通通连起来——无处不在的流

最近总是听见 liu 这个东西啊,比如 liu 翔低调宣布新恋情啦、 liu 强冬告白奶茶啦、微软停止支持 IE liu 览器啦,最近我们的淘宝前端夜校讲师也提到了 liu (流)的运用。
在 Unix 系统中流就是一个很常见也很重要的概念。
Unix 的哲学:一个程序只做一件事,并做好。程序要能协作。程序要能处理文本流,因为这是最通用的接口。– Douglas McIlroy
还记得在你刚开始学习编程,尤其是学 C 语言会接触到文件流的概念。不限于文件系统的文件,还有输入输出的逻辑文件,因为在 C 中所有流均以文件的形式出现,今天肯定不是说 C , 在以异步 IO 高效著称 Node.js 中,流也是一个值得深入理解的概念。
在前端开发中,你可能见过这样的构建代码。
gulp.task('images', ['clean'], function() {
return gulp.src(paths.images)
.pipe(gulp.dest('build/img'));
});
那么什么是流?
用术语说流是对输入输出设备的抽象。以程序的角度说,流是具有方向的数据。在 Unix 系统中,我们使用符号 | 来实现流。
在 Node.js 中有个 stream 模块,它是一个抽象类。它的抽象接口被很多常见对象实现,比如常见的 request response
按照流动方向,stream 流分为 4 种,Readable,writable,Duplex streams 和 Transform streams。后两种可以理解为可读可写流的组合,所以优先理解可读可写流。
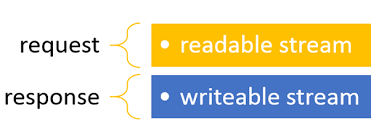
可以直接使用 stream_readable 创建一个流
var Readable = require('stream').Readable;
var rs = new Readable;
rs.push('beep ');
rs.push('boop ');
rs.push('null/n');
rs.push(null);
rs.pipe(process.stdout);
运行代码
$ node readable.js
beep boop null
数据被原样输出了,nul l 表示输出结束。
流的模式
那么如何才能协调输入输出呢,实际上,readable 流的数据会存在缓存中,直到有个流来消耗这些数据。简单的说,就是要多少,就尽量给多少。
readable stream 有个待实现接口 _read(size)
readable._read(size)
- size Number Number of bytes to read asynchronously
可以通过这个接口来验证流的工作
var Readable = require('stream').Readable;
var rs = Readable();
var c = 97 - 1;
rs._read = function () {
if (c >= 'z'.charCodeAt(0)) return rs.push(null);
//设置延时,有个直观感受
setTimeout(function () {
rs.push(String.fromCharCode(++c));
}, 200);
};
rs.pipe(process.stdout);
process.on('exit', function () {
console.error('/n_read() called ' + (c - 97) + ' times');
});
process.stdout.on('error', process.exit);
运行代码
$ node readable.js | head -c 5
abcde
_read() called 5 times
大约一秒后,5 个字符直接输出了。所以其实 readable 流是到了一定的水位,才会将这些数据吐出来。
你可能已经感觉到了,可读流一天到晚就处在两种状态:我吐了、我不吐了!

事实上确实是这样, Node.js 文档对流状态的说明。
Readable streams have two “modes”: a flowing mode and a paused mode.
流的两种状态分别称为流模式和暂停模式进入流模式有三种方法
- Adding a ‘data’ event handler to listen for data.
- Calling the resume() method to explicitly open the flow.
- Calling the pipe() method to send the data to a Writable.
也有两种方法暂停
- If there are no pipe destinations, by calling the pause() method.
- If there are pipe destinations, by removing any ‘data’ event handlers, and removing all pipe destinations by calling the unpipe() method.
流的常见应用
一个流的日常任务:举个栗子:服务器要读取文件返回给客户端:
var http = require('http');
var fs = require('fs');
var server = http.createServer(function (req, res) {
fs.readFile(__dirname + '/kuaibo.txt', function (err, data) {
res.end(data);
});
});
server.listen(8000);
这段代码是没有问题的,测试也能通过,但是不太友好。设想 kuaibo.txt size 有点大,程序读取这个文件并存在内存中,然后把结果再返回给客户端,此时正好有 1000 个并发请求,程序消耗大量内存,大量请求被挂起,服务会变得很慢或者不可用。即使只有一个请求,如果文件足够大,也会使用户等待。
可以使用 stream + pipe 的方式实现。由于 response 是一个 writable stream。
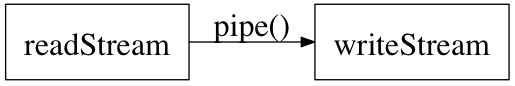
var http = require('http');
var fs = require('fs');
var server = http.createServer(function (req, res) {
var stream = fs.createReadStream(__dirname + '/kuaibo.txt');
stream.pipe(res);
});
server.listen(8000);
pipe 会自主管理流并且尽可能快的读取流。可以有个合理的猜测,那个据说能边下边播的著名的全视频解码软件-快播可能就是基于对视频流片段的实时解码实现的吧?虽然我没用过-。-!
管道
既然叫管道,那管道应该可以接起来啊~

『通通连起来』 –庞统
事实上确实可以。
var r = fs.createReadStream('file.txt');
var z = zlib.createGzip();
var w = fs.createWriteStream('file.txt.gz');
r.pipe(z).pipe(w);
在从一个 readable 流向一个 writable 流传数据的过程中,数据会自动被转换为 Buffer 对象。使用 pipe 的还有一个好处是,pipe() 方法自动管理流,把控制流的细节屏蔽了。stream 的实现经过几个版本,现在是这样的流程大约是这样的:
- 触发 data 事件,直到 writable 流满了
- buffer 满了触发 pause() , 进入暂停模式
- writable 的 Buffer 清理出来了,会触发 drain 事件,这时候 pipe 调用 resume 又进入流模式,然后再触发 data 事件。
stream_readable 模块 data 事件源码
stream.on('data', function(chunk) {
debug('wrapped data');
if (state.decoder)
chunk = state.decoder.write(chunk);
// don't skip over falsy values in objectMode
if (state.objectMode && (chunk === null || chunk === undefined))
return;
else if (!state.objectMode && (!chunk || !chunk.length))
return;
var ret = self.push(chunk);
if (!ret) {
paused = true;
stream.pause();
}
});
所有的流都是 EventEmitter 的实例。大部分情况下,我们只需要在上面添加我们希望触发的事件。
比如实现一个 HTTP 代理服务。
var http = require('http');
var net = require('net');
var url = require('url');
function request(cReq, cRes) {
var u = url.parse(cReq.url);
var options = {
hostname : u.hostname,
port : u.port || 80,
path : u.path,
method : cReq.method,
headers : cReq.headers
};
var pReq = http.request(options, function(pRes) {
cRes.writeHead(pRes.statusCode, pRes.headers);
pRes.pipe(cRes);
}).on('error', function(e) {
cRes.end();
});
cReq.pipe(pReq);
}
http.createServer().on('request', request).listen(8888, '0.0.0.0');
总结
Node.js 对流做了封装,提供很多 API,流其实是一个事件分发器。仅仅基于流的特性,我们就可以做很多功能。而现在很多成熟的系统,有的基于 Java,有的基于 C#,通常已经非常庞大,而对其做一次线上的全量升级,升级周期可能会长达半年甚至更长。这时候不妨利用 Nodejs 构建一个简单的原型服务,如果可以匹配 Node.js 的适用场景,再投入时间用 Nodejs 替换系统的部分服务,说不定是个更快速达到目标的方案。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

