你一定要知道这个运维产品的能力闭环体系

实现一个运维产品的闭环,比碎片式的产品建设更有意义。
抛开我最近创业对这一问题的必要性思考,回归到一个企业内运维团队本身,个人觉得也需要思考这个命题。一个完善的运维平台才能做到对业务的运营有效支撑。个人把产品的水平闭环思考分解成如下几个问题,从这些角度下去,发现很容易找到该问题本质。
前言
当我们建设一个运维或者业务系统的时候,一定要记得软件工程方法作用性,比如说系统中的角色(Role)、系统的Use Case(注意不是测试用例)、领域模型(Domain Model)等等。
一、从运维角色来看
从一个系统的完整运维栈来说,存在很多角色。基础设施层涉及网络管理员/服务器管理员,再往上服务器资源交付之后,OS层有系统管理员或者基于基础资源构建的OS云平台管理员。从应用或服务的角度看过去,在OS之上承载的公共组件服务或者业务的应用服务等等。
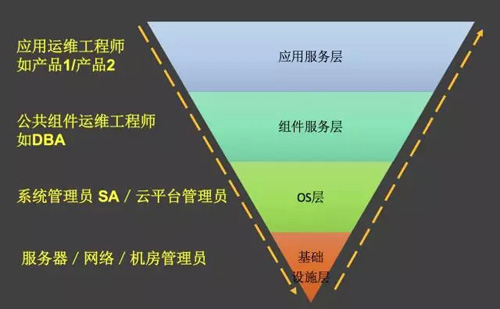
系统建设开始的时候,可以按照角色独立建设,我理解这是“分而治之”的策略。但随着后面应用运维的运维平台的一体化能力不断增强(比如说腾讯织云/蓝鲸),此时就对底层的运维平台能力开放性要求越来越高。
当然这个地方我建议分成如下三个阶段:
1. 独立的按照核心角色需求建设运维平台 。比如说GSLB管理平台,优先考虑域名管理员的管理需求,如域名管理/Zone管理/View管理/IP地址库管理等等。
2. 某些场景开放给应用运维平台人工处理 。依然以DNS管理平台为例,这个地方需要打破“DNS管理平台是DNS管理员的平台”这一认知。逐渐把能力开放出来,释放管理员的管理压力。比如说把域名的管理权限开放给业务运维角色,毕竟这一需求是因为业务而起,但Zone/View/IP地址的管理权限依然要收敛在核心dns管理员角色这边。
3. 某些场景开放给应用运维平台自动化处理 ,即API化。第二个阶段运行逐渐成熟之后,最重要的是理念已经达成一致,此时可以考虑能力API开放,控制好接口的权限。上层驱动底层能力服务化,进一步打破“我的事情我做主”的职责边界,从而才能实现“DevOps自动化”的目标。
其实这些角色的需求在不同的平台中都有存在的,只不过是多与少的问题,底层的服务化能力越强,上层的自动化能力也就愈强;上层的能力整体性越强,越来依赖和驱动底层的能力服务化。
二、从运维场景来看
场景是驱动运维闭环的最好方式,核心的维度就是持续交付。持续交付是一种PDCA式的运维过程,资源交付/服务交付/应用交付等都可以构成一体化的场景吧!拿应用交付举例来说:
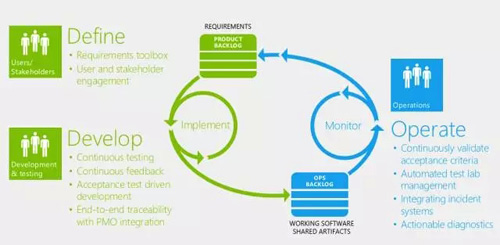
从用户需求产生到研发/测试/运维,这是一个完整的持续交付链。从研发侧有一个实施/实现过程,在运维侧有个监控能力。在对接的能力上,一方面是用户的需求队列;Dev和Ops的对接是一个Ops的需求队列,从持续集成上来看就是统一构建库。
从以上的图可以看出来,这个能力是闭环的,持续迭代的(类似PDCA环),这也是持续交付的典型特征。持续交付的另外一个典型特征:把后续的产品能力优化直接体现在实时的数据运营分析框架之上(持续反馈,类似PDCA中的C),任何滞后与非实时的数据价值都会大大缩水,数据化的运营思路能不断驱动产品的质量提升。此时我们谨记: 运维即IT运营 。
三、从域模型的角度来看
域是一种业务域名,降低系统复杂理解的第一步,不是考虑具体的数据和行为实现。复杂的业务系统如同电信的BOSS系统,也分成了几个核心域,如:客户域/事件域/产品域/营销域/账务域/地址域等等。这样能确保不同的BOSS子系统(如CRM/计费系统)等,都可以确保在底层数据模型和行为设计上是一致的。
以下是我对运维领域模型的一个分类,如下:
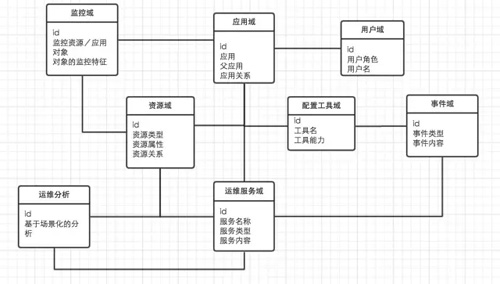
1. 应用域 。是一个面向应用的信息管理,是构成运维系统场景化的核心元数据,在所有的运维系统中都应该在这个维度上建立起管理关联。最合理的表达是业务之间的内在逻辑关系,业界通行的做法是资源tag化。
2. 资源域 。资源是一个泛化的概念,传统的资源范围包含了网络资源/服务器资源等物理资源,但随着云计算的逐渐普及,此时应该把资源的概念延伸到一些服务上,比如说mysql是一种rds存储资源;分布式hadoop是一种分布式存储及计算资源。这个也符合Heroku关于12factor中一个描述,把后端服务当作一种附加资源来看待。
3. 运维服务域 。资源及服务资源的管理都需要抽象成服务,服务化的管理能力以平台化/可视化管理为基础的。mysql有mysql管理平台,服务器有服务器的管理平台,cache有cache管理平台,这些管理平台能力起来之后,进一步服务化其能力。另外一种服务化能力,是面向应用的场景化服务能力,比如说业务的扩容/迁移等服务能力。
4. 配置工具域 。以配置管理为基础,但是这个内容和范畴也需要延伸,它的能力不仅仅是作用在OS对象本身,还能过痛过这个平台能力去操作外部的资源(通过外部服务实现的)。
以上的域名能构成一个全自动化平台的能力体系。
5. 监控域 。无论是资源还是服务,都需要很强的监控能力,他是能过直接表达资源和服务的状态,通过这些状态进一步表达业务/应用的健康状况,目标是确保业务高可用。
6. 事件域 。无论是作业事件/监控事件,在分布式系统中都存在着很多的事件,这些事件可以放在统一的事件中心中纪录和存储,注意和ITIL事件系统不一样。事件集中管理/关联,在告警分析的场景下是能过有分析价值的。
7. 运营分析 。它不能构成一个域,只能称为一种场景。基于很多运营场景,场景化的数据分析和应用,通过数据来驱动运维优化,类似运营商的经营分析系统。
8. 用户域 。这个域名很简单,把DevOps各类角色管理起来,可以和域帐号对接。
基于这些域可以构建不同的功能子系统,比如说作业管理/运维调度系统/持续部署/监控平台/CMDB等等。
当然这个是一个运维内部系统,其实如果是一个外部运维SaaS平台的话,还有客户域,计费域、账务域等等。不过,在SaaS模型下,计费和帐务模型可以简单,我们当前采用的就是“Host.月”的计费模型,这样的话确保平台更简单。
四、从IT运营价值来看
角色+场景能导出对某一类资源的管理功能需求,从而反映IT对业务运营的能力支撑。
一方面:运维平台的能力必须要向上开放, 满足运营的快速交付 。没有理由在构筑藩篱,这是传统维护思维的核心障碍。曾经一个团队就不愿意开放,导致系统的建设七零八落,也就无法满足DevOps快速交付的能力要求。
另一方面:运营的精细化能力要在数据上体现出来, 满足运营的持续改进 。比如说对业务质量的优化,质量模型,数据的来源,数据的实时性等等都需要;性能的优化,就需要运营系统能够采集所有的接口性能数据;某个页面的体验优化,就需要把页面的性能指标完整的采集下来。精细化/实时/端到端的数据采集/处理/分析体系是运营价值的核心部分。
坚持产品的垂直与水平闭环体系,才是一个做出一个真正好用的运维平台!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

