OpenStack 存储剖析
Openstack 通过 3 年多的发展,变得越来越庞大。这也是为了满足更多不同的需求,体现出开源项目灵活快速的特性。本文不是关于 Openstack 存储相关组件的配置,而是介绍 0penstack 存储入门的一些必要理论知识。
OpenStack 存储技术
OpenStack 其实有三个与存储相关的组件,这三个组件被人熟知的程度和组件本身出现时间的早晚是相符的,按熟悉程度排列如下:
Swift—提供对象存储(Object Storage),在概念上类似于 Amazon S3 服务,不过 swift 具有很强的扩展性、冗余和持久性,也兼容 S3 API。对象存储支持多种应用,比如复制和存档数据、图像或视频服务,存储次级静态数据,开发数据存储整合的新应用,存储容量难以估计的数据,为 Web 应用创建基于云的弹性存储。
Glance—提供虚机镜像(Image)存储和管理,它能够以三种形式加以配置:利用 OpenStack 对象存储机制来存储镜像;利用 Amazon 的简单存储解决方案(简称 S3)直接存储信息;或者将 S3 存储与对象存储结合起来,作为 S3 访问的连接器。OpenStack 镜像服务支持多种虚拟机镜像格式,包括 VMware(VMDK)、Amazon 镜像(AKI、ARI、AMI)以及 VirtualBox 所支持的各种磁盘格式。镜像元数据的容器格式包括 Amazon 的 AKI、ARI 以及 AMI 信息,标准 OVF 格式以及二进制大型数据。
Cinder--提供块存储(Block Storage),类似于 Amazon 的 EBS 块存储服务,OpenStack 中的实例是不能持久化的,需要挂载 volume,在 volume 中实现持久化。Cinder 就是提供对 volume 实际需要的存储块单元的实现管理功能。
Amazon 一直是 OpenStack 设计之初的假想对手和挑战对象,所以基本上关键的功能模块都有对应项目。除了上面提到的三个组件,对于 AWS 中的重要的 EC2 服务,OpenStack 中是 Nova 来对应,并且保持和 EC2 API 的兼容性,有不同的方法可以实现。
三个组件中,Glance 主要是虚机镜像的管理,所以相对简单;Swift 作为对象存储已经很成熟,连 CloudStack 也支持它。Cinder 是比较新出现的块存储,设计理念不错,并且和商业存储有结合的机会,所以厂商比较积极。
存储项目和组件对应关系如下面表格:
表 1.对应关系
OpenStack 对象存储—Swift
OpenStack Object Storage(Swift)是 OpenStack 开源云计算项目的子项目之一,被称为对象存储,提供了强大的扩展性、冗余和持久性。 Swift 并不是文件系统或者实时的数据存储系统,它称为对象存储,用于永久类型的静态数据的长期存储,这些数据可以检索、调整,必要时进行更新。Swift 前身是 Rackspace Cloud Files 项目,随着 Rackspace 加入到 OpenStack 社区,于 2010 年 7 月贡献给 OpenStack,作为该开源项目的一部分。Swift 目前的最新版本是OpenStack Havana。Havana 版本中 Swift 新增特性如下:
Multiple-Region-Replication:支持对象异地复制容灾。
Memcache:增加对轮询 Memcache 连接的支持。
More-Optimization:并发 IO 支持,多网段分流支持,在多地复制情况下加强不同 Proxy-Server 的亲和度。
Swift 特性
在 OpenStack 官网中,列举了很多 Swift 特性,其中最引人关注的是以下几点。
极高的数据持久性
一些朋友经常将数据持久性(Durability)与系统可用性(Availability)两个概念混淆,前者也理解为数据的可靠性,是指数据存储到系统中后,到某一天数据丢失的可能性。例如 Amazon S3 的数据持久性是 11 个 9,即如果存储 1 万(4 个 0)个文件到 S3 中,1 千万(7 个 0)年之后,可能会丢失其中 1 个文件。那么 Swift 能提供多少个 9 的 SLA 呢?下文会给出答案。针对 Swift 在新浪测试环境中的部署,他们从理论上测算过,Swift 在 5 个 Zone、5×10 个存储节点的环境下,数据复制份是为 3,数据持久性的 SLA 能达到 10 个 9。
完全对称的系统架构
“对称”意味着 Swift 中各节点可以完全对等,能极大地降低系统维护成本。
无限的可扩展性
这里的扩展性分两方面,一是数据存储容量无限可扩展;二是 Swift 性能(如 QPS、吞吐量等)可线性提升。因为 Swift 是完全对称的架构,扩容只需简单地新增机器,系统会自动完成数据迁移等工作,使各存储节点重新达到平衡状态。
无单点故障
在互联网业务大规模应用的场景中,存储的单点一直是个难题。例如数据库,一般的 HA 方法只能做主从,并且“主”一般只有一个;还有一些其他开源存储系统的实现中,元数据信息的存储一直以来是个头痛的地方,一般只能单点存储,而这个单点很容易成为瓶颈,并且一旦这个点出现差异,往往能影响到整个集群,典型的如 HDFS。而 Swift 的元数据存储是完全均匀随机分布的,并且与对象文件存储一样,元数据也会存储多份。整个 Swift 集群中,也没有一个角色是单点的,并且在架构和设计上保证无单点业务是有效的。
简单、可依赖
简单体现在架构优美、代码整洁、实现易懂,没有用到一些高深的分布式存储理论,而是很简单的原则。可依赖是指 Swift 经测试、分析之后,可以放心大胆地将 Swift 用于最核心的存储业务上,而不用担心 Swift 捅篓子,因为不管出现任何问题,都能通过日志、阅读代码迅速解决。
Swift 架构概述
Swift Architectural主要有三个组成部分:Proxy Server、Storage Server 和 Consistency Server。其架构如图 1 所示,其中 Storage 和 Consistency 服务均允许在 Storage Node 上。Auth 认证服务目前已从 Swift 中剥离出来,使用 OpenStack 的认证服务 Keystone,目的在于实现统一 OpenStack 各个项目间的认证管理。
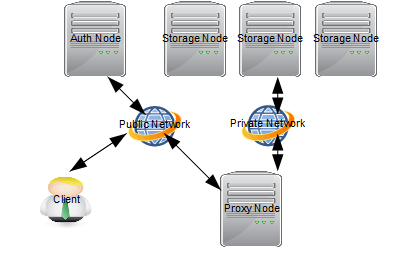
图 1. Swift 架构
主要组件
Proxy Server
Proxy Server 是提供 Swift API 的服务器进程,负责 Swift 其余组件间的相互通信。对于每个客户端的请求,它将在 Ring 中查询 Account、Container 或 Object 的位置,并且相应地转发请求。Proxy 提供了 REST API,并且符合标准的 HTTP 协议规范,这使得开发者可以快捷构建定制的 Client 与 Swift 交互。
Storage Server
Storage Server 提供了磁盘设备上的存储服务。在 Swift 中有三类存储服务器:Account、Container 和 Object。其中 Container 服务器负责处理 Object 的列表,Container 服务器并不知道对象存放位置,只知道指定 Container 里存的哪些 Object。这些 Object 信息以 sqlite 数据库文件的形式存储。Container 服务器也做一些跟踪统计,例如 Object 的总数、Container 的使用情况。
Consistency Server
在磁盘上存储数据并向外提供 REST API 并不是难以解决的问题,最主要的问题在于故障处理。Swift 的 Consistency Servers 的目的是查找并解决由数据损坏和硬件故障引起的错误。主要存在三个 Server:Auditor、Updater 和 Replicator。 Auditor 在每个 Swift 服务器的后台持续地扫描磁盘来检测对象、Container 和账号的完整性。如果发现数据损坏,Auditor 就会将该文件移动到隔离区域,然后由 Replicator 负责用一个完好的拷贝来替代该数据。图 2 给出了隔离对象的处理流图。 在系统高负荷或者发生故障的情况下,Container 或账号中的数据不会被立即更新。如果更新失败,该次更新在本地文件系统上会被加入队列,然后 Updaters 会继续处理这些失败了的更新工作,其中由 Account Updater 和 Container Updater 分别负责 Account 和 Object 列表的更新。 Replicator 的功能是处理数据的存放位置是否正确并且保持数据的合理拷贝数,它的设计目的是 Swift 服务器在面临如网络中断或者驱动器故障等临时性故障情况时可以保持系统的一致性。

图 2. 隔离对象的处理流
Ring
Ring 是 Swift 最重要的组件,用于记录存储对象与物理位置间的映射关系。在涉及查询 Account、Container、Object 信息时,就需要查询集群的 Ring 信息。 Ring 使用 Zone、Device、Partition 和 Replica 来维护这些映射信息。Ring 中每个 Partition 在集群中都(默认)有 3 个 Replica。每个 Partition 的位置由 Ring 来维护,并存储在映射中。Ring 文件在系统初始化时创建,之后每次增减存储节点时,需要重新平衡一下 Ring 文件中的项目,以保证增减节点时,系统因此而发生迁移的文件数量最少。
应用场景
Swift 提供的服务与Amazon S3相同,适用于许多应用场景。
1.网盘
Swift 的对称分布式架构和多 proxy 多节点的设计导致它从基因里就适合于多用户大并发的应用模式,最典型的应用莫过于类似 Dropbox 的网盘应用,Dropbox 去年底已经突破一亿用户数,对于这种规模的访问,良好的架构设计是能够支撑的根本原因。
Swift 的对称架构使得数据节点从逻辑上看处于同级别,每台节点上同时都具有数据和相关的元数据。并且元数据的核心数据结构使用的是哈希环,一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。另外数据是无状态的,每个数据在磁盘上都是完整的存储。这几点综合起来保证了存储的本身的良好的扩展性。
另外和应用的结合上,Swift 是遵循 HTTP 协议的,这使得应用和存储的交互变得简单,不需要考虑底层基础构架的细节,应用软件不需要进行任何的修改就可以让系统整体扩展到非常大的程度。
2.Iaas 公有云
Swift 在设计中的线性扩展,高并发和多租户支持等特性,使得它也非常适合做为 IaaS 的选择,公有云规模较大,更多的遇到大量虚机并发启动这种情况,所以对于虚机镜像的后台存储具体来说,实际上的挑战在于大数据(超过 G)的并发读性能,Swift 在 OpenStack 中一开始就是作为镜像库的后台存储,经过 Rackspace 上千台机器的部署规模下的数年实践,Swift 已经被证明是一个成熟的选择。
另外如果基于 IaaS 要提供上层的 SaaS 服务,多租户是一个不可避免的问题,Swift 的架构设计本身就是支持多租户的,这样对接起来更方便。
3.备份文档
Rackspace 的主营业务就是数据的备份归档,所以 Swift 在这个领域也是久经考验,同时他们还延展出一种新业务--“热归档”。由于长尾效应,数据可能被调用的时间窗越来越长,热归档能够保证应用归档数据能够在分钟级别重新获取,和传统磁带机归档方案中的数小时而言,是一个很大的进步。
4.移动互联网和 CDN
移动互联网和手机游戏等产生大量的用户数据,数据量不是很大但是用户数很多,这也是 Swift 能够处理的领域。
至于加上 CDN,如果使用 Swift,云存储就可以直接响应移动设备,不需要专门的服务器去响应这个 HTTP 的请求,也不需要在数据传输中再经过移动设备上的文件系统,直接是用 HTTP 协议上传云端。如果把经常被平台访问的数据缓存起来,利用一定的优化机制,数据可以从不同的地点分发到您的用户那里,这样就能提高访问的速度,Swift 的开发社区有人在讨论视频网站应用和 Swift 的结合,窃以为是值得关注的方向。
OpenStack 镜像存储—Glance
Glance 项目提供虚拟机镜像的发现、注册、取得服务。Glance 提供 REST API 可以查询虚拟机镜像的 metadata,并且可以获得镜像。
通过 Glance,虚拟机镜像可以被存储到多种存储上,比如简单的文件存储或者对象存储(比如 OpenStack 中 swift 项目),Havana 版本中 Glance 新增特性如下:
Multiple-Image-Location:支持镜像存储到多种不同类型的存储池。
More-Drivers:加入了 Sheepdog 支持,并且 Cinder 也可以作为后端存储驱动之一。
Glance 的几个重要概念:
1.Image identifiers:Image 使用 URI 作为唯一标识,URL 符合以下格式:
<Glance Server Location>/images/<ID>
Glance Server Location 是镜像的所在位置,ID 是镜像在 Glance 的唯一标识。
2.Image Statuses 共四种状态。
queued 标识该镜像 ID 已经被保留,但是镜像还未上传。
saving 标识镜像正在被上传。
active 标识镜像在 Glance 中完全可用。
killed 标识镜像上传过程中出错,镜像完全不可用。
3.Disk and Container format
Disk Format:raw vhd vmdk vdi iso qcow2 aki ari ami
Container Format: ovf bare aki ari ami
当 disk format 为 aki ari ami 时,disk format 和 container format 一致。
4.Image Registries
使用 Glance,镜像 metadata 可以注册至 image registries。
只要为 image metadata 提供了 rest like API,任何 web 程序可以作为 image registries 与 Glance 对接。
当然,Glance 也提供了参考实现。
更多信息可以参考on Controlling Servers,来自于 Glance 提供的 Glance registry server。
Glance 的架构:
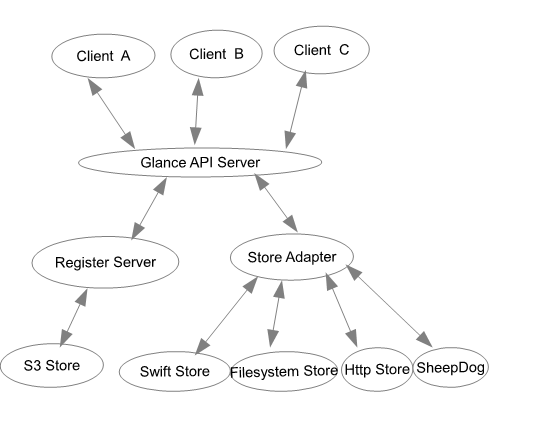
图 3. Glance的架构
Glance 被设计为可以使用多种后端存储。前端通过 API Server 向多个 Client 提供服务。
Glance 目前提供的参考实现中 Registry Server 仅是使用 Sql 数据库存储 metadata,Glance 支持 S3、Swift,简单的文件存储及只读的 HTTPS 存储。也支持其他后端,如分布式存储系统(SheepDog 或 Ceph)。
OpenStack 块存储—Cinder
OpenStack 到 Folsom 版本有比较大的改变,其中之一就是将之前在 Nova 中的部分持久性块存储功能(Nova-Volume)分离了出来,独立为新的组件 Cinder。主要核心是对卷的管理,允许对卷、卷的类型、卷的快照进行处理。它并没有实现对块设备的管理和实际服务,而是为后端不同的存储结构提供了统一的接口,不同的块设备服务厂商在 Cinder 中实现其驱动支持以与 OpenStack 进行整合。在CinderSupportMatrix中可以看到众多存储厂商如 NetAPP、IBM、SolidFire、EMC 和众多开源块存储系统对 Cinder 的支持。Havana 版本中 Cinder 新增特性如下:
Volume-Resize:在可用情况下调整卷大小。
Volume-Backup-To-Ceph:现在卷可以备份到 Ceph 集群中。
Volume-Migration:现在不同用户间可以透明地转移和交换卷。
QoS:增加限速相关的元信息供 Nova 和其 Hypervisor 使用。
More-Drivers:更多的存储厂商加入和完善了自己的 Cinder 驱动,如 Huawei、Vmware、Zadara。
Cinder 架构图
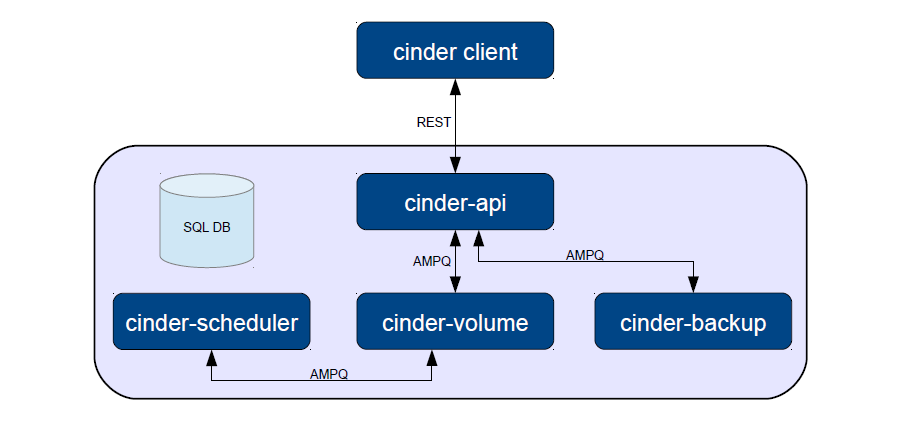
图 4. Cinder的架构
Cinder 服务
API service:负责接受和处理 Rest 请求,并将请求放入 RabbitMQ队列。
Scheduler service: 处理任务队列的任务,并根据预定策略选择合适的 Volume Service 节点来执行任务。目前版本的 cinder 仅仅提供了一个 Simple Scheduler, 该调度器选择卷数量最少的一个活跃节点来创建卷。
Volume service: 该服务运行在存储节点上,管理存储空间。每个存储节点都有一个 Volume Service,若干个这样的存储节点联合起来可以构成一个存储资源池。为了支持不同类型和型号的存储,当前版本的 Cinder 为 Volume Service 添加如下 drivers。当然在 Cinder 的 blueprints 当中还有一些其它的 drivers,以后的版本可能会添加进来。
本地存储:LVM(iSCSI), Sheepdog(sheepdog)
网络存储: NFS, RBD(Ceph)
IBM: Storwize family/SVC (iSCSI/FC),XIV (iSCSI),GPFS,zVM
Netapp: NetApp(iSCSI/NFS)
EMC: VMAX/VNX (iSCSI),Isilon(iSCSI)
Solidfire: Solidfire cluster(iSCSI)
HP:3PAR (iSCSI/FC),LeftHand (iSCSI)
Cinder 如何支持典型存储
从目前的实现来看,Cinder 对本地存储和 NAS 的支持比较不错,可以提供完整的 Cinder API V2 支持,而对于其它类型的存储设备,Cinder 的支持会或多或少的受到限制,下面是 Rackspace 对于 Private Cloud 存储给出的典型配置:
1.本地存储
对于本地存储,cinder-volume 可以使用 LVM 驱动,该驱动当前的实现需要在主机上事先用 LVM 命令创建一个 cinder-volumes 的卷组 , 当该主机接受到创建卷请求的时候,cinder-volume 在该卷组 上创建一个逻辑卷, 并且用 openiscsi 将这个卷当作一个 iscsi tgt 给输出.当然还可以将若干主机的本地存储用 sheepdog 虚拟成一个共享存储,然后使用 sheepdog 驱动。
2.EMC

图 5. EMC 块存储架构
3.Netapp
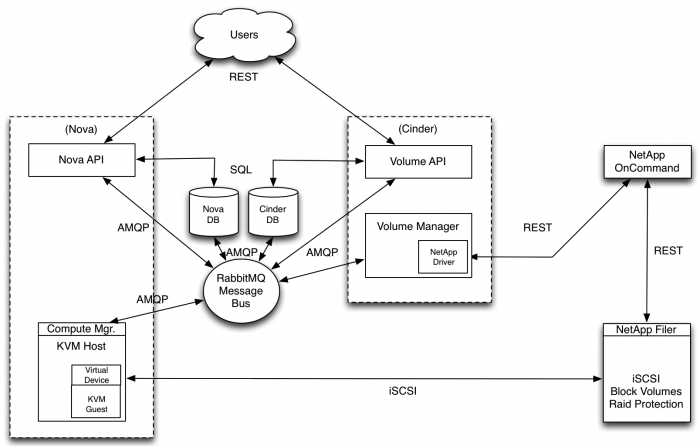
图 6. Netapp 块存储架构
HuaWei

图 7. HuaWei 块存储架构
HuaWei 块存储架构
传统存储与 OpenStack 云存储对比
表 2.对比

结束语
OpenStack 是设计用来管理共有云和私有云的。很多公司认为 OpenStack 有希望让他们能拥有一些单一专有云的功能,一些如谷歌、亚马逊及微软经营的云那样的功能。同时 OpenStack 是基于友好的 Apache 2 开源协议,任何人都能参与设计和开发,甚至提出创立自己的项目。只要经过社区讨论,并达成一致,就可以按照您的标准。开源的力量是强大的,随着社区半年一次的发布,Swift﹑ Glance 和 Cinder 将会越来越好。本文只是 OpenStack 存储初级性的一次调查报告,进一步深入探索可以查看参考资料了解有关 OpenStack 存储的更多相关信息。
正文到此结束
- 本文标签: UI 管理 空间 开源 ACE 协议 https cat 系统架构 移动设备 时间 开发 http 服务器 ip 互联网 Region 大数据 需求 REST 主机 Dropbox VMware 进程 配置 开源项目 代码 软件 统计 备份 node 数据库 sql 微软 IaaS 谷歌 src web IBM nfs HDFS IDE OpenStack key client apache 认证 数据 亚马逊 实例 Amazon SQLite update 测试 CDN 集群 开发者 API App Swift Architect 云 定制 突破 网站
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

