基于深度机器学习算法DBNs的风险识别模型
前言:最初关注深度机器学习是听了NUS的汪晟博士关于深度机器学习平台SIGNA的介绍,当时就发现深度机器学习是人工智能的一个革新的进步。但是由于从事的云计算和大数据方向的工作,所以平时只是作为自己的兴趣领域看了一些相关的入门级资料。最近事业部的同事在讨论文物保护的风险识别问题,不自觉地想到能否将深度机器学习运用到文物保护的风险识别中,于是做了一些较深入的研究,设计了一个基于深度机器学习DBN算法的风险识别模型。
一、传统机器学习与深度机器学习
传统机器学习最初是来源于Back Propagation算法的发明,因此人们在研究中发现可以使用BP算法和人工神经网络模型对大量的样本数据进行学习并最终经过反复调整和优化可以得到样本数据的统计规律,利用这一统计规律可以进行普通数据的分析以及对将要引起的反应进行一定程度上的预测。这种传统的机器学习非常依赖于样本数据的质量,如果没有高质量、高特征的样本数据,会导致预测模型的准确性大大降低。但是这和通过手工的编写SQL正则表达式来进行数据判断的方式相比,已经是大大的进步。传统的机器学习从上世纪80年代末被发现并得到热捧以来,在风险识别、商业智能、经济预测等领域得到大量的应用,相应的也开发出了大量的机器学习算法如SVM、决策树、聚类算法等。总的来说,这是人工智能第一次引起人们的重大关注和应用,也让人们更加的憧憬人工智能的未来。
深度机器学习的兴起是来源于《科学》杂志上一篇文章《Reducing the dimensionality of data with neural networks》,这篇文章的作者是加拿大多伦多大学教授、机器学习领域的泰斗Geoffrey Hinton和他的学生RuslanSalakhutdinov。这篇文章表达了两个主要观点:1)多隐层的人工神经网络具有优异的特征学习能力,学习得到的特征对数据有更本质的刻画,从而有利于可视化或分类;2)深度神经网络在训练上的难度,可以通过“逐层初始化”(layer-wise pre-training)来有效克服。自此人们开始了深度机器学习的研究和探索,目前深度机器学习的算法还是主要借鉴传统的机器学习算法,但是在不断的实践和研究中一些神一样存在的大牛也开发出了几个深度机器学习算法如(RBM)限制波尔兹曼机 、Deep Belief Networks深信度网络等。
二、Deep Belief Networks深信度网络
Depp Belief Networks(DBN)深信度网络也是加拿大多伦多大学教授、机器学习领域的泰斗Geoffrey Hinton在一篇文章中提出的,一个经典的DBN神经网络如图1。DBN相比于传统的机器学习算法如SVM、聚类算法、决策树等有一个更加智能等优势,就是DBN可以自主的在训练过程中发现样本数据之间的关联关系和规律,并会通过调节自身的权重值来持久化发现的关联关系和规律。

(图1)
DBNs是一个概率生成模型,与传统的判别模型的神经网络相比,概率生成模型是建立一个观察数据和标签之间的联合分布,对P(Observation|Label)和 P(Label|Observation)都做了评估,而判别模型仅仅评估了P(Label|Observation)。对应到上图就是P(v|h)和P(h|v),输入值v通过P(v|h)可以得到隐藏层h,而经过参数值调整之后隐藏层h通过P(h|v)可以得到一个与之前输入值近似的(理论上是完全一样)v1,这样隐藏层就可以作为一个特征模型(类似于卷积算法中的卷积核)存在,也就能对输入值进行识别。
DBNs的核心组件就是RBM(限制玻尔兹曼机),限制玻尔兹曼机是一种特殊类型的马尔科夫随机场,它含有一层随机隐藏单元和一层随机可见单元。RBM能表示一个二分图,所有可见的单元链接到所有隐藏单元,而且没有可见—可见或者隐藏—隐藏之间的链接。具体解释就是所有的隐藏层的输入都作为可见层的输入,所有可见层的输入都作为隐藏层的输入,那么在经过多层的RBM之后,如果最终得到的V1和V值近似相同,那么我们就可以到一个识别模型,通过在最高层加入监督学习进行最优权重的调整就可以得到一个比较完美的识别模型。
三、基于深度机器学习DBN算法的风险识别模型
在进行风险识别的机器学习模型训练中,传统的机器学习算法往往会遇到一个无法解决问题的,那就风险样本数据不足,能够提取的特征有限。因为在正常的生产环境中,无害数据远远大于有害数据,而基于统计学的传统机器学习算法只有在大量的、高质量的样本数据训练下才能得到比较理想的识别模型。基于深度机器学习DBN算法的风险识别模型的思想是使用可以使用有限无害数据进行训练,通过多层神经网络(RBM)的迭代来进行多维度、多层次的学习,这来快速的增加学习得到特征数量,这种通过RBM叠加进行贪婪逐层学习的方法在很多领域都取得了很好的效果。下图2是基于DBN算法风险识别的训练模型。

(图2)
在完成风险识别模型的训练后,就会形成一个稳定的神经网络。这个神经网络是会自动进行更新学习的,就像人在学习到新的之后会覆盖掉原来旧的或者错误的知识一样。完成训练的风险识别模型如下图3:
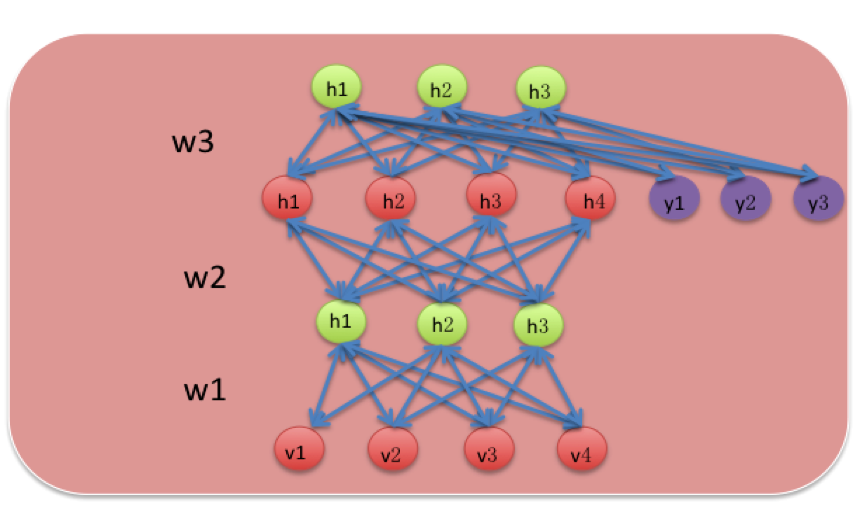
(图3)
其中y1,y2,y3是进行监督学习时的标签神经元,w1,w2,w3是经过监督学习的BP算法后得到的最优权重值,h1,h2,h3,h4则是隐藏层的神经元,v1,v2,v3,v4是可视化层的神经元。 经过训练的DBN神经网络就可以作为风险识别模型进行风险的识别,风险识别模型的工作流程如下图4:

(图4)
参考资料:
《Deep Learning(深度学习)学习笔记整理系列之常用模型(四、五、六、七)》: http://www.xuebuyuan.com/1541870.html
《Deep Learning(深度学习)学习笔记整理系列》: http://blog.csdn.net/zouxy09/a ... 75360
2016、1、19
赵英俊
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

