Netflix数据处理架构的演进
Netflix是一家在线影片租赁提供商,该公司连续五次被评为顾客最满意的网站,在过去的7年中,Netflix流媒体服务从偶尔有数千用户在线观看发展到了数百万用户平均每月观看超过20亿个小时的规模。Netflix之所以能够如此成功,离不开对用户行为数据的收集与分析,那么Netflix会收集哪些数据,这些数据会用来做什么,其处理架构又是什么呢?本文根据Netflix博客上的《 Netflix's Viewing Data: How We Know Where You Are in House of Cards
》一文整理而来,如果想要查看英文原文请点击 这里 。
事实上,当用户开始在Netflix的网站上观看电影或者电视节目的时候,Netflix的数据系统会创建一个“观看会话(view)”,描述该会话的所有事件信息都会被收集起来。该观看会话数据架构能够应对从用户体验到数据分析的诸多场景,其中最主要的场景有三个:
- 用户看了哪些视频? 系统需要知道每一个用户的所有观看历史,以便于为用户推荐相关的视频内容,同时在页面上的“最近观看”一栏中显示观看历史。用户所看的内容对于用户兴趣的衡量,产品和内容的决定非常重要。
- 用户从哪里离开了视频? 对于每一个电影或者电视节目,Netflix会记录每一个用户都看到了哪里,从哪个时间点离开的。这使得Netflix的用户能够在同一个或者另一个设备上继续观看视频。
- 当前帐户现在还在观看哪些视频? 家庭成员间的帐户共享使得任何人可以在任何时候观看自己喜欢的视频,但是这也意味着当帐户同时在线数超限的时候,必须要有人放弃观看。针对这种场景,Netflix的观看会话数据系统会收集每一个会话的周期性信号以便于决定某个成员是否还在观看相关视频。
这些场景的实现离不开强大而稳定的数据处理系统,Netflix目前的系统架构由早期的单数据库应用程序演变而来,当时的主要需求是能够低延迟地为用户提供视频服务,同时还能够处理来自于数百万Netflix流设备的快速增长的数据集。在过去3年多的时间里,Netflix一直在不断地改进该架构,现在这套系统每天能够处理千亿左右的事件。
当前的架构图如下:

整个架构最主要的接口是观看会话服务,它分为有状态层和无状态层两部分。有状态层在内存中存有所有活动视图的最新数据。通过对用户帐户ID进行mod N的模运算,数据被简单地划分为N个有状态的节点。当有状态的节点上线的时候,系统会通过一个位置选择流程决定哪部分数据属于它们。所有的持久化数据都存储在Cassandra中,在Cassandra之上有一个Memcached用来保证低延迟的读取路径,但是采用这种方式会话数据有可能会过时,同时如果一个有状态的节点出现了错误,那么1/n的浏览数据将不能读写。无状态层的引入正是为了解决这一问题,它提升了系统的可用性,当有状态的节点无法访问的时候,该层会将过时的数据反馈给用户。
但是即使是做了诸多改进,以上架构依然存在一些缺陷:
- 虽然有状态层使用一个简单的、服从热点分布的分片技术,但是Cassandra层并不服从这些热点;同时,如果将其从一个AWS Region移动到多个AWS Region上运行,那么必须定制一种机制来实现分布在不同Region上的状态层之间的状态通信,极大地增加了系统的复杂性。
- 对于观看会话服务,它封装了会话数据的收集、处理和提供功能,随着系统的演变,功能的增多,该服务的责任也越来越多,增加了运维的难度。
- 虽然Memcached提供了非常好的吞吐量和延迟特性,但是使用一种能够为一等数据类型和操作(例如append)提供原生支持的技术能够更好地满足相关需求。
为了扩展系统满足下一个数量级的需要,Netflix正在重新思考自己的基础架构,新系统在设计时考虑的主要设计原则包括:
- 可用性比一致性更重要。
- 微服务 。对于有状态架构中柔和在一起的组件,根据它们的主要目的分离成单独的服务——或收集、处理或提供数据。将状态管理功能托管到持久化层,让应用程序层无状态,同时组件之间通过事件队列解耦。
- 混合持久化 。使用多种持久化技术,利用每一种方案的优势。使用Cassandra实现高容量、低延迟的写。使用Redis实现高容量、低延迟的读。
遵循以上原则的新架构实现如下:
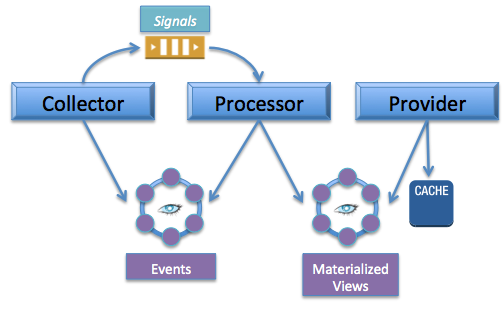
当然,这个架构图也仅仅是Netflix目前的设计图,至于实现到何种程度了,我们还未可知。Netflix表示对关键系统进行重新架构以使其能够扩展到下一个数量级是一项非常困难的工作,需要长时间的开发、测试和验证,同时迁移也不是那么容易。但是以这些架构原则为指导,Netflix相信他们正在构建的下一代系统能够满足自己大规模、快速增长的需要。
感谢郭蕾对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ)或者腾讯微博(@InfoQ)关注我们,并与我们的编辑和其他读者朋友交流。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

