理解APACHE SOLR默认的评分机制
Apache Solr是基于Apache Lucene的企业级开源平台。希望通过本文你能了解Solr/Lucene的默认评分机制,以及哪些因子会影响搜索结果的排序。
首先看一下Lucene的评分公式,

以下是对公式中各个因子的详细解释 :
1. tf(t in d) 关联词出现的频率,词频率是指搜索词t 在文档d 中出现的次数。文档中搜索词出现次数越多总评分也就越高。tf(t in d)默认的实现是: ![]()
2. idf(t) 关联到反转文档频率,文档频率(docFreq)指出现过词 t的文档数量。docFreq 越少 idf 就越高(物以稀为贵)。idf(t)不但要反映词t在文档中的反转频率,还要反映词t在所有搜索词中的反转频率,所以你会在评分公式中看到idf(t)有个平方。idf(t)默认的实现是: 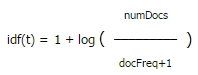
3. coord(q,d) 评分因子,是基于文档中出现查询词的个数。越多的查询词在一个文档中,说明些文档的匹配程序越高。默认是出现查询项的百分比。
4. queryNorm(q) 一个标准的查询因子,使不同查询之间可以比较。此因子不影响文档的排序,因为所有有文档都会使用此因子。queryNorm(q)默认的实现是: 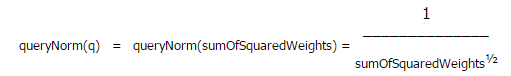
每个查询项权重的平分方和(sumOfSquaredWeights)由 Weight 类完成。例如 以下是BooleanQuery的计算公式: 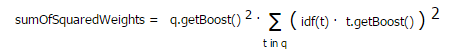
5. t.getBoost() 查询时,词t的加权值(如:jakarta^4 apache,其中词jakarta的加权值就是4),或者可以在程序中使用 setBoost()方法来给词加权。
6. norm(t,d) 封装索引期间的加权和长度因子(如果想忽略该因素,可以在schema.xml中定义字段时加上omitNorms=”true”属性),以下是关于加权和长度因子的解释:
· Field boost – 字段加权,在将字段内容索引到solr文档之前,通过调用 field.setBoost()为字段加权。
· lengthNorm(field) – 由字段中的 Token 的个数来计算此值,字段越短,评分越高。
以上所有因子相乘得出norm值,如果文档中有相同的字段,它们的加权也会相乘: 
索引的时候,把 norm 值压缩(encode)成一个 byte 保存在索引中。搜索的时候再把索引中 norm 值解压(decode)成一个 float 值。所以在真正搜索的时候,norm值是无法改变的。
Solr的默认评分算法可以满足大部分业务需求,如果你当前的业务需求非常复杂且默认算法无法满足,你也可以自定义评分算法,具体实现本文暂不做介绍。
参考资料料: https://lucene.apache.org/core/4_6_0/core/org/apache/lucene/search/similarities/TFIDFSimilarity.html
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

