自动问答系统
1. 自动问答系统
什么是自动问答系统(Question and Answering)呢,一般将其定义为一个能回答任意自语言形式问题的自动机。其输入为自然语言形式的问题,输出应该是一个简洁的答案,而不是一堆相关的文档列表。
比如,“世界上第一台计算机什么时候发明的”,自动问答系统应该能够给出简洁明了的答案,“1946年2月14日”。
自动问答系统能给用户提供更加精确的信息服务,用户不需要阅读象搜索引擎返回的文档列表去查找答案,从而提高了效率。与传统的搜索引擎相比,QA系统的相关度要求较高。其与搜索引擎的主要区别有以下几点:
自动问答与搜索引擎的区别
自动问答 搜索引擎
搜索方式 更复杂的语法、语义分析 关键词查询
数据源 网页数据库、FAQ库、百科全书、其他知识库等 网页数据
结果反馈 简洁明了的答案 文档列表
2. 问答系统研究现状
1999年文本信息检索会议(Text Retrieval Conference TREC)首次把Automatic Question Answering Track设为评测专项。经过近20年的发展,该领域取得了极具价值的成果。
目前比较成熟的自动问答系统主要有IBM的Waston,微软小冰,苹果siri,Yahoo!Answer,WolframAlpha,START(MIT),AskMSR(MS),Ask.com,以及国内的微信自动问答公众账号、复旦大学和哈工大的研究项目等。(不得不承认老外一直在走在技术的前列,吾辈当努力自强!)
Waston (沃森)是够使用自然语言来回答问题的人工智能系统,由IBM的DeepQA计划小组开发。2011年,沃森参加综艺节目危险边缘来测试它的能力,沃森在前两轮中与对手打平,而在最后一集里,沃森打败了最高奖金得主布拉德·鲁特尔和连胜纪录保持者肯·詹宁斯。这不得不说是继“深蓝”(1997年5月IBM深蓝电脑以3.5–2.5击败卡斯巴罗夫)之后人工智能的又一大进步。当然,最近Google AI打败围棋高手,或许进一步预示着人类最后的智力骄傲即将崩塌。哦,扯得有点远了。
根据维基百科,我们可以看到沃森的庞大组织架构,包括90台Power 750服务器,共计2880颗Power7处理器核心以及16TB内存,每秒可以处理500GB数据,相当于100万本书籍。并且有超过100项不同的技术被用在数据的处理上。当然,这样的架构也只有少数财大气粗的主能承担得起。
对于沃森的具体细节,可以参见论文:
Building Watson:An Overview of the DeepQA Project。相信聪明的你,一搜就搜到了。
微软小冰和苹果的siri,哈哈,没事的时候可以逗逗她,消磨消磨时间。来,讲个冷笑话吧~~~balabala
小冰 是微软亚洲研究院推出的人机交互聊天机器人,聊天机器人属于自动问答的一个领域方向,所以她并不是一个纯粹的自动问答系统。小冰走的是“感官系统+情感计算=AI萌妹子”的路线。
“感官系统”包括视觉、听觉在内的人工智感官系统。小冰使用的是视觉识别技术不是图像识别。区别在于,图像识别只是单纯地把识别结果输出,比如说“图像里有个女人”,视觉识别技术则具有智慧和兴趣的评价,比如说“哇塞,美女呀,我要流鼻血了!”。至于听觉技术,当然是语音识别了,但目前小冰还是能听不能说。
相比于“感官系统”,“情感分析”则要更为复杂。要从文本、图片以及语言里面识别出情绪、语气语调,其建模和训练比单纯的图像识别更加复杂,同时需要的数据也更多。目前来看小冰的EQ还不够高。当然了,她还没长大,只是个孩子。等她长大了,单身程序狗会不会爱上她呢,我觉得大有可能。再配合虚拟现实技术,出来个“一顾倾人城,再顾倾人国”的佳人,恩,世界顿时清净了。
至于 siri ,个人认为她比小冰更智能一点,也是个机器人。“你有没有掉进过爱情的悬崖?”--“从没。我倒是从桌子上掉下来过”,绝对是个极品逗逼。
siri 背后的技术,每一个都是狠角色,一二三,拉出来看看:
1. 以Google为代表的网页搜索技术;
2. 以Wolfram Alpha为代表的知识搜索技术(或者知识计算技术);这个我们后面还会提到它。
3. 以Wikipedia 为代表的知识库(和 Wolfram Alpha 不同的是,这些知识来自人类的手工编辑)技术(包括其他百科,如电影百科等;
4. 以Yelp 为代表的问答以及推荐技术。
5. 语言识别技术。目前支持20多种语言,不得了,真不得了。
Yahoo! Answer 。不怎么好用,是雅虎推出的一个开放性知识百科网站,旨在帮助网民们找到各自满意的答案,同时为网民们提供一个自由互动的知识分享平台。更多的是借助于网民的力量去回答问题,这明显是一种CQA(社区问答,诸如百度知道、新浪爱问)。当然也提供了自动问答的入口,效果不咋地。
Wolfram Alpha ,名副其实的自动问答系统,可以直接向用户返回答案,而不是像传统搜索引擎一样提供一系列可能含有用户所需答案的相关网页。Wolfram Alpha 可以完成数学、统计学、物理、化学、此处略去若干字,......,等各个领域的查询、计算和分析,还可对用户上传的图片进行识别。强大到暴。哦,不要多想,不是强暴。甚至有人称它为“Google 终结者”。
START(MIT) ,世界上第一个(第一个呀,第一个!重要的事情说三遍)基于web 的自动问答系统。诞生于MIT 人工智能实验室。目前能够回答包括地理、科学、文化、历史、艺术在内的问题。其表现形式是一种典型的(常见问题问答)FQA。
Ask.com 是目前最成功的问答式检索系统,已经投入了商业运营,成为美国第四大搜索引擎。Ask.com允许用户用自然语言表述的问题作为查询进行提交 ,系统在理解用户意图的基础上可以返回较为准确的信息。
AskMSR ,在AskMSR的搜索框内输入问题,返回的搜索结果不再是包含关键字的网页链接,而是一个简单不过的答案。不过该软件并没有利用人工智能原理(没用人工智能,就不智能啦,年轻人,too young,too naive),而只是使搜索程序学习了一定的语法,以此来和相关的网页内容匹配。在程序不能恰好找到相关字符串的情况下,该软件还可以根据两个关键词出现在同一个句子中的几率来判断二者的相关性,作为提供答案的依据。
相对英文问答系统,中文问答系统起步较晚,这和中文的语法、语义复杂性等多种因素有关。
微信自动问答公众号,根据关键词自动回复,据我所知,稍微涉及到了语义分析。漫漫道路,上下求索吧。
最后,不得不提一下,图灵测试机,开山鼻祖(数值分析课上,老师曾指着自己的鼻子说,我就是鼻祖~~~)!
3. 问答系统一般框架
自动问答系统是包含知识存储、只是表示、信息抽取、自然语言处理等多方面研究技术的综合性应用系统。其体系结构一般包括问题分析模块、信息检索模块以及答案抽取和排序模块。
对于实质性的技术问题,这里不做深入介绍,后面会给出资源链接。
见下图。
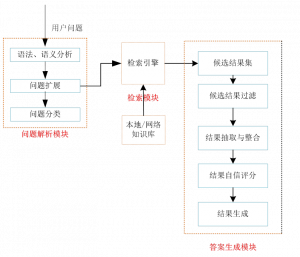
问题解析模块用于对用户提出的问题进行预处理,主要是对问题进行关键词提取,关键词扩展、问题分类等。问题解析模块是整个系统的入口,大有一夫当关万夫莫开之势,它是自动问答系统的第一个执行阶段,这一阶段的分析结果将成为后一阶段的处理信息,因此问题理解阶段对用户提问的模糊分析,甚至错误理解致使后面的工作变得无效和错误,最终导致了回答的不准确甚至是错误。究其原因有以下几方面:
1. 自然语言的复杂性和不确定性,使语言结构的类型划分不唯一,遇到具有二义性的词或结构复杂的句子时,就不能准确识别和分析。
2. 计算机对自然语言的理解,目前主要以理解“语义”为核心,但是由于计算机不能像人一样智能,因此不能准确把握语义,同时计算机没有对用户“意图”分析,理解的结果是孤立的,并没有联系用户需求。
3. 面向自然语言处理的语法研究还不完善,只有当计算机“吸收”了语言学家的知识之后,计算机理解自然语言才能称为现实。
现有的问答系统中,一般都是对问题进行分词处理,并提取出关键词,之后进行关键词扩展。但并没有对问题的实质——从汉语语法角度进行剖析,对疑问句句型研究的很少,信息检索时也没有针对性,而是“泛泛而搜”,因此导致系统的正确率不高。
因此一个问题解析模块,应该能够完成下面几个功能:
1. 词法分析:包括分词、词性标注、关键词与主题词提取;
2. 句法分析:包括句法树生成、句型匹配;
3. 问题分类:包括问题类别确定、问句扩展、相关问题计算、答案模型生成;
信息检索模块
在问答系统中,信息检索模块主要从文档库中是把和问题有关的文档找出来,即信息索引。由于问答系统中文档库一般比较大,如果没有一个高效、快速的检索模块,问答系统将很难快速的回答用户的问题。另外信息检索模块需要能够从本地知识库和网络知识库获取信息。(当然Waston在比赛的时候仅仅使用了本地知识库,很拉风。)
答案抽取和排序模块
一般搜索引擎返回的是一堆网页,而问答系统需要返回的是简短的答案。答案的形式可以是词语、句子、段落或者文摘。
询问时间、地点、人物、一般名词、数目的问句一般返回类型为词语,可以按照专家规则进行匹配提取。(询问时间,必须包含时间信息)
询问状态、原因、动作的问题一般返回句子或段落
询问事件的问题一般返回文摘。
问题答案在抽取之后还需要进行排序,之后返回给用户。
这里对技术细节并没有过多介绍,具体可参考资源列表。
Question Answering 介绍了各种问答系统实体和资源。
Apache UIMA Apache出品,非结构化信息处理框架。Waston 扩展了该框架。
QuestionAnsweringSystem ,Github 开源,基于Waston。
AIML 2.0 AIML是在xml基础上扩展的“人工智能标记语言”,简单的讲就是基于xml的格式,用于计算机处理AI信息的一种标记语言,基于此开发的问答系统,效果还不错。
OpenEphyra ,一个使用 Java 开发的模块化、可扩展的问答系统。
原创文章,转载请注明出处。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

