Hacking Team流量攻击之EXE攻击分析
*本文原创作者:LiukerTeam
0×01 前言
IPA并不是Apple程序应用文件iPhoneApplication的缩写,而是Injection Proxy Appliance的缩写,Injection Proxy Appliance是Galileo Remote Control System(伽利略远程控制系统,简称RCS)的一部分,其主要作用是:
IPA是Hacking Team RCS系统用于攻击的安全设备,并且其中使用中间人攻击技术和streamline injection机制,它可以在不同的网络情况下透明地进行操作,无论是在局域网还是内部交换机上。 IPA还可从监控的网络流量中检测HTTP连接,对其进行中间人攻击,主要有三种攻击方式:注入HTML、注入EXE和替换攻击。当监控的HTTP连接命中预先设置的规则时,IPA将执行注入攻击。IPA 可以设置需要注入的用户(如IP地址),资源(如可执行文件)等规则。
可以设置需要注入的用户(如IP地址),资源(如可执行文件)等规则。
上一篇文章《中间人攻击之html注入》中,已分析了IPA的三大攻击方式之一的html注入攻击。本文重点分析其EXE注入的攻击方式。
0×02 攻击原理
基于HTTP/1.0协议的客户机和服务器信息交换的过程包括四个步骤:
(1)建立连接; (2)发送请求; (3)回送响应信息; (4)关闭连接。
IPA通过代理的模式从监控网络流量中检测HTTP连接,并劫持HTTP连接的Http Header,通过修改Http Header内容实现攻击,其攻击流程如图1。
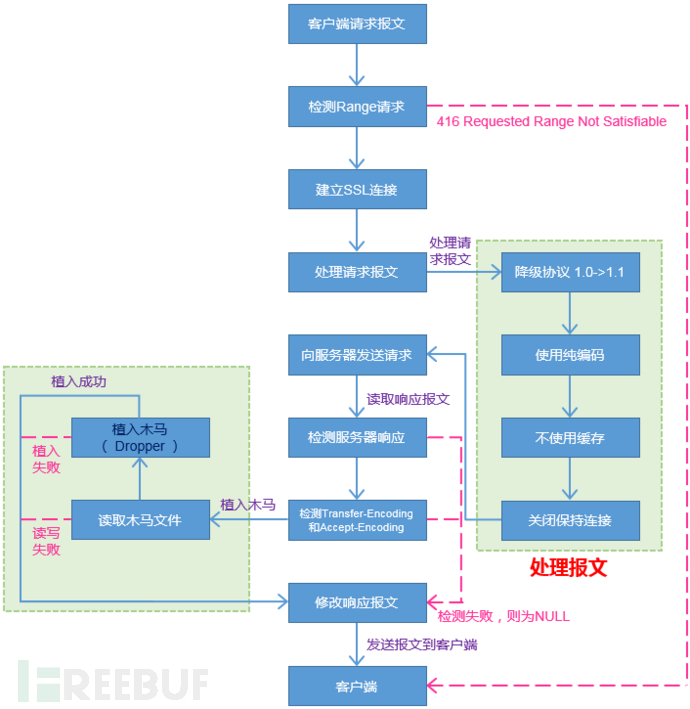
图1 EXE注入攻击过程
从图1中可知,exe注入攻击的最主要的两个步骤就是处理请求报文和植入木马。下面将重点分析一下这两步。
0×03 前期处理请求报文
1、检查客户端是否执行范围请求
Range头域可以请求实体的一个或者多个子范围。所以,必须先检查客户端发送的 HTTP 数据流包含一个“范围”请求,我们希望的是其不包含“范围”请求,因为我要对报文进行修改,修改之后肯定大小就变化了。如果其包含了“范围”请求的话,则直接返回以下报文(http reply header):
HTTP/1.1 416 Requested Range Not Satisfiable Content-Type: text/html Connection: close
也就是416错误。解决了“范围”请求之后,接着就是跟服务器完成一次握手,并建立SSL连接。
2、跟服务器完成一次握手,并建立SSL连接
检测“范围”请求之后,如果不存在“范围”请求的话,则需要跟服务器进行握手,并建立SSL连接。在这之前需要设置BIO的服务器和服务器端口号,如下:
/* retrieve the host tag */ host = strcasestr(header, HTTP_HOST_TAG); if (host == NULL) return -EINVALID; SAFE_STRDUP(host, host + strlen(HTTP_HOST_TAG)); /* trim the eol */ if ((p = strchr(host, '/r')) != NULL) *p = 0; if ((p = strchr(host, '/n')) != NULL) *p = 0; /* connect to the real server */ *sbio = BIO_new(BIO_s_connect()); BIO_set_conn_hostname(*sbio, host); // BIO_set_conn_port(*sbio, "http");
如果能过顺利完成握手的话,则继续下一步,否则就返回 -ENOADDRESS (错误码5)。
0×04 处理请求报文
1、将HTTP协议从1.1降到1.0以避免分块编码和其他问题
首先,HTTP/1.0和HTTP/1.1的其中一个区别就是:
(1)HTTP 1.0规定浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接,服务器完成请求处理后立即断开TCP连接,服务器不跟踪每个客户也不记录过去的请求。如图2所示。

图2 HTTP/1.0连接
(2)HTTP 1.1支持持久连接,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟。一个包含有许多图像的网页文件的多个请求和应答可以在一个连接中传输,但每个单独的网页文件的请求和应答仍然需要使用各自的连接。如图3所示。
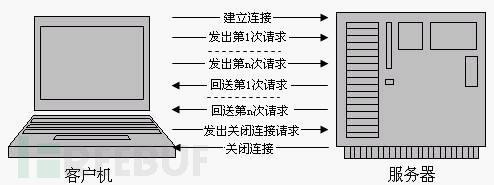
图3 HTTP/1.1连接
因为http注入不需要使用持久性连接,所以我们需要修改它为HTTP/1.0协议,这样做的话可以避免分块编码和其他一些问题。
2、强制使用纯编码,以避免任何类型的压缩
请求报文中Accept-Encoding是浏览器发给服务器,声明浏览器支持的编码类型的。
常见的有:
Accept-Encoding: compress, gzip //支持compress 和gzip类型 Accept-Encoding: //默认是identity Accept-Encoding: * //支持所有类型 Accept-Encoding: compress;q=0.5, gzip;q=1.0//按顺序支持 gzip , compress Accept-Encoding: gzip;q=1.0, identity; q=0.5, *;q=0 //按顺序支持 gzip , identity
为了后面更好的修改响应报文,需要将Accept-Encoding设置为none,这样可以避免任何类型的压缩,源码如图4所示。

图4 设置Accept-Encoding为none
3、不使用缓存(避免服务器返回304响应)
不使用缓存就是为了更好的得到新的文件,需要删除Cache 头域中的If-Modified-Since和If-None-Match,如图5所示。
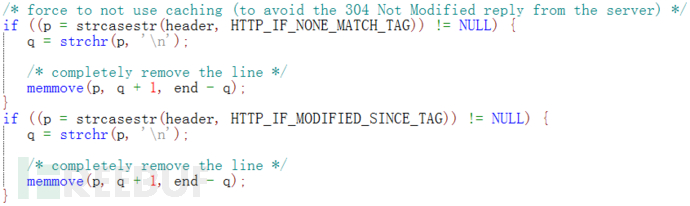
图5 删除Cache 头域中的If-Modified-Since和If-None-Match
If-Modified-Since
把客户端端缓存页面的最后修改时间发送到服务器去,服务器会把这个时间与服务器上实际文件的最后修改时间进行对比。如果时间一致,那么返回304,客户端就直接使用本地缓存文件。如果时间不一致,就会返回200和新的文件内容。客户端接到之后,会丢弃旧文件,把新文件缓存起来,并显示在浏览器中。如图6所示。

图6 If-Modified-Since
If-None-Match
If-None-Match和ETag一起工作,工作原理是在HTTP Response中添加ETag信息。 当用户再次请求该资源时,将在HTTP Request 中加入If-None-Match信息(ETag的值)。如果服务器验证资源的ETag没有改变(该资源没有更新),将返回一个304状态告诉客户端使用本地缓存文件。否则将返回200状态和新的资源和Etag。如图7所示。

图7 If-None-Match
4、关闭保持连接
我们都知道Connection: keep-alive和Connection: close的区别:
Connection: keep-alive
当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接。
Connection: close
代表一个Request完成后,客户端和服务器之间用于传输HTTP数据的TCP连接会关闭, 当客户端再次发送Request,需要重新建立TCP连接。
前面我们将HTTP协议从1.1降到1.0,为了请求报文中可能存在Connection: keep-alive而导致后面修改响应报文时出问题。
这样我们就把请求报文修改完成了,接着就是向服务器发送请求啦~
/* send the request to the server */ BIO_puts(*sbio, header);
0×05 读取和检测响应报文
在前面我们把修改之后的请求报文发送到服务器,这样服务器也回复了响应报文。那接下来的就是读取响应报文和检测响应报文的有效性。
1、读取响应报文
通过BIO的 int BIO_read(BIO *b, void *buf, int len) 函数读取响应报文并存储到BIO中,如下:
/* read the reply header from the server */ LOOP{ len = BIO_read(*sbio, data + written, sizeof(char)); //响应报文的长度 if (len <= 0) break; written += len; //记录报文的长度 if (strstr(data, CR LF CR LF) || strstr(data, LF LF)) break; } 2、检测客户端是否请求成功
在读取报文之后,必先检测客户端的请求报文是否请求成功,如果请求失败的话,就完全不能进行木马注入,所以返回BIO_new(BIO_f_null())。所以这也是至关重要的一步。如果请求成功的话,在响应报文中必定会有 HTTP/1.0 200 OK 或者 HTTP/1.1 200 OK 状态码。
/* if the reply is OK */ if (!strncmp(data, HTTP10_200_OK, strlen(HTTP10_200_OK)) || !strncmp(data, HTTP11_200_OK, strlen(HTTP11_200_OK))) { ....//省略 } else { DEBUG_MSG(D_INFO, "Server [%s] reply is not HTTP 200 OK", host); DEBUG_MSG(D_EXCESSIVE, "Server reply is:/n%s", data); /* create a null filtering bio (send as it is) */ fbio = BIO_new(BIO_f_null()); } 其中状态码 200 表示“请求已成功,请求所希望的响应头或数据体将随此响应返回。”。
3、检测响应报文的编码格式
通常,HTTP协议中使用Content-Length这个头来告知数据的长度。然后,在数据下行的过程中,Content-Length的方式要预先在服务器中缓存所有数据,然后所有数据再一股脑儿地发给客户端。
如果要一边产生数据一边发给客户端或者大小不确定情况下,WEB 服务器就需要使用"Transfer-Encoding: chunked"这样的方式来代替Content-Length。表明采用chunked编码方式来进行报文体的传输。chunked编码的基本方法是将大块数据分解成多块小数据。
但是,我们是要在响应报文中做注入,所以,不能让“Transfer-Encoding: chunked”出现。
Accept-Encoding是告知服务器采用何种压缩方式。
例如:客户端发送以下请求头:
Accept:*/* Accept-Encoding:gzip,deflate,sdch
Accept:*/* 表示它可以接受任何 MIME 类型的资源
Accept-Encoding:gzip,deflate,sdch 表示支持采用 gzip、deflate 或 sdch 压缩过的资源
很显然,我们不希望响应报文中的资源是压缩过的。强制使用纯编码,以避免任何类型的压缩。
4、检测响应报文是否为二进制数据
我们检测了传输编码之后,接下来要检测响应报文中的Content-Type。Content-Type是HTTP响应/POST头中重要的内容,用于定义网络文件的MIME类型和网页的编码。一般浏览器会根据Content-Type来决定如何处理返回的消息体内容,例如直接显示或者调用关联程序。
Wireshark中使用过滤语句http.content_type过滤出包含Content-Type的http数据包,如图8所示。

图8 Wireshark中Content-Type的http数据包
Content-Type有下面的形式:
Text:用于标准化地表示的文本信息,文本消息可以是多种字符集和或者多种格式的; Multipart:用于连接消息体的多个部分构成一个消息,这些部分可以是不同类型的数据; Application:用于传输应用程序数据或者二进制数据; Message:用于包装一个E-mail消息; Image:用于传输静态图片数据; Audio:用于传输音频或者音声数据; Video:用于传输动态影像数据,可以是与音频编辑在一起的视频数据格式。
为了后期对报文的修改,所以我希望响应报文是二进制的数据报文。如果不是二进制数据的话,则如下:
if (!strcasestr(data, "Content-Type: application/")) { DEBUG_MSG(D_INFO, "Not a binary stream, skipping it"); /* create a null filtering bio (send as it is) */ fbio = BIO_new(BIO_f_null()); } 到这里,对响应报文的检测工作基本上结束了。
0×06 木马植入
前面,我们修改了请求报文,也读取了和检测了响应报文,接下来就最关键的一步了,也就是说,万事俱备只欠东风。那么东风又是啥呢?对的,就是植入木马。但是…木马又如何注入呢?
现在我们要做的是植入木马,但是木马文件到底存不存在呢?对的,在植入之前,我们需要对其木马文件进行检测。
1、木马文件的检测
在vector-dropper项目中,我发现了名为cooker的项目。对的,这个就是我们写好的加工木马,如图9所示。但是,但是我又发现,这个源码是基于Boost库的。
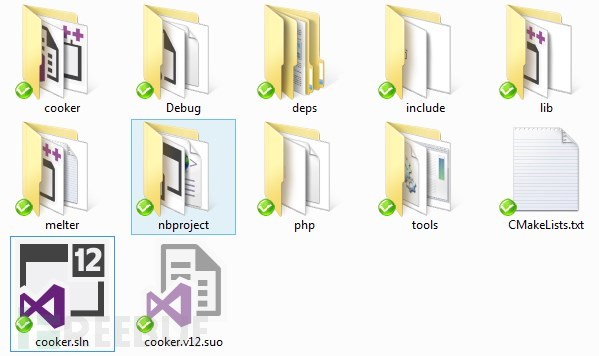
图9 Cooker源码
编译通过后会生成一个后缀为.cooked的文件。如图10所示。
图10 .cooked木马文件
2、植入木马
接下来就是最最关键的一步了,也是最复杂的一步。
(1)检测MELTER库文件是否存在
我们结合OpenSSL库的BIO对木马进行植入,因为木马植入程序已生成为静态库文件。所以,我们需要对库文件是否存在进行检测。
#ifdef HAVE_MELTER fbio = BIO_new_injector(path); BIO_ctrl(fbio, BIO_CTRL_SET_DEBUG_FN, 1, debug_msg); DEBUG_MSG(D_INFO, "BIO filter instantiated..."); #else DEBUG_MSG(D_ERROR, "ERROR: we don't have the melter lib!!!"); fbio = BIO_new(BIO_f_null()); #endif
其中宏HAVE_MELTER的定义如下:
/* whether we have the melter or not */ #define HAVE_MELTER 1
不难看出BIO_new_injector函数在MELTER库的接口。
(2)通过BIO链实现木马的植入
在melter.h头文件中找到了BIO_new_injector函数的声明,并且在BIO_melt.cpp中找到相应的BIO_new_injector函数的定义。其定义如下:
BIO* BIO_new_injector(char* file); BIO_METHOD* BIO_f_inject(void) { return (&method_injectf); } BIO* BIO_new_injector(const char * file) { BIO* bio = NULL; try { bio = BIO_new(BIO_f_inject()); StreamingMelter* sm = (StreamingMelter*) bio->ptr; sm->initiate(); sm->setRCS(file); //printf("BIO INJECT: %s/n", file); } catch (std::runtime_error& e) { printf("RUNTIME ERROR: %s/n", e.what()); bio = BIO_new(BIO_f_null()); } catch (...) { printf("UNKNOWN ERROR!/n"); bio = BIO_new(BIO_f_null()); } return bio; } 通过分析,发现通过BIO_f_inject()创建了一个新的BIO对象,而BIO_f_inject()实际上只是返回一个BIO链,BIO链的属性如下:
BIO_METHOD method_injectf = { BIO_TYPE_INJECT_FILTER, "RCS Inject filter", injectf_write, injectf_read, injectf_puts, injectf_gets, injectf_ctrl, injectf_new, injectf_free, injectf_callback_ctrl, }; 先解释一下,何为BIO链?我们都知道单个的BIO就是一个环节的BIO链的特例。一个BIO链通常包括一个source/sink型BIO和一个或多个filter型BIO,数据从第一个BIO读出或写入,然后经过一系列BIO变化到输出(通常是一个source/sink BIO)。
也就是上述的BIO链通过injectf_write、injectf_read等一些列的操作来完成木马的植入。
(3)StreamingMelter类
上述,通过StreamingMelter* sm = (StreamingMelter*) bio->ptr创建一个新的StreamingMelter对象,在injectf_new()中bio->ptr = new StreamingMelter(),具体的操作说白了也就是在StreamingMelter类中的构造函数中,其构造函数如下:
StreamingMelter() : done_(false), currentOffset_(0), idleToOffset_(0) { textSection_ = pe().sections.end(); dropper_.reset(); buffer_.reset(new Chunk()); output_.reset(new Chunk()); } 分析一下setRCS(const char* file)函数,定义如下:
void StreamingMelter::setRCS(const char* file) { DEBUG_MSG(D_INFO, "using backdoor %s", file); try { RCSDropper* dropper = new RCSDropper(file); dropper_.reset(dropper); } catch (InvalidCookerVersion& e) { DEBUG_MSG(D_WARNING, "%s has been cooked with RCSCooker version %s, required version is %s", file, e.effective().c_str(), e.required().c_str()); throw parsing_error(e.what()); } catch (std::runtime_error& e) { throw parsing_error(e.what()); } DEBUG_MSG(D_DEBUG, "raw dropper size ... %d", (DWORD)dropper_->size()); } 其中的dropper_.reset(dropper),dropper_是一个boost::shared_ptr<Dropper>的智能指针,这里就是把dropper的值给dropper_。
(4)RCSDropper类
通过分析StreamingMelter::setRCS(const char* file),发现其中调用了RCSDropper类。
RCSDropper::RCSDropper(const char* filepath) { // calculate final size bf::path p = filepath; if (!bf::exists(p)) throw std::runtime_error(filepath); std::size_t fileSize = bf::file_size(filepath); //size_ = fileSize + 8192; size_ = fileSize + 16384; // create buffer and zero it out data_.insert(data_.begin(), size_, 0); // calculate all offsets offset_.restore = 0; offset_.header = std::max<std::size_t > (restoreStub(0), 32); DEBUG_MSG(D_DEBUG, "Size of restore stub: %d", offset_.header); // XXX magic number! DEBUG_MSG(D_DEBUG, "Offset to header: %d", offset_.header); offset_.stage1 = offset_.header + fileSize; loadFile(filepath); if (verifyCookerVersion() == false) { std::string version = header()->version; if (version.empty()) version = "<unknown>"; throw InvalidCookerVersion(version, printable_required_cooker_version); } //generateKey(); //encrypt(); } 在这之前,我们先来看一下offset_的数据结构:
struct { std::size_t restore; std::size_t header; std::size_t stage1; } offset_; 通过restoreStub来获取offset_.header,其中使用了 kobalicek 大神的开源库 asmjit (下载地址: https://github.com/kobalicek/asmjit ),asmjit这个库主要是可以将代码即时的编译成机器码,也就是所谓的jit技术。
最后就是加载木马文件。
(5)读取PE结构并修改
在前面,我介绍了BIO链,对的,BIO链通过injectf_write、injectf_read等一些列的操作从而实现木马的植入。
其中使用了 BeatriX 大神的 BeaEngine 开源库(下载地址: https://github.com/BeaEngine/beaengine ),它是一个同时支持i386/AMD64且跨平台的反汇编引擎。
到这里,木马的植入也基本上讲完了。如果感兴趣的同学,可以去研究一下Pe的修改。
0×07 总结
我们从请求报文的前期处理的检测客户端的执行范围请求、跟服务器建立连接,再到请求报文的降协议、修改Accept-Encoding、修改为不使用缓存、关闭保持连接。接着就是读取响应报文、检测客户端是否能够请求成功、检测响应报文的编码格式、检测响应报文是否为二进制数据的响应报文的读取和检测。最后就是木马文件的检测和木马的植入。
这一系列的操作,我们就可以完成exe注入攻击。敬请期待“替换攻击”。。。
*原创作者:LiukerTeam,本文属FreeBuf原创奖励计划文章,未经许可禁止转载
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

