每日一博 | 推荐引擎算法 - 猜你喜欢的东西
在一些大型购物网站,我们常会看到一个功能叫“猜你喜欢”(或其它类似的名字),里面列出一些跟你买过商品相关的其它商品。网站的用户越多,或你在网站上购买的东西越多,它往往就猜的越准。在一些音乐网站、书评网站、电影网站也有类似的推荐系统,比如豆瓣上的“豆瓣猜”、百度音乐的“为你推荐”等,推荐结果都不错。
这些推荐系统的具体实现我们无法知晓,但原理是类似的,都是采用基于协同过滤的推荐机制。这里我们探讨一下这个推荐机制的原理。
举例
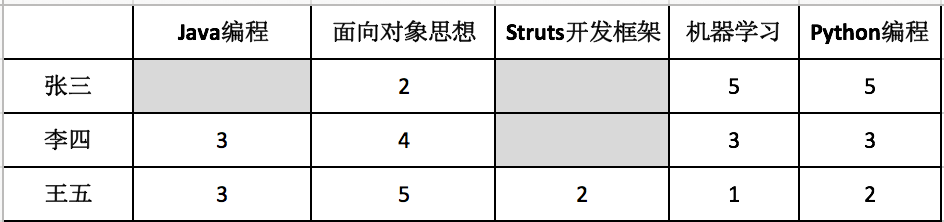
下图是一个用户对课程评分表。评分从1星到5星,灰色表示该用户没有对该课程评分。由图可知,用户3没有学过《面向对象基础》和《Struts开发框架》。问,如果要给用户3推荐其中一门课程,应该推荐哪一门?

基本概念
相似度
如果一个用户喜欢一种物品,那么他很可能也喜欢类似的物品。如果我们找到了测量物品之间相似程度的方法,也就解决了推荐系统的核心问题。
那如何找出这些方法呢?比如,啤酒与芝麻酱更相似还是与纸尿裤更相似?怎么知道啤酒和纸尿布的相似度是多少?
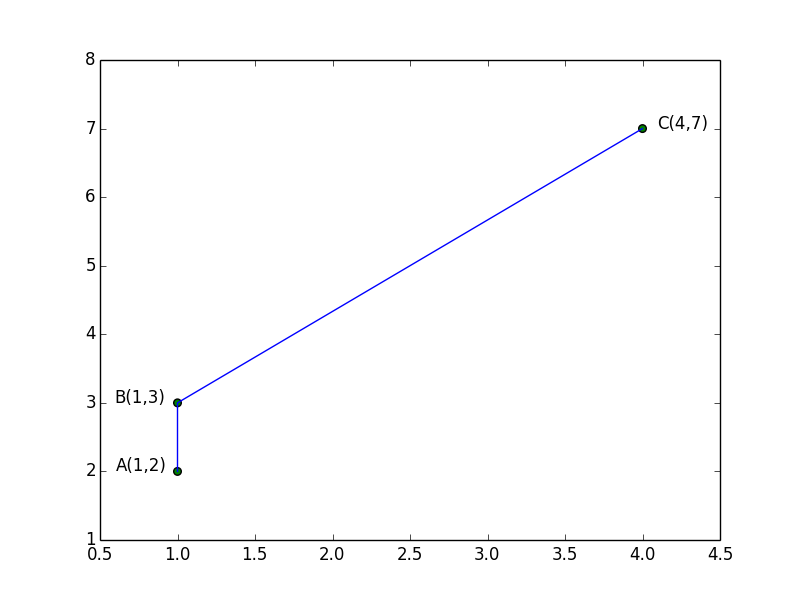
解决这个问题之前,不妨先考虑一个简单的问题。假设平面上有3个点,坐标分别是A(1,2)、B(1,3)和C(4,7),如图:
AB的距离=
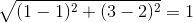
BC的距离=
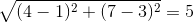
很显然B与A的距离小于B与C的距离,换句话说B与A更接近(相似)。
这种用根方差计算出来的距离叫欧式距离,欧式距离可以扩展到多维空间。大于3维的空间我们想象不出来,但是算法是一样的。
如果我们有下面的数据
那么通过用欧式距离公式可知:
《机器学习》与《python编程》的距离=
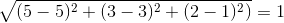
为了便于理解和比较,一般将相似度的值设在0到1之间,用欧式距离d得出的相似度可以表示为:
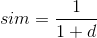
除了用欧式距离计算相似度外,常用的方法还有皮尔逊相关系数(Pearson correlation)和余玄相似度(cosine similarity).
下面是一段python代码,实现了基于欧式距离的相似度计算
from numpy import * from numpy import linalg as la def eSim(A,B): return 1.0/(1.0+la.norm(A-B))
再添加一个加载数据的方法。该方法返回一个二维数组,表示用户对课程的评价值。
def loadData(): return[[5, 3, 0, 2, 2], [4, 0, 0, 3, 3], [5, 0, 0, 1, 1], [1, 1, 1, 2, 0], [2, 2, 2, 0, 0], [1, 1, 1, 0, 0], [5, 5, 5, 0, 0]]
推荐引擎 - 给用户推荐最喜欢的课程
目的:给定一个用户,程序返回N个该用户最喜欢的课程
步骤
* 查询用户没有评级的课程, 即矩阵中的0元素
* 在用户没有评级的所有课程中,对每个课程预测一个评级分数
* 评分从高到底排序, 返回前N个课程
推荐引擎需要一个对课程评估分值的函数
''' 函数功能:在给定相似度计算方法的条件下,估计该用户对课程的评分值 input ds: 评价矩阵 userIdx: 用户编号 simFunc: 相似度计算方法 courseIdx: 课程编号 output 编号为courseIdx的课程对应的估计分值 ''' def standEst(ds, userIdx, simFunc, courseIdx): n = shape(ds)[1] #课程数量 simTotal = 0.0; ratSimTotal = 0.0 #遍历所有课程 for j in range(n): userRating = ds[userIdx,j] #用户对第j个课程的评价 if userRating == 0: continue #用户没有对该课程评分,跳过 #寻找两个用户都评级的课程 overLap = nonzero(logical_and(ds[:,courseIdx].A>0, ds[:,j].A>0))[0] #如果两个课程(courseIdx和j)没有共同评价人,则相似度=0 if len(overLap) == 0: similarity = 0 #否则,计算相似度 else: similarity = simFunc(ds[overLap,courseIdx], ds[overLap,j]) #总相似度(相似度可以理解为权重) simTotal += similarity #相似度*评分的合计 ratSimTotal += similarity * userRating if simTotal == 0: return 0 else: return ratSimTotal/simTotal #预计得分
推荐引擎代码
''' 推荐引擎: 给用户推荐N个最喜欢的课程 input ds: 评价矩阵 userIdx: N: 最高推荐N个结果 simFunc estFunc ''' def recommendCourses(ds, userIdx, N=3, simFunc=eSim, estFunc=standEst): unratedCourses = nonzero(ds[userIdx,:].A==0)[1] #当前用户没有打分的课程 if len(unratedCourses) == 0: return '你已经学过所有课程' courseScores = [] #课程分数列表 for courseIdx in unratedCourses: estimatedScore = estFunc(ds, userIdx, simFunc, courseIdx) courseScores.append((courseIdx, estimatedScore)) return sorted(courseScores, key=lambda jj: jj[1], reverse=True)[:N]
测试函数,给用户3推荐课程
def test(): dataMat = mat(loadData()) print recommendCourses(dataMat,2)
执行代码
>>> import recommend >>> recommend.test() [(2, 3.6666666666666665), (1, 2.068764098505754)]
推荐结果:下标为2的课程(《Struts开发框架》)得分3.67星,下标为1的课程(《面向对象思想》)得分为2星。因此,判断用户更喜欢《Struts开发框架》。
从直观上也可以这样理解:用户4,5,6,7都对《Java编程》和《Struts开发框架》做了评价,而且评价相同。因此,《Struts开发框架》与《Java编程》属于非常相似的物品。 而用户3对《Java编程》评价极高(5星),故判断《Struts开发框架》也应该得高分(对于用户3而言)。
局限
* 这个算法需要对整个数据集进行多次复杂的计算,如果数据量很大,则性能可能无法接受。一种解决办法是对矩阵进行SVD分解,把高维度的矩阵转换成低维度度的矩阵。此外,采用离线计算,将相似度这个中间结果保存起来重复利用也可以提高性能。
* 冷启动问题。新课程加进来时,由于缺乏数据无法进行推荐。这个可以通过给课程打标签的方式进行。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

