爬虫框架设计
最近的一个项目是写一个爬虫框架,这个框架主要采用Master-Slave的结构,Master负责管理要爬取的Url和已经爬取过的Url,Slave可以有多个,主要负责爬取网页内容,以及对爬取下来的网页内容进行持久化的工作。整个项目用Thrift作为RPC通信框架。
1. 爬虫流程
如果是一个单机版的爬虫,其实代码非常简单:
Initialize: UrlsDone = ∅ UrlsTodo = {‘‘yahoo.com/index.htm’’, ..} Repeat: url = UrlsTodo.getNext() ip = DNSlookup( url.getHostname() ) html = DownloadPage( ip , url.getPath() ) UrlsDone.insert( url ) newUrls = parseForLinks( html ) For each newUrl If not UrlsDone.contains( newUrl ) then UrlsTodo.insert( newUrl ) 如果需要将UrlsDone和UrlsToDo这两个数据结构交由一个Master来管理,Master的接口可以定义成如下的:
public interface SpiderManager extends Closeable { /** * 获取一个待爬取的URL * @return URL */ URLData poll(); /** * 将一个待爬取的URL交给Manger */ void offer(URLData url); /** * 将一个已经爬取的URL返回给Manager */ void done(URLData url); /** * 判断一个URL是否已经爬取过 * @param url * @return */ boolean isDone(URLData url); /** * 已经处理过的URL数量 */ long doneSize(); /** * 待处理的URL数量 */ long toDoSize(); boolean usingAck(); } 2.分布式爬虫框架要解决的问题
上述单机的版的爬虫,在数据量不大和数据更新频率要求不高的情况下,可以很好的工作,但是当需要爬取的页面数量过多,或者网站有反爬虫限制的时候,上述代码并不能很好的工作。
例如通用的搜索爬虫需要爬取很多网页的时候,就需要多个爬虫来一起工作,这个时候各个爬虫必然要共享上述两个数据结构。
其次,现在很多网站对于爬虫都有限制,如果要是爬取的过于频繁,会被封Ip,为了应对这种情况,对应的策略是休眠一段时间,这样的话,又浪费了CPU资源。
最后,当要求实现不同的爬取策略,或者统一管理爬虫作业生命周期的时候,必然要一个Master来协调各个Slave的工作。
3. 设计实现
3.1 Master:
我们框架的主节点称为WebCrawlerMaster,针对不同的爬虫任务,WebCrawlerMaster会生成不同的WebCrawlerManager,WebCrawlerManger的功能是管理UrlsToDo和UrlsDone两个数据结构。Master主要的功能是管理WebCrawlerManager的实例,并且将不同的请求路由到对应的WebCrawlerManager上去。
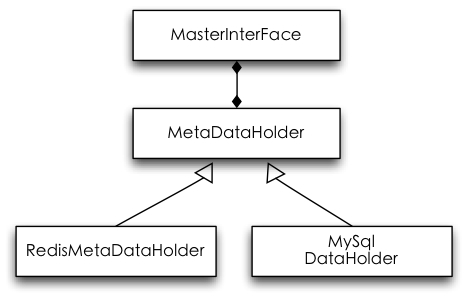
对于Master来说,最主要的组件是一个叫做MetaDataHolder的成员,它主要用来管理元数据信息。为了加强系统的健壮性,这部分信息是一定需要持久化的,至于持久化的选择,可以是Redis,或者关系型数据库,甚至写文件都可以。如果用Mysql来做持久化的工作,则需要做应用层的cache(通常用一个HashMap来实现)。
3.2 数据结构
对于一个CrawlManager,它主要管理两个数据结构UrlToDo,和UrlDone,前者可以抽象成一个链表,栈或者有优先级的队列,后者对外的表现是一个Set,做去重的工作。当定义出ADT(abstract data type)以后,则可以考虑出怎么样的去实现这个数据结构。这样的设计方法其实和实现一个数据结构是一样的,只不过当我们实现数据结构的时候,操作的对象是内存中的数组和列表,而在这个项目中,我们操作的对象是各种存储中提供给我们的功能,例如Redis中的List、Set,关系型数据库中的表等等。
4. 后记
这次的爬虫框架,从最开始的伪代码来看,是很简单的事情,但是一旦涉及到分布式的环境和系统的可扩展性,要真的实现起来,还是需要考虑到一些额外的东西,例如并发状态下共享数据结构的读写、系统的高可用等等,但是我觉得这个项目真正让我满意的地方,是通过合理的数据结构行为层面的抽象,让这个爬虫系统有着很强的扩展性。例如现在默认的UrlToDo是一个FIFO的队列,这样的话,爬虫实际上是按照BSF的策略去爬取的。但是当UrlToDo配置成一个LIFO的stack以后,爬虫实际上按照DSF的策略去爬取的,而这样的变化,只需要的更改一下请求新的WebCrawlerManager的参数,爬虫的业务代码并不需要任何的修改。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

