基于用户命令行为的内部威胁检测实验
原创作者:木千之

0×00 前言
之前在FreeBuf上看到过针对机器学习在安全领域应用的介绍,或许在信息爆炸的大数据时代,从数据中寻找安全解决方案不失为一种好的选择。概念容易理解,但是如果项目落地到底是什么样呢?作为抛砖引玉,今天我就为大家带来一个基于用户命令行为数据的内部威胁检测实验,希望在FreeBuf上可以涌现更多机器学习在安全领域应用研究的好文章。
0×01 实验数据集
机器学习的核心思想是从大量数据集中训练,进而学习出我们目前还无法知晓或描述的知识,然后基于获得的知识对新的情况进行预测或判断。因此,作为机器学习研究或应用的第一步关键工作就是获取数据。
目前数据本身就是一种稀缺资源,往往一个分析项目最大的难点就是如何获取到需要的数据。比如想进行交通路况状态的大数据分析,首先必须要有交通路况流量等数据,这些只能从交警部门获得;再如想进行诈骗短信的模型挖掘分析,就必须首先和移动、联通和电信合作,获取到短信流信息,然后才能基于词法进行学习分类,等等。由于当前的客观局限,大量关键数据并不公开,这就需要政策和公关的帮助。
学界为了进行机器学习的相关研究,以及比较不同算法的效果差异,往往采用公开可得的安全数据集。这些数据集都是研究者在特定的环境中实际采集到的数据,经过处理后提供给大家免费使用。我们今天实验使用的数据集,就是著名的Schonlau数据集。
内部威胁检测是一门年轻的研究领域,2008年的一篇创领域综述中,第一次正式提出了内部威胁,并且将其细化为了Traitor(组织合法成员)和Masquerader(外部伪装的内部成员)两类攻击,并且根据两类攻击者的特点进行了分析,提出了可行的应对建议。
今天我们将要使用的Schonlau的Masquerader数据集简称为S-M数据集。该数据集结构如下:
1. 记录50个用户的命令行为记录; 2. 每个用户总共记录了15000条; 3. 每个用户的前5000条记录是正常的,后续的10000条记录分成100个块(每个块100条命令)中随机混入了Masquerade的命令行为; 4. 所有的命令块都提供了类别标签,以供训练和实验分组;
整体的User记录列表如图1:

以User7为例,具体的命令行为记录如图2:

在后面的实验中,我们会以User7为例进行学习、测试,更加具体的数据集信息可以参考Schonlau的个人网站: http://www.schonlau.net/
0×02 特征提取
机器学习应用的关键有两个:一个是数据分析提取特征,构建学习用的特征向量;另一个则是构建合适的算法分类器,调整最优参数获得最好的分类效果和鲁棒性。
针对一个数据集的特征构建有诸多方法,所得的特征也各有不同。今天出于实验的考虑,我们用两种方法来构建特征。
下述实验所用的数据均已经处理成了100条命令组成的命令块,每个用户均有150个块。
1. 统计特征
最常用的特征方法当然是基于统计分析的特征提取。我们给出一个命令块的示例,如User7的第一个命令块:
['cpp', 'sh', 'xrdb', 'cpp', 'sh', 'xrdb', 'mkpts', 'test', 'stty', 'hostname', 'date', 'echo', '[', 'find', 'chmod', 'tty', 'echo', 'env', 'echo', 'sh', 'userenv', 'wait4wm', 'xhost', 'xsetroot', 'reaper', 'xmodmap', 'sh', '[', 'cat', 'stty', 'hostname', 'date', 'echo', '[', 'find', 'chmod', 'tty', 'echo', 'sh', 'more', 'sh', 'more', 'sh', 'more', 'sh', 'more', 'sh', 'more', 'sh', 'more', 'sh', 'more', 'sh', 'more', 'sh', 'more', 'sh', 'more', 'sh', 'more', 'sh', 'launchef', 'launchef', 'sh', '9term', 'sh', 'launchef', 'sh', 'launchef', 'hostname', '[', 'cat', 'stty', 'hostname', 'date', 'echo', '[', 'find', 'chmod', 'tty', 'echo', 'sh', 'more', 'sh', 'more', 'sh', 'ex', 'sendmail', 'sendmail', 'sh', 'MediaMai', 'sendmail', 'sh', 'rm', 'MediaMai', 'sh', 'rm', 'MediaMai', 'launchef', 'launchef']
为了分类的需要,我们要从中提取出特征构建特征向量进行机器学习的训练。从统计的角度考虑,我们首先使用以下三个维度的特征向量:
FeatureVector:【命令种类数,最多的n个命令,最少的m个命令】
其中,命令种类数指的是100个命令组成的命令块中出现过的命令种类;最多的n个命令则是指命令块中出现次数降序排列的前n个;同理,最少的m个命令则是指命令块中出现次数降升序排列的前m个。同样是User7的第一个命令块,提取特征向量为:
FeatureVector:【28, ['mkpts', 'xsetroot', 'xhost', 'ex', 'reaper'], ['sh', 'more', 'echo', 'launchef', '[' 】
整体的特征向量结构如图3:

之所以选择这三个特征向量,是因为我们假设用户在日常的工作中的命令行为应该具有稳定性,训练期间整体的命令使用记录应当呈现稳定的规律。
2. 文本特征
上面介绍了我们实验中使用的统计特征,该特征主要在KNN分类器中使用。对于这类文本数据,我们可以使用朴素贝叶斯(Naive Bayes)分类器。但是在此之前,我们需要对数据进行处理,获得文本特征。
我们这里使用的文本特征基于一个训练集的词汇表,根据一般的训练测试比例,我们选择90%的数据用来训练,10%的数据用来测试。我们首先建立一个词集(WordSet),其中包含训练集中出现过的所有单词,这里即我们所说的用户命令。
通过随机选取135个命令块,我们统计其中出现的命令单词,获得长度为144的词汇表:
['tty', 'gs', 'xdvi.rea', 'basename', 'uname', 'sleep', 'touch', 'find', 'lc', 'ln', 'xset', 'tail', 'dict', 'ls', 'lp', 'troff', 'dvips', 'ld_', 'ksh', 'xconfirm', 'env', '==', 'xdm', 'xterm', 'tbl', 'getpgrp', 'MakeTeXP', 'stty', 'du', 'gethost', 'mimencod', 'tput', 'p', 'samterm', 'appdefpa', 'dvipost', 'xhost', 'FIFO', 'wdefine', 'sed', 'ex', 'download', 'dirname', '9term', 'sendmail', 'rm', 'bc', 'netstat', 'nawk', 'mkpts', 'news', '[', 'on', 'rlogin', 'lks', 'xmodmap', 'w', 'faces', '4Dwm', 'col', 'drf', 'postprin', 'tcpostio', 'xsetroot', 'chmod', 'echo', 'colthloo', 'printf', 'xrdb', 'diff', 'xdvi', 'xv', 'post', 'pr', 'ps', 'wait4wm', 'pq', 'ppost', 'mkdir', 'MediaMai', 'hpost', 'xlistscr', 'rmdir', 'dpost', 'virmf', 'userenv', 'sort', 'LOCK', 'eqn', 'telnet', 'pwd', 'delatex', 'nospool', 'true', 'netscape', 'grep', 'mc', 'agrep', 'expr', 'cat', 'ul', 'xprop', 'virtex', 'more', 'launchef', 'sprog', 'gettxt', 'sam', 'mailx', 'file', 'ispell', 'id', 'xmaplev5', 'xmaplev4', 'xrn', 'egrep', 'hoc', 'xwsh', 'generic', 'twm', 'hostname', 'acroread', 'endsessi', 'reaper', 'which', 'test', 'getopt', '=', 'tellwm', 'colthrea', 'spell', 'ghostvie', 'tcppost', 'toolches', 'gzip', 'UNLOCK', 'awk', 'gftopk', 'date', 'maple.sy', 'xclock', 'man', 'sh', 'cpp']
在获得词汇表之后,对135个训练命令块分别提取特征。特征向量为一个与词汇表相同长度的特征向量,当对应的命令在块中出现时,则该块的对应位置元素为1,未出现则为0。同样以User7的第一个命令块的特征向量为例:
[1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1]
在处理获得训练集的特征向量后,接下来的工作就是构建分类器了。
0×03 KNN实验
1. KNN介绍
KNN(K Nearest Neighbour)称之为“K最近邻”算法。它的核心思想是比较一个示例与已知的所有样本的距离,选择最近的K个样本,以这些样本中数量最多的类别作为新示例的判断结果。以图4为例:

假设与示例最近的7个样本中,三个属于类别1, 两个属于类别2,类别3和类别4分别只有一个,那么分类器就会判定示例类别为1。
2 . KNN距离计算
KNN算法的关键在于距离的度量。一般对于数值型的特征可以使用欧式距离,而对于集合特征,我们使用比较不同命令的个数,最终都是作为数值型计算欧氏距离。
KNN算法的优点是:精度高、对异常值不敏感、无数据输入假定; KNN算法的缺点是:计算复杂度高,空间复杂度高(存储训练集的距离)
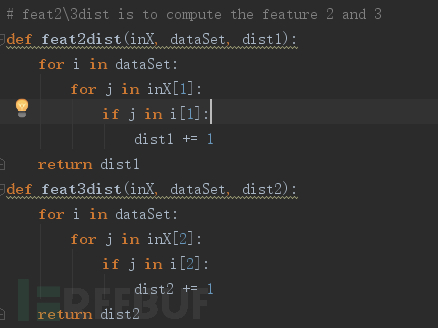
针对之前我们获得的统计特征:
FeatureVector:【28, ['mkpts', 'xsetroot', 'xhost', 'ex', 'reaper'], ['sh', 'more', 'echo', 'launchef', '[' 】
第一个维度可以直接计算欧式距离,后两个维度则比较两个特征向量间的相同性,将差异值作为计算欧式距离的数值,代码如图5:
KNN算法不需要构建分类器,大致过程如下:
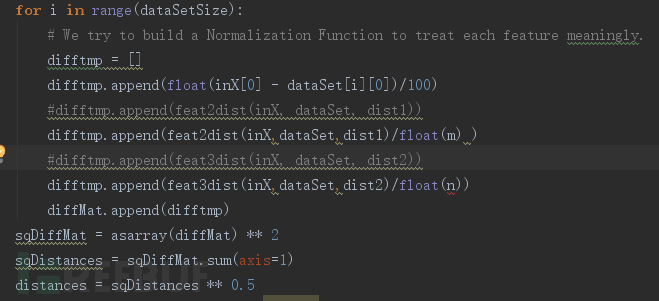
1. 计算、存储训练集的特征向量; 2. 输入一个新示例x,计算其特征向量; 3. 计算新示例特征向量与训练集所有特征向量的距离; 4. 选择距离最小的k个向量; 5. 判断k个向量的类别,占比最高的类别即为x的类别;
KNN算法中特征向量间的距离计算代码如图6:
KNN实验结果
我们使用KNN算法进行了“10折交叉验证”,10次实验的平均准确率为0.866667,平均用时0.439156,可以由于数据量较小,因此运行速度很快,但是准确率并不高,尤其是有两例漏报,因此实际的应用效果并不理想。
分类效果不理想有多方面原因,对应也可以从多个方面改进。比如数据的再处理(归一化、去中心化等),比如参数的调整设置(KNN中k的取值,以及m和n的取值),比如扩充特征向量。如果上述方法都不理想,那么我们可以选择更加合适的算法构建分类器。我们下面是用朴素贝叶斯来构建分类器。
0×04 NB实验
Naive Bayes(NB)称之为朴素贝叶斯,其基础为贝叶斯理论。贝叶斯理论的核心思想就是当需要对示例进行分类时,计算示例属于每种分类的条件概率,然后选择概率最大的分类作为判断。例如,对于示例x有两个分类:1表示异常,0表示正常,那么我们分别计算P(1|x)和P(0|x),如果P(1|x) > P(0|x),则x属于类别1,异常;反之属于类别0。
一般来说计算P(1|x)比较麻烦,那么我们使用贝叶斯公式进行简化,如图7:
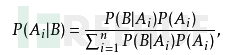
当我们考虑是朴素贝叶斯时,即考虑特征间各个维度相互独立,且都是同等重要的。那么分子的计算可以进行简化,这里更多的细节略去不表,感兴趣的童鞋可以参考 博文
我们直接给出实现的代码,具体在python中实现时会根据工程进行一些改变,如图8计算重要的概率参数:

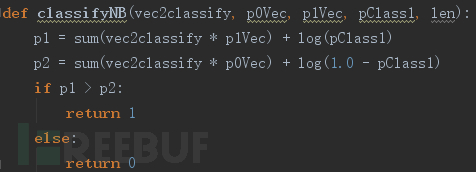
如图9进行分类判定:
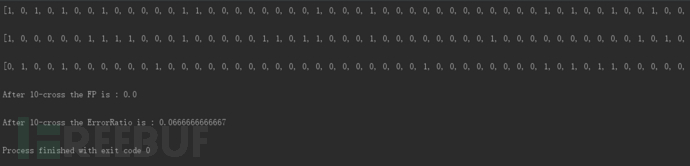
最终的实验结果果然没有让我们失望,同样采用10折交叉验证,朴素贝叶斯分类器的错误率只有0.0666…,误报率为0,,如图10:
0×05 小结
今天我们基于公开的S-M用户命令行为数据集,分别提取了统计特征和文本特征。当使用KNN构建的分类器针对统计特征不能很好地识别异常命令块时,我们采用朴素贝叶斯分类器针对文本特征识别异常,相比于KNN分类器结果大大改进。
实验的结果仍旧有很大的改进空间。基于机器学习建立的主动检测机制的效果改进可以从特征扩充、参数微调、模型修改以及算法选择上着手,一般都会有不错的结果。我们今天的实验为大家呈现了主动检测机制一点端倪:
1. 收集数据:来自你需要的各个领域; 2. 准备数据:将数据处理成指定格式,如命令块、文本向量等; 3. 分析数据:从数据特点以及安全知识中提取特征,建立特征向量; 4. 训练算法:选择合适的机器学习算法,学习模型参数; 5. 测试算法:按照10折交叉验证测试分类器效果; 6. 使用算法:若算法效果可以接受,则实际部署;否则返回步骤3,循环;
关键有两点,一个是特征的选择和构建,一个是算法分类器的选择和优化; 而现实应用最大的瓶颈则是误报率高。今天的实验介绍仅仅是领域的一个边角,更多有趣的内容欢迎大家一起分享!
参考资料
A Survey of Insider Attack Detection Research, Malek & Shlomo, 2008;
机器学习实战,Perter Harrington, 人民邮电出版社, 2013
作者QQ:415428815
*作者:木千之,本文属FreeBuf原创奖励计划文章,未经许可禁止转载
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

