看看Quora是如何实现贡献者排行功能的
今年年初,我们提出了最大访问量作者(MVWs)功能,即识别那些他们了解和关心的主题的最活跃贡献者。MVWs 是一种非常好的方式,既可以彰显贡献者,又可以帮助读者发现贡献者自身关注的主题。

作为一个产品工程师(product engineer),全程投入到这个功能的开发和设计中,我很高兴有这样一次机会,可以结合我的技术和热情来创建一个用户体验良好的产品。在这个过程中,我能够加入到产品经理、产品设计和数据科学家中来确定产品的最终目标和完成该目标的最佳方式。
在这篇文章中,我们将深入讨论该功能的某些模块,以及各种场景背后的架构力量,以及如何将这些模块整合完成最后的MVWs 功能。
最大访问量作者(MVWs)的定义
一个主题的最大访问量作者(MVMs)是指最近 30 天内,该主题下访问量最多的公共回答的用户。因此,我们的最终目标是识别每个主题下的活跃作者。完成该目标的第一步是定义一个清晰的范畴。
更明确的说,我们想创建一个能完成下列功能的系统:
1、跟踪近 30 天内每个答案的访问次数。
2、给定一个主题,返回最近 30 天内按答案访问量排名的 MVWs 列表。
3、给定一个用户,返回该用户属于 MVW 的主题列表。
4、给定一个主题,返回新的 MVWs 用户列表,这些用户将收到通知。
正如我们所见,清晰的定义 MVW 产品需求,直接关系到正确选择最好的架构来满足需求。
访问数据流
在跳到如何使用访问数据来创建 MVW 之前,我们先后退一步,弄清楚访问数据是从哪来的?
我们在产品的不同部分使用实时访问量来显示每段内容的查看情况。无论什么时候有人在Quora上查看了内容的某个片段,例如一个答案,我都能对访问量加1,并且我们想在持久化存储中保存所有的数据,因为不想弄丢任何数据。一种比较天真的实现方式是通过如下的方式来记录访问量:
# # Views module (version 1) # def log_views(answer_id, count=1): # Called every time when there is a view # Single update that happens inline views_datastore.increment(answer_id, count=count)
这看起来相当简单,对吧?如果系统只需要处理每秒 10 次的访问量,也就是说每 100 毫秒增加1次访问,那这是相当合理的。但是,如果访问次数是每秒100次?1000次?甚至更多?如果系统中有成千上万的答案,并且这些答案都会源源不断的获取到新的流量,系统将会是什么样子?
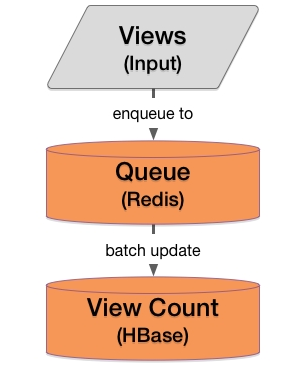
对于一个产品来说,访问是最频繁的操作(基本上每个页面的加载都会有),如果持久化每个行为将会对落地真实数据(ground-truth data)存储(HBase)产生太多的写操作,从而无法满足可扩展性问题。一种更好的可扩展方案是使用事件队列,然后按一定的规则进行批量增加。
# # Views module (version 2) # def enqueue(answer_id, count=1): # Called every time when there is a view # Enqueue to be updated via "batch_update" views_event_queue.enqueue(Item(answer_id, count)) def batch_update(): # Process enqueued items regularly items = views_event_queue.dequeue_recent_items() # Batch update views_datastore.batch_increment(items)
对于这种设计,访问数据将先进入一个简单的持久化事件队列(在Redis上实现的)。有了事件队列,我们可以有效的分摊 I/O 延迟,这样可以大幅度提高系统的吞吐量。从产品的角度来看,如果我们展示访问次数的频率比批量操作频率更高,则实时的访问量可以通过首次获取落地真实数据,此后通过对Redis缓存中的数据进行递增来实现。下面是该流程的简化图:
聚合访问量到 MVWs
现在,我们已经在某个地方有了实时访问数据,现在我们试着在这上面创建 MVW。
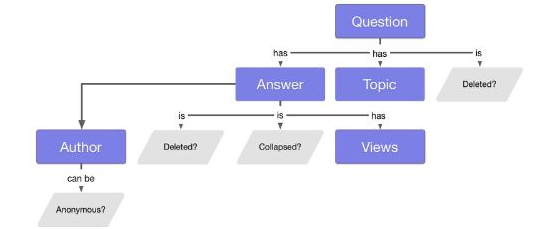
通过产品定义,一个最重要的步骤是通过每个答案的访问量来为每个用户聚合每个主题的访问量。这种聚合需要花费大量的计算来整合多个数据源,包括答案的访问次数,问题-主题之间的关系,问题-答案之间的关系。
此外,任何时候如果有答案被删除,都会引起级联效果。已删除答案的访问次数不应该包含在与此相关主题的用户排名范围以内,这就意味着我们需要对这些主题的排名进行更新。同样,如果某个答案出现了质量问题,也会出现类似的情况。这样就会导致更多的计算和聚合。
并且我们也开始注意到,Quora系统许多已存在的功能也会影响 MVW 的设计。下面是计算 MVW 数据所需要的实体之间的整体依赖关系图:
用户期望在访问 MVW 页面时能够快速的加载。但是,聚合操作很慢,并且页面加载时计算机之间的通信也无法满足,这些数据需要在页面加载前缓存起来。但是,如果这些依赖的项一直在改变,我们就需要不停的重新计算才能缓存。
关于访问频率的记录我们已在上面探讨过,如果任何访问量的改变都要反应到排名,我们就需要进行大量的重新聚合操作。我们当然可以投入更多的技术资源来支持这种复杂的场景,但是在这之前,我们考虑这是否真的是产品的需求?
在那天快结束的时候,我们的目标不仅仅是解决一个困难的工程问题,而是通过一个好的产品特性来实现最佳用户体验。回到原始的目标,即识别每个主题的优秀作者,我们确定的是在一个主题有新的 MVW 时,需要通知用户。如果排名非常不稳定,每秒都有可能变化,一个新的 MVW 可能刚接到通知到达前10,打开时才发现,数据已经过时了。
经过工程师、设计师、数据科学家及产品经理的讨论,我们觉得这样频繁的重新计算如此复杂的聚合是一个非常不好的主意,因为:
1、实时排名引起技术点复杂性。上图中任何依赖的改变(如,有访问行为时或者答案被删除时)都会触发排名的改变。
2、从可用性角度考虑,实时排名也是非常不好的。不稳定的排名会引起用户的混乱。
我们已经确定,对所有状态改变敏感的排名不是产品的需求(实际上也不是所期望的)。相反,一种更好的选择是周期性预聚合 MVWs 的离散版本,而不是像上面的流程一样,依赖实时的访问情况。我们可以通过线下的批量更新来计算下一个版本的 MVWs。
再看访问数据流
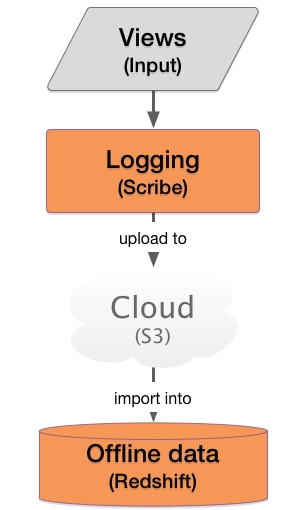
为了支持线下的计算,我们通过第二条线下查询的流水线来上传访问数据。有了这个设置,单个访问被记录在一个web 服务器的订阅(Scribe)上,这样通过多阶段线下数据流,我们可以将数据上传到 Amazon S3,并最终导入到 Redshift。我们之所以选择 Redshift,是因为在这上面做聚合操作非常简单,很适合大规模复杂查询。除了访问数据,其他相关的数据也可以上传到 Redshift。
该流水线可以抽象为下图所示:
最大访问作者,从开始到完成:
现在,有了批量更新 MVWs 的所有数据,让我们走一遍真正计算排名的流程。
在讨论最终的架构之前,先重新看一下我们想检索的信息:
1、给定一个主题,返回最近 30 天内按答案访问量排名的 MVWs 列表。
2、给定一个用户,返回该用户属于 MVW 的主题列表。
3、给定一个主题,返回新的 MVWs 用户列表,并给他们发送通知。
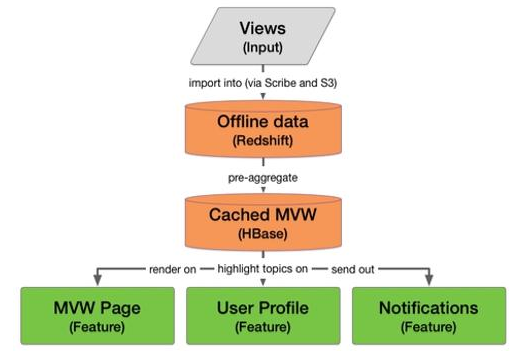
我们选择使用HBase(一个开源的,非关系型的,基于 Google's BigTable的分布式数据库)作为我们主要的后端来持久化存储 MVW 的缓存数据。一个好处是使用HBase能获得比关系型数据库管理系统(RDBMS),如 MySQL,或者是简单的内存缓存,如Redis,更好的大数据量的读写性能。由于所有的 MVW 数据都是预聚合的,所以只需要简单的key-value查询,而不要求范围或聚合查询。因此,我们的使用场景不涉及到需要关系型数据库索引的复杂查询。
例如,我们想缓存一些预聚合数据来支持如下1—10排名的查询:
(Topic, Rank) -> (User, TopicViewCount)
我们可以创建一个关键字为“topic”和“rank”的HBase表格,每一行需要一个“user”列和一个“topic view count”列。HBase的另一个非常好的特性是,我们实际上可以定义一个“user”的列族和一个“topic view count”列族,每个包含一系列的版本值。通过每个列族,HBase允许动态的聚合新的列。每次周期性更新计算出来的新版本排名时,我们都可以创建一个新的列来存储,通过直接指定这些列的存活时间,老版本就会自动过期。
回顾一下,我们记录访问数据到线下的数据流(Redshift)中,预聚合每个主题的排名,并在HBase中缓存结果,在最终的 MVW 功能中能够高效的查询数据。下面这个图总结了从访问记录到 MVW 数据的聚合到如何使用这些数据的流程:
在Quora的产品工程中的教训
通过创建 MVWs 的过程,我学到了许多关于产品工程的有效方式。该项目的成功主要归结为对如下原则的坚持:
1、明确定义技术和功能目标。例如,通过清晰的映射产品功能目标与完整的依赖图(如上),我们能够避免出现因很小的改变而引起的极度不稳定排名,并且这种排名对用户体验没有任何价值。这有助于我们做出正确的权衡,实现一个基于版本的设计,这既有利于技术层面的扩展,也有利于用户端的直观感受。
2、支持简洁性和可扩展性。如果有疑问,宁可降低复杂性。从产品角度来说,这可以给用户提供一个更清晰易懂的排名功能,从技术的角度来说,为我们在一个简单易懂的系统上持续迭代打开了一扇大门。
总之,作为一个产品工程师,我已经能够更好的看到 MVW 的影响,我也期待在未来能做更多的改进。对创建Quora的下一个精彩的功能有兴趣吗?查看职业生涯页获取更多关于在这里作为产品工程师的感受!
原文链接: The Product Engineering Behind Most Viewed Writers
译者: 杰微刊 --刘晓鹏
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

