机器学习实战:模型评估和优化
监督学习的主要任务就是用模型实现精准的预测。我们希望自己的机器学习模型在新数据(未被标注过的)上取得尽可能高的准确率。换句话说,也就是我们希望用训练数据训练得到的模型能适用于待测试的新数据。正是这样,当实际开发中训练得到一个新模型时,我们才有把握用它预测出高质量的结果。
因此,当我们在评估模型的性能时,我们需要知道某个模型在新数据集上的表现如何。这个看似简单的问题却隐藏着诸多难题和陷阱,即使是经验丰富的机器学习用户也不免陷入其中。我们将在本文中讲述评估机器学习模型时遇到的难点,提出一种便捷的流程来克服那些棘手的问题,并给出模型效果的无偏估计。
问题:过拟合与模型优化
假设我们要预测一个农场谷物的亩产量,其亩产量与农场里喷洒农药的耕地比例呈一种函数关系。我们针对这一回归问题已经收集了100个农场的数据。若将目标值(谷物亩产量)与特征(喷洒农药的耕地比例)画在坐标系上,可以看到它们之间存在一个明显的非线性递增关系,数据点本身也有一些随机的扰动(见图1)。
为了描述评价模型预测准确性所涉及的一些挑战,我们从这个例子说开去。

图1:信噪比
现在,假设我们要使用一个简单的非参数回归模型来构建耕地农药使用率和谷物亩产量的模型。最简单的机器学习回归模型之一就是内核平滑技术。内核平滑即计算局部平均:对于每一个新的数据来说,用与其特征值接近的训练数据点求平均值来对其目标变量建模。唯一一个参数——宽参数,是用来控制局部平均的窗口大小。
图2演示了内核平滑窗宽参数取值不同所产生的效果。窗宽值较大时,几乎是用所有训练数据的平均值来预测测试集里每个数据点的目标值。这导致模型很平坦,对训练数据分布的明显趋势欠拟合(under-fit)了。同样,窗宽值过小时,每次预测只用到了待测数据点周围一两个训练数据。因此,模型把训练数据点的起伏波动完完全全地反映出来。这种疑似拟合噪音数据而非真实信号的现象被称为过拟合(over-fitting)。我们的理想情况是处于一个平衡状态:既不欠拟合,也不过拟合。
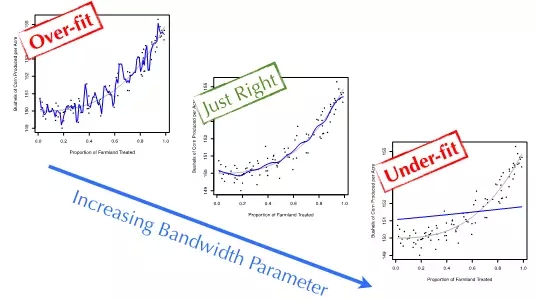
图2:三种平滑回归模型对谷物产量数据的拟合。
现在,我们再来重温一遍问题:判断分析机器学习模型对预测其它农场的谷物产量的泛化能力。这个过程的第一步就是选择一个能反映预测能力的评估指标(evaluation metric)。对于回归问题,标准的评估方法是均方误差(MSE),即目标变量的真实值与模型预测值的误差平方的平均值。
这正是令人棘手的地方。当我们拟合训练数据时,模型预测的误差(MSE)随着窗宽参数的减小而减小。这个结果并不出人意料:因为模型的灵活度越高,它对训练数据模式(包括信号和噪音)的拟合度也越好。然而,由于窗宽最小的模型拟合了训练数据的每一处随机因素导致的波动,它在训练数据集上出现了严重的过拟合情况。若用这些模型来预测新的数据将会导致糟糕的准确率,因为新数据的噪音与训练数据的噪音模式不尽相同。
所以,训练集的误差和机器学习模型的泛化误差(generalization error)存在分歧。在图3所示谷物产量数据的例子中可以看到这种分歧。对于较小的窗口参数值,训练数据集的MSE非常小,而在新数据(10000个新数据)上的MSE则大得多。简单地说,一个模型在训练集上的预测效果并不能反映出它在新数据集上的预测效果。因此,把模型的训练数据直接当作验证数据是一件非常危险的事情。
使用训练数据的注意事项
用同一份训练数据来拟合模型和评价模型,会使得你对模型的效果过于乐观。这可能导致你最终选择了一个次优的模型,在预测新数据时表现平平。
如我们在谷物产量的例子中所见,若按照最小化训练集MSE的原则优化,则得到窗宽参数最小的模型。这个模型在训练集上的MSE为0.08。但是,若用新的数据测试,同样的模型得到的MSE达到0.50,效果比优化模型糟糕的多(窗宽0.12,MSE=0.27)。
我们需要一个评价指标,能更好地估计模型在新数据集上的效果。这样,我们在用模型预测新数据集时有把握取得一个较好的准确率。下一节我们将讨论这个话题。
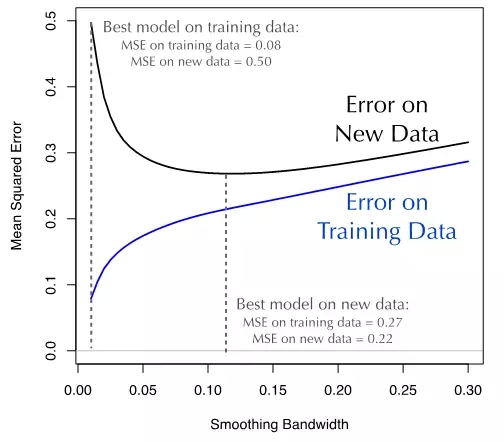
图3:谷物产量回归问题,训练集上误差和新数据集上误差的比较。训练集误差过于乐观地反映了模型在新数据集上的效果,尤其是在窗宽参数值较小的情况下。很显然,用模型在训练集上的误差来替代其在新数据集上的误差,会给我们带来许多麻烦。
解决方案:交叉验证
我们已经剖析了模型评估的难解之处:模型在训练集数据上的误差不能反映其在新数据集上的误差情况。为了更好地估计模型在新数据集上的错误率,我们必须使用更复杂的方法,称作交叉验证(cross validation),它严格地使用训练集数据来评价模型在新数据集上的准确率。
两种常用的交叉验证方法是holdout方法和K-fold交叉验证。
Holdout 方法
同一份训练数据既用于数据拟合又用于准确率评估,会导致过度乐观。最容易的规避方法是分别准备训练和测试的两个子数据集,训练子集仅用于拟合模型,测试子集仅用于评估模型的准确率。
这个方法被称作是holdout方法,因为随机地选择一部分训练数据仅用于训练过程。通常保留30%的数据作为测试数据。holdout方法的基本流程如图4所示,Python的伪代码详见列表1.
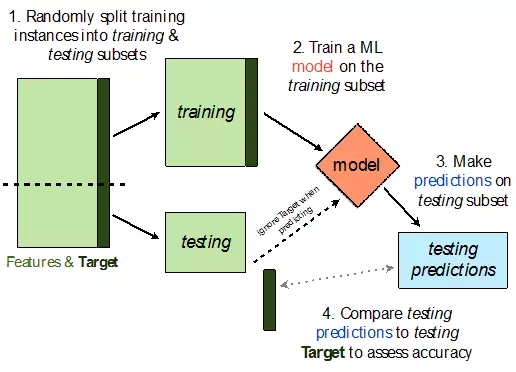
图4:Holdout交叉验证的流程图。深绿色的方块表示目标变量。

列表1:Holdout方法的交叉验证
我们接下去把Holdout方法应用于谷物产量的数据集上。对于不同的窗宽参数,我们应用Holdout方法(三七开)并且在剩余的30%数据上计算预测值的MSE。图5演示了Holdout方法得到的MSE是如何估计模型在新数据集上的MSE。有两点需要关注:
Holdout方法计算得到的误差估计非常接近模型在“新数据集”的误差。它们确实比用训练集数据得到的误差估计更接近(图3),尤其是对于窗口参数值较小的情况。
Holdout方法的误差估计有很多噪音。相比从新数据得到的光滑的误差曲线,其跳跃波动很厉害。
我们可以反复地随机切分训练-测试数据集,对结果求平均值,以减小噪音影响。然而,在多次迭代中,每一个数据点被分配到测试数据集的概率并不一定,这将导致我们的结果存在偏差。
更好的一种方法是K-fold交叉验证。
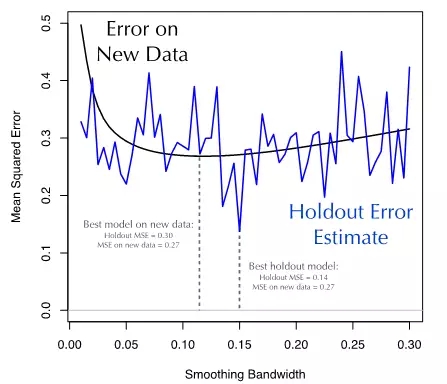
图5:在谷物产量数据集上比较Holdout方法的MSE与新数据集的MSE。Holdout误差是每个模型在新数据集上的一个无偏误差估计。但是,它的估计值存在很大的噪音,在优化模型的窗宽附近(窗宽=0.12)其误差波动范围是0.14~0.40。
K-Fold交叉验证
一种更好,但是计算量更大的交叉验证方法是K-fold交叉验证。如同Holdout方法,K-fold交叉验证也依赖于训练数据的若干个相互独立子集。主要的区别在于K-fold交叉验证一开始就随机把数据分割成K个不相连的子集,成为folds(一般称作K折交叉验证,K的取值有5、10或者20)。每次留一份数据作为测试集,其余数据用于训练模型。
当每一份数据都轮转一遍之后,将预测的结果整合,并与目标变量的真实值比较来计算准确率。K-fold交叉验证的图形展示如图6所示,列表2是伪代码。
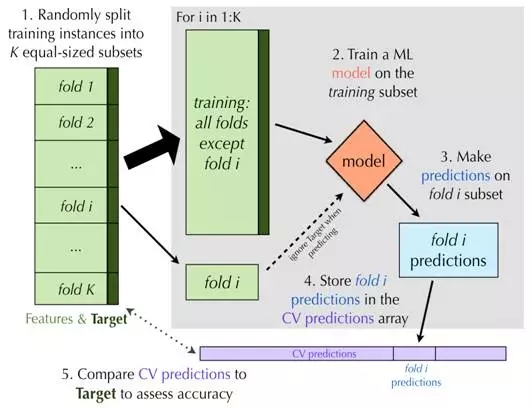
图6: K-fold交叉验证的流程图。
最后,我们把K-fold方法用于谷物产量数据集上。对于不同从窗宽参数,我们选择K=10的K-fold交叉验证方法,并计算预测值的准确率。图7演示了K-fold方法得到的MSE是如何估计模型在新数据集上的MSE。显然,K-fold交叉验证的误差估计非常接近模型在新数据上的误差值。

列表2:K-fold交叉验证

图7:在谷物产量数据集上比较K-fold方法的MSE与新数据集的MSE。K-fold交叉验证得到的误差很好地验证了模型在新数据集上的效果,使得我们能够大胆地估计模型的误差以及选择最优模型。
使用交叉验证的几点注意事项
交叉验证为我们在实际使用机器学习模型时提供了一种估计准确率的方法。这非常有用,使得我们能够挑选出最适于任务的模型。
但是,在现实数据中应用交叉验证方法还有几点注意事项需要关注:
在K-fold方法交叉验证中K的值选的越大,误差估计的越好,但是程序运行的时间越长。
解决方法:尽可能选取K=10(或者更大)。对于训练和预测速度很快的模型,可以使用leave-one-out的教程验证方法(即K=数据样本个数)。
交叉验证方法(包括Holdout和K-fold方法)假设训练数据的分布能代表整体样本的分布。如果你计划部署模型来预测一些新数据,那么这些数据的分布应该和训练数据一致。如果不一致,那么交叉验证的误差估计可能会对新数据集的误差更加乐观。
解决方法:确保在训练数据中的任何潜在的偏差都得到处理和最小化。
一些数据集会用到时序相关的特征。例如,利用上个月的税收来预测本月的税收。如果你的数据集也属于这种情况,那你必须确保将来的特征不能用于预测过去的数值。
解决方法:你可以构造交叉验证的Holdout数据集或者K-fold,使得训练数据在时序上总是早于测试数据。
总结
我们一开始讨论了模型评价的通用法则。很显然,我们不能交叉使用同一份训练数据,不能既用来训练又用来评估。相反,我们引入了交叉验证这种更可靠的模型评价方法。
Holdout是最简单的交叉验证方法,为了更好地估计模型的通用性,分割一部分数据作为待预测的测试数据集。
K-fold交叉验证 —— 每次保留K份数据中的一份 —— 能够更确定地估计模型的效果。这种改进的代价来自于更高的计算成本。如果条件允许,K等于样本数目时能得到最好的估计,也称为leave-one-out方法。
介绍了模型评价的基本流程。简单来说就是:
获取数据并做建模前的预处理(第二章),并且确定合适的机器学习模型和算法(第三章)。
构建模型,并根据计算资源选择使用Holdout或者K-fold交叉验证方法预测数据。
用所选取的指标评估预测结果。如果是分类的机器学习方法,在4.2节里会介绍常见的效果评价指标。同样,我们会在4.3小节介绍回归问题的常用评价指标。
不断调整数据和模型,直到取得理想的效果。在5~8章中,我们会介绍真实场景下用于提高模型效果的常用方法。
对于分类模型,我们介绍了几个用于上述流程中步骤3的模型性能指标。这些技术包括简单的准确率计算,混淆矩阵,ROC,ROC曲线和ROC曲线下面积。
在回归模型中,我们介绍了均方根误差(rMSE)与R平方估计(R-squared),我们讨论了简单的可视化,如预测与实际的散点图和残差图。
我们介绍了调整参数的概念,并展示了如何使用网格搜索算法的参数优化模型。
原文链接:Real-World Machine Learning: Model Evaluation and Optimization
作者:Henrik Brink, Joseph W. Richards, Mark Fetherolf
欢迎加入本站公开兴趣群
商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

