclipse中,如1-23图所示:
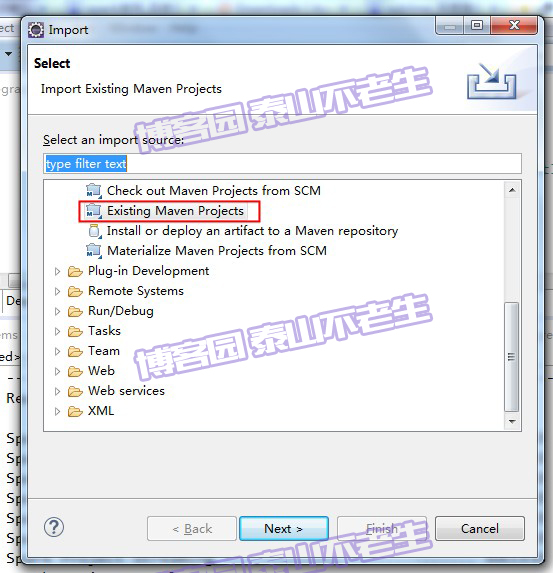
图1-23 导入Maven项目
点击Next按钮进入下一个对话框,如图1-24所示:
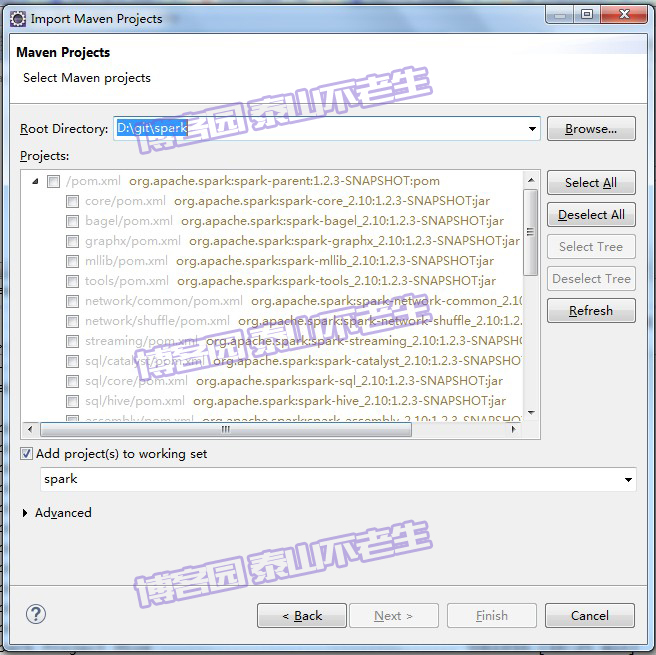
图1-24 选择Maven项目
全选所有项目,点击finish按钮。这样就完成了导入,如图1-25所示:

图1-25 导入完成的项目
导入完成后,需要设置每个子项目的build path。右键单击每个项目,选择“Build Path”→“Configure Build Path…”,打开Build Path对话框,如图1-26:

图1-26 Java编译目录
点击“Add External JARs…”按钮,将Spark项目下的lib_managed文件夹的子文件夹bundles和jars内的jar包添加进来。
注意:lib_managed/jars文件夹下有很多打好的spark的包,比如:spark-catalyst_2.10-1.3.2-SNAPSHOT.jar。这些jar包有可能与你下载的Spark源码的版本不一致,导致你在调试源码时,发生jar包冲突。所以请将它们排除出去。
Eclipse在对项目编译时,笔者本地出现了很多错误,有关这些错误的解决见附录H。所有错误解决后运行mvn clean install,如图1-27所示:

图1-27 编译成功
5.调试Spark源码
以Spark源码自带的JavaWordCount为例,介绍如何调试Spark源码。右键单击JavaWordCount.java,选择“Debug As”→“Java Application”即可。如果想修改配置参数,右键单击JavaWordCount.java,选择“Debug As”→“Debug Configurations…”,从打开的对话框中选择JavaWordCount,在右侧标签可以修改Java执行参数、JRE、classpath、环境变量等配置,如图1-28所示:

图1-28源码调试
读者也可以在Spark源码中设置断点,进行跟踪调试。
1.5 小结
本章通过引导大家在Linux操作系统下搭建基本的执行环境,并且介绍spark-shell等脚本的执行,目的无法是为了帮助读者由浅入深的进行Spark源码的学习。由于目前多数开发工作都在Windows系统下,并且Eclipse有最广大的用户群,即便是一些开始使用IntelliJ的用户对Eclipse也不陌生,所以在Windows环境下搭建源码阅读环境时,选择这些最常用的工具,希望能降低读者的学习门槛,并且替大家节省时间。
正文到此结束
- 本文标签: 操作系统 lib 项目管理 wget Hadoop eclipse 线程 zookeeper IDE App dist Word java authenticate maven https 教育 apr 数据 时间 参数 build mmm spring 源码 db git 美国 京东 调试 代码 软件 jvisualvm 博客 rmi classpath remote ip 数据库 HDFS UI GitHub 插件 Amazon http 目录 启动过程 windows shell Oracle 网站 配置 亚马逊 key 开源 主机 2015 云 编译 cmd tomcat 公交 cat 安装 Netty 解析 总结 统计 下载 linux ssl tab mina 地铁 互联网 map 管理 HTML 开发 src 数据挖掘 apache unix jetty tar 进程 sql 大数据 初学者
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

