神经网络和深度学习简史(三)
这是「神经网络和深度学习简史」的第三部分(第一部分,第二部分)。在这一部分,我们将继续了解90年代研究的飞速发展,搞清楚神经网络在60年代末失去众多青睐的原因。
神经网络做决定
神经网络运用于无监督学习的发现之旅结束后,让我们也快速了解一下它们如何被用于机器学习的第三个分支领域:加强学习。正规解释加强学习需要很多数学符号,不过,它也有一个很容易加以非正式描述的目标:学会做出好决定。给定一些理论代理(比如,一个小软件),让代理能够根据当前状态做出行动,每个采取行动会获得一些奖励,而且每个行动也意图最大化长期效用。
因此,尽管监督学习确切告诉了学习算法它应该学习的用以输出的内容,但是,加强学习会过一段时间提供奖励,作为一个好决定的副产品,不会直接告诉算法应该选择的正确决定。从一开始,这就是一个非常抽象的决策模型——数目有限的状态,并且有一组已知的行动,每种状态下的奖励也是已知的。为了找到一组最优行动,编写出非常优雅的方程会因此变得简单,不过这很难用于解决真实问题——那些状态持续或者很难界定奖励的问题。

加强学习
这就是神经网络流行起来的地方。机器学习大体上,特别是神经网络,很善于处理混乱的连续性数据 ,或者通过实例学习很难加以定义的函数。尽管分类是神经网络的饭碗,但是,神经网络足够普适(general),能用来解决许多类型的问题——比如,Bernard Widrow和Ted Hoff的Adaline后续衍生技术被用于电路环境下的自适应滤波器。

因此,BP研究复苏之后,不久,人们就设计了利用神经网络进行增强学习的办法。早期例子之一就是解决一个简单却经典的问题:平衡运动着的平台上的棍子,各地控制课堂上学生熟知的倒立摆控制问题。双摆控制问题——单摆问题进阶版本,是一个经典的控制和强化学习任务。
因为有自适应滤波,这项研究就和电子工程领域密切相关,这一领域中,在神经网络出现之前的几十年当中,控制论已经成为一个主要的子领域。虽然该领域已经设计了很多通过直接分析解决问题的办法,也有一种通过学习解决更加复杂状态的办法,事实证明这一办法有用——1990年,「Identification and control of dynamical systems using neural networks」的7000次高被引就是证明。或许可以断定,另有一个独立于机器学习领域,其中,神经网络就是有用的机器人学。用于机器人学的早期神经网络例子之一就是来自CMU的NavLab,1989年的「 Alvinn: An autonomous land vehicle in a neural network 」 :
正如论文所讨论的,这一系统中的神经网络通过普通的监督学习学会使用传感器以及人类驾驶时记录下的驾驶数据来控制车辆。也有研究教会机器人专门使用加强学习,正如1993年博士论文「 Reinforcement learning for robots using neural networks」 所示例的。论文表明,机器人能学会一些动作,比如,沿着墙壁行走,或者在合理时间范围内通过门,考虑到之前倒立摆工作所需的长得不切实际的训练时间,这真是件好事。
这些发生在其他领域中的运用当然很酷,但是,当然多数加强学习和神经网络的研究发生在人工智能和机器学习范围内。而且,我们也在这一范围内取得了加强学习史上最重要的成绩之一:一个学习并成为西洋双陆棋世界级玩家的神经网络。研究人员用标准加强学习算法来训练这个被称为TD-Gammon的神经网络,它也是第一个证明加强学习能够在相对复杂任务中胜过人类的证据。而且,这是个特别的加强学习办法,同样的仅采用神经网络(没有加强学习)的系统,表现没这么好。

西洋双陆棋游戏中,掌握专家级别水平的神经网络
但是,正如之前已经看到,接下来也会在人工智能领域再次看到,研究进入死胡同。下一个要用TD-Gammnon办法解决的问题,Sebastian Thrun已经在1995年「 Learning To Play the Game of Chess 」中研究过了,结果不是很好..尽管神经网络表现不俗,肯定比一个初学者要好,但和很久以前实现的标准计算机程序GNU-Chess相比,要逊色得多。人工智能长期面临的另一个挑战——围棋,亦是如此。这样说吧,TD-Gammon 有点作弊了——它学会了精确评估位置,因此,无需对接下来的好多步做任何搜索,只用选择可以占据下一个最有利位置的招数。但是,在象棋游戏和围棋游戏里,这些游戏对人工智能而言是一个挑战,因为需要预估很多步,可能的行动组合如此之巨。而且,就算算法更聪明,当时的硬件又跟不上,Thrun称「NeuroChess不怎么样,因为它把大部分时间花在评估棋盘上了。计算大型神经网络函数耗时是评价优化线性评估函数(an optimized linear evaluation function),比如GNU-Chess,的两倍。」当时,计算机相对于神经网络需求的不足是一个很现实的问题,而且正如我们将要看到的,这不是唯一一个…
神经网络变得呆头呆脑
尽管无监督学习和加强学习很简洁,监督学习仍然是我最喜欢的神经网络应用实例。诚然,学习数据的概率模型很酷,但是,通过反向传播解决实际问题更容易让人兴奋。我们已经看到了Yann Lecun成功解决了识别手写的问题(这一技术继续被全国用来扫描支票,而且后来的使用更多),另一项显而易见且相当重要的任务也在同时进行着:理解人类的语音。
和识别手写一样,理解人类的语音很难,同一个词根据表达的不同,意思也有很多变化。不过,还有额外的挑战:长序列的输入。你看,如果是图片,你就可以把字母从图片中切出来,然后,神经网络就能告诉你这个字母是啥,输入-输出模式。但语言就没那么容易了,把语音拆成字母完全不切实际,就算想要找出语音中的单词也没那么容易。而且你想啊,听到语境中的单词相比单个单词,要好理解一点吧!尽管输入-输出模式用来逐个处理图片相当有效,这并不适用于很长的信息,比如音频或文本。神经网络没有记忆赖以处理一个输入能影响后续的另一个输入的情况,但这恰恰是我们人类处理音频或者文本的方式——输入一串单词或者声音,而不是单独输入。要点是:要解决理解语音的问题,研究人员试图修改神经网络来处理一系列输入(就像语音中的那样)而不是批量输入(像图片中那样)。
Alexander Waibel等人(还有Hinton)提出的解决方法之一,在1989年的「 Phoneme recognition using time-delay neural networks 」中得到了介绍。这些时延神经网络和通常意义上的神经网络非常类似,除了每个神经元只处理一个输入子集,而且为不同类型的输入数据延迟配备了几套权重。易言之,针对一系列音频输入,一个音频的「移动窗口」被输入到神经网络,而且随着窗口移动,每个带有几套不同权重的神经元就会根据这段音频在窗口中位置,赋予相应的权重,用这种方法来处理音频。画张图就好理解了:
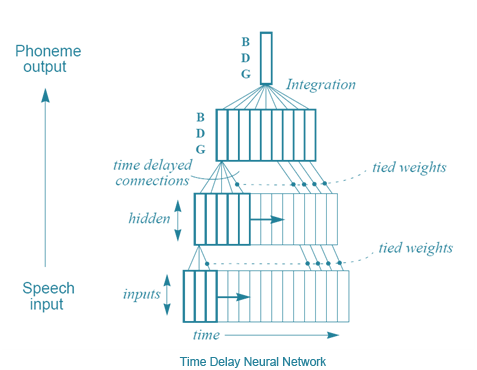
时延神经网络
从某种意义上来说,这和卷积神经网络差不多——每个单元一次只看一个输入子集,对每个小子集进行相同的运算,而不是一次性计算整个集合。不同之处在于,在卷积神经网络中不存在时间概念, 每个神经元的输入窗形成整个输入图像来计算出一个结果,而时延神经网络中有一系列的输入和输出。一个有趣的事实:据Hinton说,时延神经网络的理念启发了LeCun开发卷积神经网络。但是,好笑的是,积卷神经网络变得对图像处理至关重要,而在语音识别方面,时延神经网络则败北于另一种方法——递归神经网络(RNNs)。你看,目前为止讨论过的所有神经网络都是前归网络,这意味着某神经元的输出是下一层神经元的输入。但并不一定要这样,没有什么阻止我们勇敢的计算机科学家将最后一层的输出变成第一层的输入,或者将神经元的输出连接到神经元自身。将神经元回路接回神经网络,赋予神经网络记忆就被优雅地解决了。
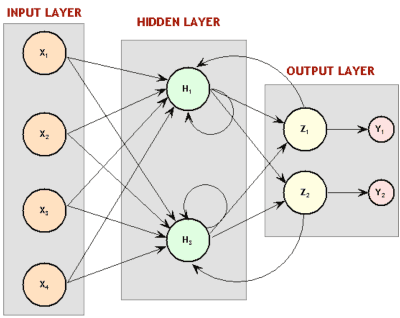
递归神经网络图。还记得之前的玻尔兹曼机吗?大吃一惊吧!那些是递归性神经网络。
然而,这可没有那么容易。注意这个问题——如果反向传播需要依赖『正向传播』将输出层的错误反馈回来,那么,如果第一层往回连接到输出层,系统怎么工作?错误会继续传到第一层再传回到输出层,在神经网络中循环往复,无限次地。解决办法是,通过多重群组独立推导,通过时间进行反向传播。基本来说,就是将每个通过神经网络的回路做为另一个神经网络的输入,而且回路次数有限,通过这样的办法把递归神经网络铺开。

通过时间概念反向传播的直观图解。
这个很简单的想法真的起作用了——训练递归神经网络是可能的。并且,有很多人探索出了RNN在语言识别领域的应用。但是,你可能也听说过其中的波折:这一方法效果并不是很好。为了找出原因,让我们来认识另一位深度学习的巨人:Yoshua Bengion。大约在1986年,他就开始进行语言识别方向的神经网络研究工作,也参与了许多使用ANN和RNN进行语言识别的学术论文,最后进入AT&T BELL实验室工作,Yann LeCun正好也在那里攻克CNN。 实际上,1995年,两位共同发表了文章「 Convolutional Networks for Images, Speech, and Time-Series 」,这是他们第一次合作,后来他们也进行了许多合作。但是,早在1993年,Bengio曾发表过「 A Connectionist Approach to Speech Recognition 」。其中,他对有效训练RNN的一般错误进行了归纳:
尽管在许多例子中,递归网络能胜过静态网络,但是,优化训练起来也更有难度。我们的实验倾向于显示(递归神经网络)的参数调整往往收敛在亚优化的解里面,(这种解)只考虑了短效应影响因子而不计长效影响因子。例如,在所述实验中我们发现,RNN根本捕获不到单音素受到的简单时间约束…虽然这是一个消极的结果,但是,更好地理解这一问题可以帮助设计替代系统来训练神经网络,让它学会通过长效影响因子,将输出序列映射到输入序列(map input sequences to output sequences with long term dependencies ),比如,为了学习有限状态机,语法,以及其他语言相关的任务。既然基于梯度的方法显然不足以解决这类问题,我们要考虑其他最优办法,得出可以接受的结论,即使当判别函数(criterion function)并不平滑时。
新的冬日黎明
因此,有一个问题。一个大问题。而且,基本而言,这个问题就是近来的一个巨大成就:反向传播。卷积神经网络在这里起到了非常重要的作用,因为反向传播在有着很多分层的一般神经网络中表现并不好。然而,深度学习的一个关键就是——很多分层,现在的系统大概有20左右的分层。但是,二十世纪八十年代后期,人们就发现,用反向传播来训练深度神经网络效果并不尽如人意,尤其是不如对较少层数的网络训练的结果。原因就是反向传播依赖于将输出层的错误找到并且连续地将错误原因归类到之前的各个分层。然而,在如此大量的层次下,这种数学基础的归咎方法最终产生了不是极大就是极小的结果,被称为『梯度消失或爆炸的问题』,Jurgen Schmidhuber——另一位深度学习的权威,给出了更正式也更深刻的归纳:
一篇学术论文(发表于1991年,作者Hochreiter)曾经对深度学习研究给予了里程碑式的描述。文中第五、第六部分提到:二十世纪九十年代晚期,有些实验表明,前馈或递归深度神经网络是很难用反向传播法进行训练的(见5.5)。Horchreiter在研究中指出了导致问题的一个主要原因:传统的深度神经网络遭遇了梯度消失或爆炸问题。在标准激活状态下(见1),累积的反向传播错误信号不是迅速收缩,就是超出界限。实际上,他们随着层数或CAP深度的增加,以几何数衰减或爆炸(使得对神经网络进行有效训练几乎是不可能的事)。
通过时间顺序扁平化BP路径本质上跟具有许多层的神经网络一样,所以,用反向传播来训练递归神经网络是比较困难的。由Schmidhuber指导的Sepp Hochreiter及Yoshua Bengio都写过文章指出,由于反向传播的限制,学习长时间的信息是行不通的。分析问题以后其实是有解决办法的,Schmidhuber 及 Hochreiter在1997年引进了一个十分重要的概念,这最终解决了如何训练递归神经网络的问题,这就是长短期记忆(Long Short Term Memory, LSTM)。简言之,卷积神经网络及长短期记忆的突破最终只为正常的神经网络模型带来了一些小改动:
LSTM的基本原理十分简单。当中有一些单位被称为恒常误差木马(Constant Error Carousels, CECs)。每个CEC使用一個激活函数 f,它是一个恒常函数,並有一个与其自身的连接,其固定权重为1.0。由於 f 的恒常导数为1.0,通过CEC的误差反向传播将不会消失或爆炸(5.9节),而是保持原状(除非它们从CEC「流出」到其他一些地方,典型的是「流到」神经网络的自适应部分)。CEC被连接到许多非线性自适应单元上(有一些单元具有乘法的激活函数),因此需要学习非线性行为。单元的权重改变经常得益于误差信号在时间里通过CECs往后传播。为什么LSTM网络可以学习探索发生在几千个离散时间步骤前的事件的重要性,而之前的递归神经网络对于很短的时间步骤就已经失败了呢?CEC是最主要的原因。
但这对于解决更大的知觉问题,即神经网络比较粗糙、没有很好的表现这一问题是没有太大帮助的。用它们来工作是十分麻烦的——电脑不够快、算法不够聪明,人们不开心。所以在九十年代左右,对于神经网络一个新的AI寒冬开始来临——社会对它们再次失去信心。一个新的方法,被称为支持向量机(Support Vector Machines),得到发展并且渐渐被发现是优于先前棘手的神经网络。简单的说,支持向量机就是对一个相当于两层的神经网络进行数学上的最优训练。事实上,在1995年,LeCun的一篇论文,「 Comparison of Learning Algorithms For Handwritten Digit Recognition」 ,就已经讨论了这个新的方法比先前最好的神经网络工作得更好,最起码也表现一样。
支持向量机分类器具有非常棒的准确率,这是最显著的优点,因为与其他高质量的分类器比,它对问题不包含有先验的知识。事实上,如果一个固定的映射被安排到图像的像素上,这个分类器同样会有良好的表现。比起卷积网络,它依然很缓慢,并占用大量内存。但由于技术仍较新,改善是可以预期的。
另外一些新的方法,特别是随机森林(Random Forests),也被证明十分有效,并有强大的数学理论作为后盾。因此,尽管递归神经网络始终有不俗的表现,但对于神经网络的热情逐步减退,机器学习社区再次否认了它们。寒冬再次降临。在第四部分,我们会看到一小批研究者如何在这条坎坷的道路上前行,并最终让深度学习以今天的面貌向大众展现。
![]()
- Anderson, C. W. (1989). Learning to control an inverted pendulum using neural networks. Control Systems Magazine, IEEE, 9(3), 31-37. ↩
- Narendra, K. S., & Parthasarathy, K. (1990). Identification and control of dynamical systems using neural networks. Neural Networks, IEEE Transactions on, 1(1), 4-27. ↩
- Lin, L. J. (1993). Reinforcement learning for robots using neural networks (No. CMU-CS-93-103). Carnegie-Mellon Univ Pittsburgh PA School of Computer Science. ↩
- Tesauro, G. (1995). Temporal difference learning and TD-Gammon. Communications of the ACM, 38(3), 58-68. ↩
- Thrun, S. (1995). Learning to play the game of chess. Advances in neural information processing systems, 7. ↩
- Schraudolph, N. N., Dayan, P., & Sejnowski, T. J. (1994). Temporal difference learning of position evaluation in the game of Go. Advances in Neural Information Processing Systems, 817-817. ↩
- Waibel, A., Hanazawa, T., Hinton, G., Shikano, K., & Lang, K. J. (1989). Phoneme recognition using time-delay neural networks. Acoustics, Speech and Signal Processing, IEEE Transactions on, 37(3), 328-339. ↩
- Yann LeCun and Yoshua Bengio. 1998. Convolutional networks for images, speech, and time series. In The handbook of brain theory and neural networks, Michael A. Arbib (E()d.). MIT Press, Cambridge, MA, USA 255-258. ↩
- Yoshua Bengio, A Connectionist Approach To Speech Recognition Int. J. Patt. Recogn. Artif. Intell., 07, 647 (1993). ↩
- J. Schmidhuber. “Deep Learning in Neural Networks: An Overview”. “Neural Networks”, “61”, “85-117”. http://arxiv.org/abs/1404.7828 ↩ ↩2
- Hochreiter, S. (1991). Untersuchungen zu dynamischen neuronalen Netzen. Diploma thesis, Institutfur Informatik, Lehrstuhl Prof. Brauer, Technische Universitat Munchen. Advisor: J. Schmidhuber. ↩
- Bengio, Y.; Simard, P.; Frasconi, P., “Learning long-term dependencies with gradient descent is difficult,” in Neural Networks, IEEE Transactions on , vol.5, no.2, pp.157-166, Mar 1994 ↩
- Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long Short-Term Memory. Neural Comput. 9, 8 (November 1997), 1735-1780. DOI=http://dx.doi.org/10.1162/neco.1997.9.8.1735. ↩
- Y. LeCun, L. D. Jackel, L. Bottou, A. Brunot, C. Cortes, J. S. Denker, H. Drucker, I. Guyon, U. A. Muller, E. Sackinger, P. Simard and V. Vapnik: Comparison of learning algorithms for handwritten digit recognition, in Fogelman, F. and Gallinari, P. (Eds), International Conference on Artificial Neural Networks, 53-60, EC2 & Cie, Paris, 1995 ↩
本文选自 andreykurenkov.com ,作者 andreykurenkov ,机器之心翻译出品,参与:salmoner, 电子羊,妞妞姐姐,Ben, 微胖,wei
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

