我们是如何优化英雄联盟的代码的
原文链接: RANDOM ACTS OF OPTIMIZATION
译者:杰微刊--张帆

对于像英雄联盟这样不断演进的产品的开发者而言,需要不断的致力于与系统的熵作斗争,因为他们将越来越多的内容添加到资源有限的服务器中。新的内容带了新的隐性成本——不仅是更多的实施成本,同时也包括由于创造了更多的纹理、仿真和处理造成的内存和性能成本。如果我们忽略(或者错误估算)了这些成本,则整体游戏性能不佳,可玩性减少。故障使人厌恶,延迟使人愤怒,帧率下降让人沮丧。
我是致力于提高英雄联盟性能团队中的一员。我们为客户端和服务器做快照,发现问题 (性能相关和其他),然后修复问题。同时,我们将在这个过程中学到的东西反馈其他团队,并且给他们提供工具,使他们在影响用户之前来检测并定位他们自己的性能问题。我们不断的提高英雄联盟的性能为艺术家和设计师添加新的东西提供了空间:当他们使游戏更庞大更优秀的同时,我们使之更快。
这是关于我们团队如何优化英雄联盟性能系列的第一篇文章,后续我们将不断持续更新。这是一项回报丰厚的挑战,这篇文章将深入介绍我们在粒子系统中遇到的一些有趣的挑战——正如在下图中,你可以看到粒子系统在游戏中扮演了十分重要的角色。

上图是在英雄联盟游戏中高粒子密度的一个例子。
优化,并不是在程序集中重写大量的代码——尽管有些时候是这样的。我们仅变更那些不仅能够提高性能,而且维护正确性的代码,如果有可能的话,还会提高代码质量。最后一项略显挑剔:任何不易读、不易维护的代码都会产生技术债务,这个我们稍后再谈。
优化已有的代码库,我们采用了三个基本步骤:鉴别、理解和迭代。
-
步骤一鉴别
在开始之前,我们首先需要确认哪些代码需要进行优化。即使有些代码看起来明显性能较差,但是由于其对整体性能影响极小,优化这类代码收益极少(尤其当花费在上面的时间和精力在其他方面可以做到更好的收益)。我们使用代码检测工具和采样分析器来帮助识别非性能部分的基本代码。
-
步骤二理解
一旦我们得知代码库的哪部分代码性能较差,我们便会详细的查看这部分代码以求完全理解代码。理解代码意味着理解这些代码的含义及原本的目的。接着,我们就能知悉为何这些代码产生瓶颈了。
-
步骤三迭代
当我们理解了为何特定部分代码执行较慢及代码本意要执行的内容,我们就有了足够的信息来设计和开发一套可行的解决方案。使用鉴别步骤中的工具和得到的快照数据,我们将新代码和旧代码的性能做了比较。如果解决方案效果出众,我们会彻底的进行测试以确保不引入来新的bug,那么接下来就可以击掌庆贺了,因为我们已经为其他内部测试做好了充分的准备。在大多数情况下,新的代码不见得足够快,所以我们不断迭代解决方案,知道新的代码能达到优化的目的。
现在,让我们看下在英雄联盟代码库中这几个步骤的实施细节,并以最近优化的粒子系统逐步介绍。
步骤1:鉴别
拳头的工程师使用大量的分析工具来检查游戏客户端和服务器的性能。我们先查看来自客户端的帧率和通过Waffles得到的高级分析信息(通过工具的特定函数获得的输出信息),这个内部工具可以让我们在内部构建的客户端与服务器保持联通。此外,Waffles还具备其他功能,如在测试过程中触发调试、检查游戏内部数据如导航分格和暂停或者减缓游戏过程。
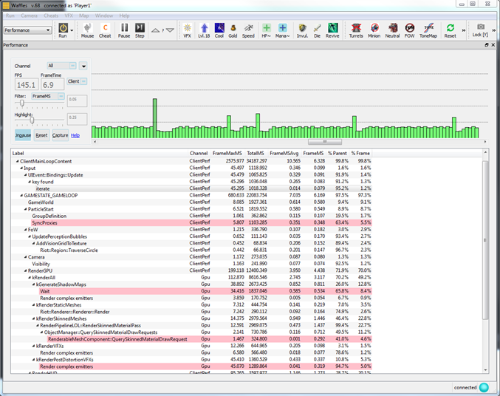
Waffles截图
Waffles提供了一个实时展示界面,并提供详细的性能信息。上图是Waffles如何展现客户端性能表现的经典例子,上边图形(绿色柱状图)以毫秒为单位表示了帧率——越高的柱状图表示越低的帧率。非常慢的帧率在游戏中是可以感受得到的。柱状图下面是重要功能的分层视图,通过点击任何绿色柱状图,工程师都会看到影响该帧率的详细信息。通过这里,我们可以看出些端倪,即哪部分代码运行时导致性能较差的关键。
我们使用一个简单的宏在代码库内手工检测一些重要函数来提供这份性能相关的信息。在对外发布的游戏版本中,这个宏并没有被打包编译,但在测试版本打包中,这个宏作为一个很小的class存在,它创建了一个事件,存放于配置文件缓冲区。该事件包含一个字符串识别码、一个线程ID、一个时间戳和其他必要的信息(比如它还可以存储在其生命周期内所有发生的内存配置数)。当对象超出范围后,析构器会在配置缓冲区中更新该事件自构造以来的运行时间。在随后的时间,可以输出和解析此配置文件缓冲区——理想的情况是在另一个进程进行以尽量减少对游戏本身的影响。
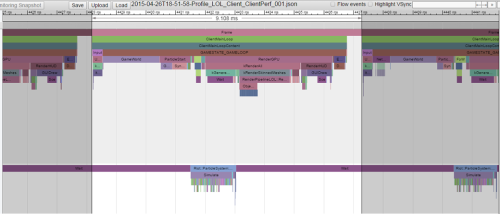
在这个例子中,我们将分析缓冲区输出到文件,并且读入到构建在Chrome浏览器中可视化工具中(关于跟踪工具的更多信息,可以点击这里,你可以在自己的Chrome浏览器中通过在地址栏敲入"chrome://tracing/"进行尝试。这个扩展程序被设计用来进行网页性能分析,输入格式是JSON,所以你可以轻松的根据你自己的数据构造输入)。通过图形化后的结果,我们可以看到哪些是执行较慢的函数,或者在那里不断有大量的小函数被调用:这些都是次优代码的迹象。
让我来展示详细操作:上面的视图是Chrome Tracing的视图,图中展示了客户端上两个运行的线程。上部分的是主线程,执行大多数的处理工作,底部的是粒子线程,用来执行粒子处理。每一个着色的横条均对应一个函数,横条的长度指示了其执行时间。被调用的函数由竖直栈结构展示,父函数在子函数之上。这个工具提供给我们一种非常神奇方式来可视化执行复杂度以及帧的签名时间。当我们发现一个次优代码区域,我们可以放大粒子区域以求查看更多细节.
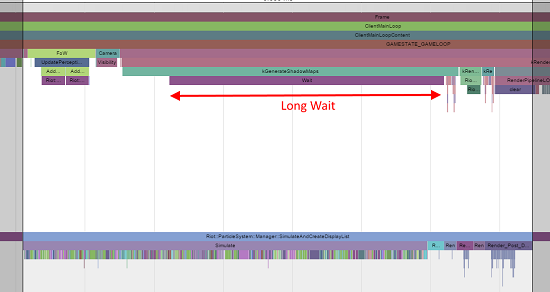
Chrome Tracing放大效果图
让我们放大图形中间部分。从上面的线程中我可以看到一个非常长的等待,只有当下面的粒子模拟函数执行完毕才结束。模拟功能包含大量不同函数(着色的横条)的调用。每一类都是粒子系统的更新功能,用于将位置、 方向和每个粒子在该系统中其他可见性状态进行更新。一个明显的优化方式是将模拟函数改造成多线程方式,即可运行在主线程中,也可以在粒子线程中执行,对于本例,我们仅关注优化模拟代码本身。
既然现在我们知道去何处查看性能问题,我们可以切换到样本分析。这类分析周期性的读取和存储程序计数器和运行中的进程的栈信息(可选)。一段时间后,这个信息可以给出一个随机概述,概述中描述了代码库内的耗时。较慢的函数会得到更多的样本,更有用的是,用时最长的单个函数会累积更多的样本。在这里,我们不仅可以看到哪些函数执行最慢,同时可以看到哪几行代码执行最慢。如今有很多不错的样本分析工具可供选择,从免费的Very Sleepy到更多特性支持的商业软件,如Intel的VTune。
通过在游戏客户端上运行VTune来检查粒子线程,我们可以看到如下列表中运行最慢的函数。
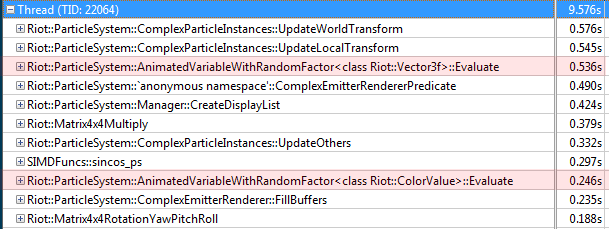
VTune中的Hot Functions
上面的表格展现了一些粒子相关的函数。作为参考,最上面两个较大的函数用于为每个粒子更新矩阵和位置、方向相关的状态。举例来说,我们来看在第三和第九项AnimatedVariableWithRandomFactor<>中的Evaluate函数,函数很小(并且容易理解),但是相对而言比较耗时。
步骤2:理解
现在,我们选择了一个需要优化的函数,则需要理解这个函数要做的事情和为什么这么做的原因。在本例中,AnimatedVariables被英雄联盟美术师用来定义粒子特征是如何随着时间变化。一旦一个美术师为一个特定的粒子可见性指定关键帧值后,代码中便会插入这些数据来产生一条曲线。插值方法是线性插值或一阶或二次集成。动画曲线被大量的使用——尽在召唤师峡谷(译者注:英雄联盟的地图之一,也是最热门的地图)中就有接近40000的动画曲线——涵盖了从粒子颜色扩展到旋转速度方方面面。Evaluate函数在每场游戏中会被调用数以亿计次。此外,LOL中的粒子系统是游戏体验中很重要的一部分,所以它们的行为不能做出任何改变。
这个类其实已经做过了优化,通过查表的方式,对每个timestep所需要的值都预先计算过并存储在一个数组中,所以在读取这些数值时不必再次计算,所以减少了计算的耗时。这是一个明智的选择,因为曲线的一阶和二次集成是一个昂贵的进程。为每个系统中的每个粒子上的动画变量进行这个操作会使得处理过程大大减少。
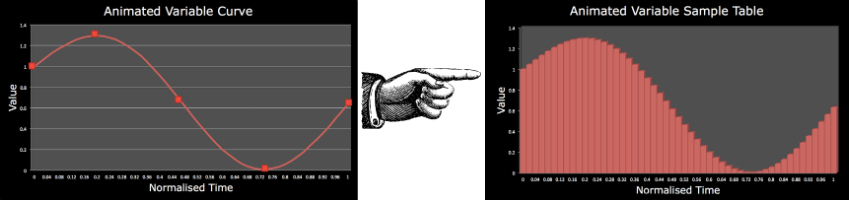
动画变量曲线的查询表
在查询性能问题时,通过找到最坏的场景来放大问题往往是一个十分有用的技巧。为了模拟粒子处理减缓,我开始了一场单个玩家的游戏,游戏中有9个中期级别的电脑,并且在下路挑起了一场混乱的团战。接着,我在团战期间在客户端上运行了VTune,记录了大量的数据用于分析。这些数据给出了在Evaluate代码中的归因样本(如下图所示)。
下图中我截取了第91-95行代码,为了更好的说明第90行调用Evaluate的情形。

VTune中的分析样本
对于不熟悉VTune的人来说,其实这个试图展示的就是解析期间所收集的代码。右侧的红色横条指示了命中次数,横条越长就意味着命中次数越多,而命中次数越多表示这一行执行越慢。挨着横条的时间是处理这行代码所用的预估时间。你也可以就某个特定函数的到一个准确视图来查看是什么因素“贡献”了执行缓慢。
如果就红色的横条来看,第95行代码就是问题所在。但是这段代码所做的仅仅是在Vector3f中复制出拼写错误的查询表,为什么这个函数成为最慢的部分呢?为什么12字节的复制这么慢?
答案在于现代CPU访问内存的方式中。CPU非常忠实的遵循了摩尔定律,每年都会提速60%,而内存速度每年的增速只有可怜的10%。

图出自《计算机体系结构:量化研究方法》By John L. Hennessy, David A. Patterson, Andrea C. Arpaci-Dusseau
缓存可以减小性能差距,运行英雄联盟的大多数CPU都有3级缓存,一级缓存最快但容量最小,三级缓存最慢但容量相对最大。从一级缓存读取数据只需要4个周期,而读取主内存却需要大约300个周期甚至更多。你可以在300个周期内做大量处理工作。
最初查询表的解决方案的问题在于,虽然从查询表中的顺序读取值的操作是非常快的(由于硬件预取),但是我们正在处理的颗粒并不是按照时间顺序存储,所以实际查找顺序是随机的。这通常会导致CPU等待从主存储设备读取数据时产生延迟。虽然300个周期比一级或者二级集成代价更低,但我们还是需要知道这个函数在游戏中的使用频率如何,因为毕竟这个函数在游戏中被大量的使用。
为了探求真相,我们在代码中添加一些额外的内容来收集AnimatedVariables的数量和类型。结果表示,在38000个AnimatedVariables中:
①37500个是线性插值;100个是一级,400个是二级②31500个仅有一个关键值;2500个有3个关键值;1500有2个或者4个关键值
所以最常见的途径是针对单键值。因为代码总是生成查询表,这就产生了一个不需要传播的单数值表。也就意味着每次查询(总是返回相同值)一般会产生缓存丢失,进而导致大量的内存和CPU周期浪费。
通常来讲,代码成为瓶颈一般有四个原因:
1、调用频率过高
2、算法选择不佳:如O(n^2)vsO(n)
3、做了不必要的工作或者太频繁的执行必要的操作
4、数据较差:或者是数据量太大,或者是数据分布和访问模式较差
这里产生的问题原因不是由于代码设计不好或者开发质量导致。解决方案是好的,但是在被美术师大量使用之后,普通路径是针对单值的,而这些简单的问题在使用过程中是很不明显的。
顺便说一句,我学会了作为一名程序员最重要的事情之一便是尊重你正在处理的代码。代码有可能看起很疯狂,但是这样写的目的可能是基于一个好的出发点。在没有完全理解代码如何使用和其为何设计之前不要错误的认为这些代码是丑陋愚蠢的。

来自:http://codesoftly.com/2010/03/ha-code-entropy-explained.html
步骤3 迭代
现在我们了解了哪部分代码执行较慢、这部分代码本意是什么和为何执行较慢,是时候开始构想解决方案了。每个常见的执行路径都是为单独变量设计,我们还知道数量少的键的线性插值非常快(在少量高速缓存中作简单的计算),所以我们需要在考虑这种情况的基础上进行重新设计。最后,我们可以回到前面罕见集成曲线的预计算查询表上。
在某些情况下,当我们不使用查询表时,首先构造这些表是没有意义的,所以会释放大量意义非凡的内存(大多数表具有256个条目或者更多,每个条目可达12字节的大小,这相当于大约每张表3kb)。所以现在,我们可以使用额外的一些内存来添加缓存的条目和存储的单值的数量。
之前的代码看起来是这个样子的:
templateclass AnimatedVariable { //private: std::vectormTimes; std::vectormValues; }; templateclass AnimatedVariablePrecomputed { //private: std::vectormPrecomutedValues; }; AnimatedVariablePrecomputed对象在AnimatedVariable中进行构造,从它的指定大小插值和构建一个表。Evaluate()仅在预计算对象中被调用。我们修改了一下AnimatedVariable类,现在看起来是这个样子的:
templateclass AnimatedVariable { //private: int mNumValues; T mSingleValue; struct Key { float mTime; T mvalue; }; std::vectormKeys; AnimatedVariablePrecomputed*mPrecomputed; }; 我们添加了一个缓存值mSingleValue,和一个整数mNumValues,用于告诉我们何时才使用mSingleValue。如果mNumValues是1(即对应单值的情况),Evaluate()会直接返回mSingleValue的值——不需要其他多余的处理。你还可以注意到插入时间和值构造的Key能够减少缓存未命中的情况。
指向此类的数据向量大小现在范围从24到36个字节不等,具体取决于模板类型(同时也依赖与平台,std::vector<>的大小也会不同)。
Evaluate()之前的代码看起来是这样子的:
templateT AnimatedVariablePrecomputed::Evaluate(float time) const { in numValues = mPrecomputedValues.size(); RIOT_ASSERT(numValues > 1); int index = static_cast(time * numValues); // clamp to valid table entry to handle the 1.0 boundary or out of bounds input index = Clamp(index, 0, numValues - 1); return mPrecomputedValues[index]; } 修改后的Evaluate()方法代码如下,这是在VTune中展示的。你可以看到三个可能的执行case:单值(红色部分),线性插值(蓝色部分)和预计算查询(绿色部分)。
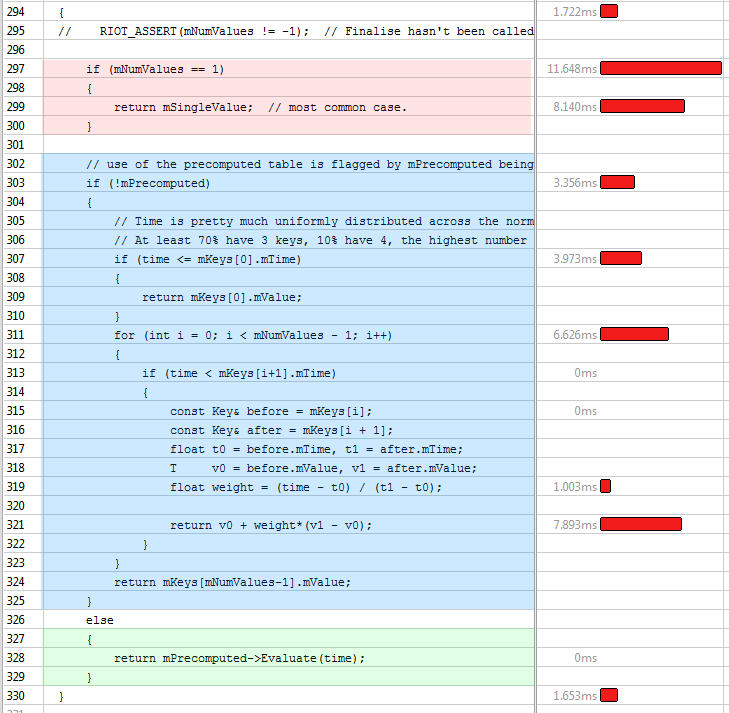
在VTune中展示的优化过的代码片段
修改后的代码执行速度大约快了3倍:在最慢的函数列表中该函数从第三位降到了第22位!不仅执行更快,同时还降低了内存的使用,大约减少了750kb。这还不算完,不仅函数执行更快,占内存更少,同时提高了线性插值的准确度。可谓一石三鸟。
这里并没有提到的内容(尽管文章已经足够长了)是我如何通过不断迭代找到了这个解决方案。我最初的尝试减少在粒子生命周期内样本表的大小。这个方案几乎有效——但有些移动较快的粒子由于样本表的减少,变的参差不齐。幸运的是,这个现象很快就被发现了,使得我依然能够将方案更换为本文中提到的方法。当然还有一些其他的代码修改,但是对于性能提高并没有直接效果,也有些代码的修改甚至造成了代码执行更慢。
总结
本文中介绍的是英雄联盟游戏代码库中代码优化的一个典型案例。虽然变动很小,但是这个改动使得内存节约了750kb,粒子线程比较之前运行快了1到2毫秒,这使得主线程执行的更快。
当程序员寻求优化的时候,虽然看似显而易见,但这里提到的三个阶段都常常会被忽视。这里只是为了强调一下:
1.鉴别:分析应用并找出性能最差的部分
2.理解:理解代码的本意和执行缓慢的原因
3.迭代:基于上面两个阶段的到的成果进行代码的修改、迭代,并重新分析。重复这三个步骤直到足够快。
上面提到的解决方案不见得是最快的解决方案,但至少方向是正确的——性能提升的安全路径是通过迭代改进。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

