基于动态混合高斯模型的商品价格模型算法
1. 背景
作为电子商务网站,淘宝网上的每个商品都有一个价格,该价格从一个很重要的维度上反应出一个商品的品质。但是由于该价格是由第三方卖家自己确定的,因此存在一定的随机性。一个价格过低的商品,其假货的可能性往往较大,比如500元的劳力士手表,或者商品的质量存在问题;同时一个价格过高的商品,可能会失去一个潜在的购买者,也可能会是卖家故意设置高价,以便用户按价格排序时展现在靠前的位置。
因此对一个商品当前价格的合理性进行判断,并根据该商品的属性给出其合理的价格区间,对于规范淘宝网的商品运营以及搜索结果展现方面都具有重要的作用。
2. 应用场景
本算法目前主要用于三个场景:
- 在搜索排序中,对于商品价格合理性极低的商品进行降权;
- 商品假货识别中,针对超低价商品判断其是否为假货;
- 商品品质项目中,根据商品的价格合理性作为商品品质分析的一个维度,从劣质、性价比等方面刻画一个商品的品质。
3. 技术方案
3.1 概述
本算法提出三个优化点来判断一个商品的价格合理性并给出一个合理的价格区间:
- 根据商品的属性对商品进行同款聚合,以同款商品为单位,对同款中商品的价格合理性进行判断;
- 使用近30天商品的成交价,同时以天猫、KA卖家等可信商家的商品价格作为训练数据;
- 基于训练样本动态地选择单高斯模型或双高斯模型,同时解决奇异值与过拟合问题,以提高准确率。
整体流程图如下所示:

3.2 详细流程
3.2.1. 获得同款数据
第一步是获取商品的同款信息,只有基于同款的情况下,才能利用大数据对商品的合理价格进行预测。目前使用到的同款数据主要有以下三个:
- 部分标类商品有spuid节点,spuid相同的商品为同一类
- 当前淘宝网上的找同款的数据
- 图像团队产出的同款数据
除此之外,我们还有基于商品重点属性的同款聚合的通用方法,以增加对商品的覆盖量。该方法通过设置类目下的重点属性,自动地根据这些属性对商品进行聚合成同款进行后续的计算。
3.2.2 训练样本集获取
获取了同款数据之后,需要从里面找到价格有问题的样本,首先需要获取其中可信任的样本,当前从三个维度获取可信样本:
- 以商品成交价作为训练样本,因此需要以同款为粒度获取该同款下过去30天内成交的商品的成交价,同时为了保证成交价的合理性,需要去掉其中识别出来的炒信、作弊等销量
- 取同款中天猫卖家的商品价格作为训练样本
- 取同款中KA卖家的商品价格作为训练样本
3.2.3 基于动态高斯模型的商品价格模型
在获取了同款下商品的训练样本之后,使用高斯模型获得其分布的均值、方差等信息。在本方法中对传统的高斯模型进行了两处优化:
- 根据样本分布情况去除奇异点;
- 根据数据样本情况动态选择单高斯或双高斯模型进行训练;
具体算法流程如下图所示:
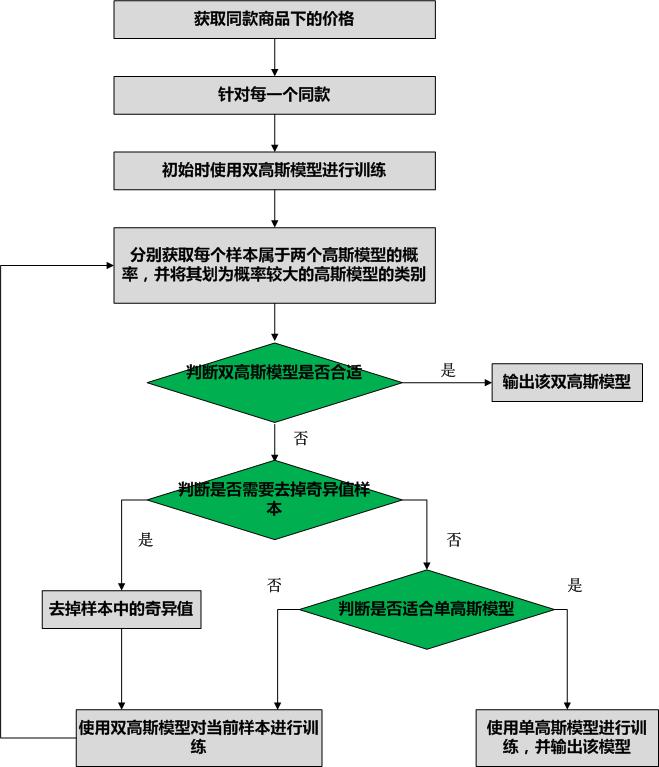
本算法中会首先使用双高斯模型计算出当前训练样本的分布情况,同时会根据具体的样本信息决定使用双高斯模型还是单高斯模型。
判断双高斯是否合适的方法:
判断是否使用单高斯模型的逻辑有两个
- 判断两个高斯模型的均值是否较为接近,若其比值大于某个阈值,比如均值分别为100与130的情况,则可以使用单高斯模型。同时还要判断其均值是否过于接近,如果过于接近,则合并为单高斯之后会造成数据过拟合的情况。因此需要对它们的均值之比设置一个上限与下限;
- 同时再设置两个高斯模型中样本点的数量之差的限制
去除奇异点方法:
去除奇异点的目的主要是为了解决当前同款数据中本身存在的噪声问题,让训练的样本更加收敛。主要方法是在双高斯模型情况下,若其中一个模型中的样本量过少,而另一个模型中的样本量很多,那么样本量少的可以作为奇异值进行去除。比如在同一款中,大量的价格聚集在100元,只有少量的价格聚集在20元,那么20元周围的样本可以作为奇异值进行去除。具体的阈值等信息根据情况进行设置。
通过该方法计算出每个同款下商品价格的分布情况,在预测时,可以直接通过查表的方式找到该同款下每个商品价格的合理性概率值。
4. 效果与后续计划
4.1 当前识别效果
当前价格模型的数据分别在 假货识别、商品品质、超低价商品降权 中得到应用。
- 具体在假货识别中,应用到了运动鞋类目、手表类目以及门票等类目下,目前已经通过价格的方式识别到有问题的商品X个,经过评测准确率达到98%。
- 在商品品质模型中,价格模型也应用于找到性价比更好的商品以及同款商品中价格不合理的商品,作为商品品质模型的一个特征。
4.2 后续计划
在价格模型后续的工作中,会从以下几个方面进行开展:
- 对当前价格模型的不断优化
- 假货识别中,从当前的几个类目扩展到更多的类目进行尝试
- 商品品质模型中,更好地利用好价格这一因素,开发出更多的模型,如商品性价比模型等
该文章来自于阿里巴巴技术协会( ATA )
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

