MySQL Sending data导致查询很慢的问题详细分析
这两天帮忙定位一个mysql查询很慢的问题,定位过程综合各种方法、理论、工具,很有代表性,分享给大家作为新年礼物:)
【问题现象】
使用sphinx支持倒排索引,但sphinx从mysql查询源数据的时候,查询的记录数才几万条,但查询的速度非常慢,大概要4~5分钟左右
【处理过程】
1)explain
首先怀疑索引没有建好,于是使用explain查看查询计划,结果如下:
 从explain的结果来看,整个语句的索引设计是没有问题的,除了第一个表因为业务需要进行整表扫描外,其它的表都是通过索引访问
2)show processlist;
explain看不出问题,那到底慢在哪里呢?
于是想到了使用 show processlist查看sql语句执行状态,查询结果如下:
从explain的结果来看,整个语句的索引设计是没有问题的,除了第一个表因为业务需要进行整表扫描外,其它的表都是通过索引访问
2)show processlist;
explain看不出问题,那到底慢在哪里呢?
于是想到了使用 show processlist查看sql语句执行状态,查询结果如下:
 发现很长一段时间,查询都处在 “Sending data”状态
查询一下“Sending data”状态的含义,原来这个状态的名称很具有误导性,所谓的“Sending data”并不是单纯的发送数据,而是包括“收集 + 发送 数据”。
这里的关键是为什么要收集数据,原因在于:mysql使用“索引”完成查询结束后,mysql得到了一堆的行id,如果有的列并不在索引中,mysql需要重新到“数据行”上将需要返回的数据读取出来返回个客户端。
3)show profile
为了进一步验证查询的时间分布,于是使用了show profile命令来查看详细的时间分布
首先打开配置:set profiling=on;
执行完查询后,使用show profiles查看query id;
使用show profile for query query_id查看详细信息;
结果如下:
发现很长一段时间,查询都处在 “Sending data”状态
查询一下“Sending data”状态的含义,原来这个状态的名称很具有误导性,所谓的“Sending data”并不是单纯的发送数据,而是包括“收集 + 发送 数据”。
这里的关键是为什么要收集数据,原因在于:mysql使用“索引”完成查询结束后,mysql得到了一堆的行id,如果有的列并不在索引中,mysql需要重新到“数据行”上将需要返回的数据读取出来返回个客户端。
3)show profile
为了进一步验证查询的时间分布,于是使用了show profile命令来查看详细的时间分布
首先打开配置:set profiling=on;
执行完查询后,使用show profiles查看query id;
使用show profile for query query_id查看详细信息;
结果如下:
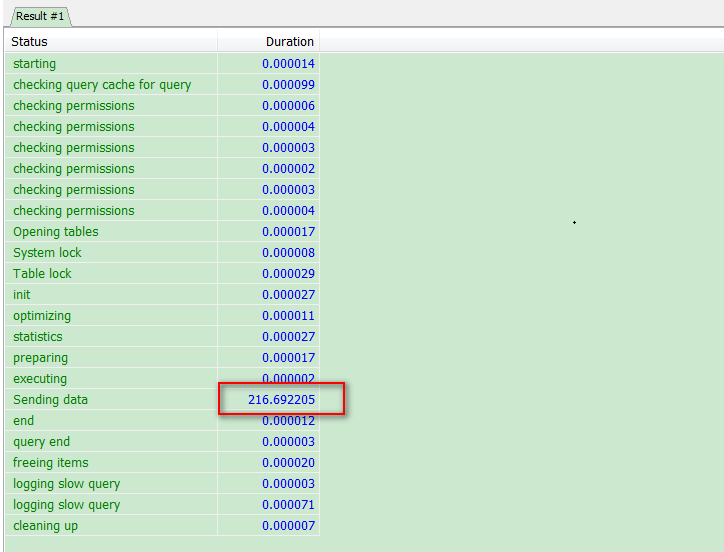 从结果可以看出,Sending data的状态执行了216s
4)排查对比
经过以上步骤,已经确定查询慢是因为大量的时间耗费在了Sending data状态上,结合Sending data的定义,将目标聚焦在查询语句的返回列上面
经过一 一排查,最后定为到一个description的列上,这个列的设计为:`description`varchar(8000) DEFAULT NULL COMMENT '游戏描述',
于是采取了对比的方法,看看“不返回description的结果”如何。show profile的结果如下:
从结果可以看出,Sending data的状态执行了216s
4)排查对比
经过以上步骤,已经确定查询慢是因为大量的时间耗费在了Sending data状态上,结合Sending data的定义,将目标聚焦在查询语句的返回列上面
经过一 一排查,最后定为到一个description的列上,这个列的设计为:`description`varchar(8000) DEFAULT NULL COMMENT '游戏描述',
于是采取了对比的方法,看看“不返回description的结果”如何。show profile的结果如下:
 可以看出,不返回description的时候,查询时间只需要15s,返回的时候,需要216s,两者相差15倍
【原理研究】
至此问题已经明确,但原理上我们还需要继续探究。
这篇淘宝的文章很好的解释了相关原理:innodb使用大字段text,blob的一些优化建议
这里的关键信息是:当Innodb的存储格式是
可以看出,不返回description的时候,查询时间只需要15s,返回的时候,需要216s,两者相差15倍
【原理研究】
至此问题已经明确,但原理上我们还需要继续探究。
这篇淘宝的文章很好的解释了相关原理:innodb使用大字段text,blob的一些优化建议
这里的关键信息是:当Innodb的存储格式是  可以看到,平均一行大约1.5K,也就说大约1/10行会使用“溢出存储”,一旦采用了这种方式存储,返回数据的时候本来是顺序读取的数据,就变成了随机读取了,所以导致性能急剧下降。
另外,在测试过程中还发现,无论这条语句执行多少次,甚至将整个表select *几次,语句的执行速度都没有明显变化。这个表的数据和索引加起来才150M左右,而整个Innodb buffer pool有5G,缓存整张表绰绰有余,如果缓存了溢出页,性能应该大幅提高才对。
但实测结果却并没有提高,因此从这个测试可以推论Innodb并没有将溢出页(overflow page)缓存到内存里面。
这样的设计也是符合逻辑的,因为overflow page本来就是存放大数据的,如果也放在缓存里面,就会出现一次大数据列(blob、text、varchar)查询,可能就将所有的缓存都更新了,这样会导致其它普通的查询性能急剧下降。
【解决方法】
找到了问题的根本原因,解决方法也就不难了。有几种方法:
1)查询时去掉description的查询,但这受限于业务的实现,可能需要业务做较大调整
2)表结构优化,将descripion拆分到另外的表,这个改动较大,需要已有业务配合修改,且如果业务还是要继续查询这个description的信息,则优化后的性能也不会有很大提升。
可以看到,平均一行大约1.5K,也就说大约1/10行会使用“溢出存储”,一旦采用了这种方式存储,返回数据的时候本来是顺序读取的数据,就变成了随机读取了,所以导致性能急剧下降。
另外,在测试过程中还发现,无论这条语句执行多少次,甚至将整个表select *几次,语句的执行速度都没有明显变化。这个表的数据和索引加起来才150M左右,而整个Innodb buffer pool有5G,缓存整张表绰绰有余,如果缓存了溢出页,性能应该大幅提高才对。
但实测结果却并没有提高,因此从这个测试可以推论Innodb并没有将溢出页(overflow page)缓存到内存里面。
这样的设计也是符合逻辑的,因为overflow page本来就是存放大数据的,如果也放在缓存里面,就会出现一次大数据列(blob、text、varchar)查询,可能就将所有的缓存都更新了,这样会导致其它普通的查询性能急剧下降。
【解决方法】
找到了问题的根本原因,解决方法也就不难了。有几种方法:
1)查询时去掉description的查询,但这受限于业务的实现,可能需要业务做较大调整
2)表结构优化,将descripion拆分到另外的表,这个改动较大,需要已有业务配合修改,且如果业务还是要继续查询这个description的信息,则优化后的性能也不会有很大提升。
从explain的结果来看,整个语句的索引设计是没有问题的,除了第一个表因为业务需要进行整表扫描外,其它的表都是通过索引访问
2)show processlist;
explain看不出问题,那到底慢在哪里呢?
于是想到了使用 show processlist查看sql语句执行状态,查询结果如下:
发现很长一段时间,查询都处在 “Sending data”状态
查询一下“Sending data”状态的含义,原来这个状态的名称很具有误导性,所谓的“Sending data”并不是单纯的发送数据,而是包括“收集 + 发送 数据”。
这里的关键是为什么要收集数据,原因在于:mysql使用“索引”完成查询结束后,mysql得到了一堆的行id,如果有的列并不在索引中,mysql需要重新到“数据行”上将需要返回的数据读取出来返回个客户端。
3)show profile
为了进一步验证查询的时间分布,于是使用了show profile命令来查看详细的时间分布
首先打开配置:set profiling=on;
执行完查询后,使用show profiles查看query id;
使用show profile for query query_id查看详细信息;
结果如下:
从结果可以看出,Sending data的状态执行了216s
4)排查对比
经过以上步骤,已经确定查询慢是因为大量的时间耗费在了Sending data状态上,结合Sending data的定义,将目标聚焦在查询语句的返回列上面
经过一 一排查,最后定为到一个description的列上,这个列的设计为:`description`varchar(8000) DEFAULT NULL COMMENT '游戏描述',
于是采取了对比的方法,看看“不返回description的结果”如何。show profile的结果如下:
可以看出,不返回description的时候,查询时间只需要15s,返回的时候,需要216s,两者相差15倍
【原理研究】
至此问题已经明确,但原理上我们还需要继续探究。
这篇淘宝的文章很好的解释了相关原理:innodb使用大字段text,blob的一些优化建议
这里的关键信息是:当Innodb的存储格式是 ROW_FORMAT=COMPACT (or ROW_FORMAT=REDUNDANT)的时候,Innodb只会存储前768字节的长度,剩余的数据存放到“溢出页”中。
我们使用show table status来查看表的相关信息:
可以看到,平均一行大约1.5K,也就说大约1/10行会使用“溢出存储”,一旦采用了这种方式存储,返回数据的时候本来是顺序读取的数据,就变成了随机读取了,所以导致性能急剧下降。
另外,在测试过程中还发现,无论这条语句执行多少次,甚至将整个表select *几次,语句的执行速度都没有明显变化。这个表的数据和索引加起来才150M左右,而整个Innodb buffer pool有5G,缓存整张表绰绰有余,如果缓存了溢出页,性能应该大幅提高才对。
但实测结果却并没有提高,因此从这个测试可以推论Innodb并没有将溢出页(overflow page)缓存到内存里面。
这样的设计也是符合逻辑的,因为overflow page本来就是存放大数据的,如果也放在缓存里面,就会出现一次大数据列(blob、text、varchar)查询,可能就将所有的缓存都更新了,这样会导致其它普通的查询性能急剧下降。
【解决方法】
找到了问题的根本原因,解决方法也就不难了。有几种方法:
1)查询时去掉description的查询,但这受限于业务的实现,可能需要业务做较大调整
2)表结构优化,将descripion拆分到另外的表,这个改动较大,需要已有业务配合修改,且如果业务还是要继续查询这个description的信息,则优化后的性能也不会有很大提升。
正文到此结束
- 本文标签: sphinx 详细分析 查询很慢 mysql Sending data show processlist explain
- 版权声明: 本文由HARRIES原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

