PCA模型加先验
大清牛人曰:ML派坐落美利坚合众山中,百年来武学奇才辈出,隐然成江湖第一大名门正派,门内有三套入门武功,曰:图模型加圈,神经网加层,优化目标加正则。有童谣为证:熟练ML入门功,不会作文也会诌。今天就介绍一个PCA加先验的工作。
主成分分析 (PCA)
PCA是常用的数据降唯模型。PCA处理的数据中心点为零点 

使得中心点为零点。PCA降唯的思路:1)找到
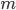
个相互正交并且使得投影方差最大的方向(专业一点的说法是找到一组使得方差最大的基),2)将k维的数据投影到这m个方向上,得到m维数据。因为m会小于k,数据的维度下降了。这里最难理解的部分就是“使得投影方差最大”了。
什么是“使得投影方差最大”?数据 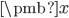
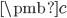 方向的投影(标投影)为
方向的投影(标投影)为 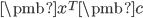 ,其中方向为单位向量
,其中方向为单位向量 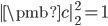 。一堆数据
。一堆数据 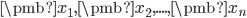 在
在 方向的投影为一堆数:
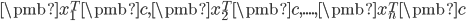
。“使得投影方差最大”是使得这堆数的方差最大。当然啦,PCA是找到m个方向,因此“使得投影方差最大”应该是使得m堆数的方差之和最大。
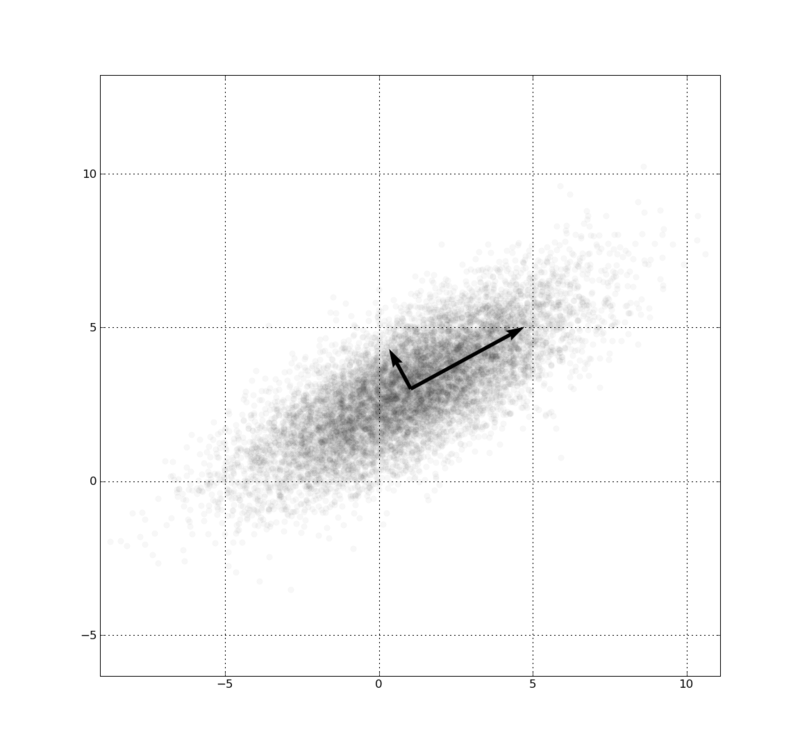
为什么要“使得投影方差最大”呢?我们看下图,如果要把图中的数据压缩到一维,我们是选择右上方向还是左上方向呢?我们当然应该选右上方向! 因为右上方向上数据点散得比较开,压缩之后不同的数据点也好区分;而左上方向上数据点比较密集,不同数据压缩之后变相同的概率比较大。在中心点为零点的情况下,“散得开不开”可以用这个方向上的投影方差刻画。方差比较大,“散得比较开”;方差比较少,“挤得密集”。因此我们需要“使得投影方差最大”。同时,这也是为什么PCA需要预处理数据使得中心点为零点。
让 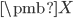
 表示PCA要找的方向,其中每一列代表一个方向。数据在不同方向的投影方差和等于
表示PCA要找的方向,其中每一列代表一个方向。数据在不同方向的投影方差和等于 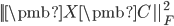
,也就是等于
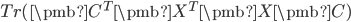
。因此PCA需要求解如下优化问题。
/begin{eqnarray}
& max_{/pmb{C}}& Tr(/pmb{C}^T/pmb{X}^T/pmb{X}/pmb{C}) /nonumber //
& subject:& /pmb{C}^T/pmb{C} = /pmb{I}
/end{eqnarray}
上面的优化问题利用了 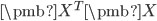
为不同变量的协方差矩阵。PCA模型也可以基于协方差矩阵来解释,这里就不介绍了,有兴趣的同学可以看参考文献一。求解上面的优化问题蛮简单的,因为 前m个特征向量就是答案!!!一旦求得 ,压缩之后的数据为

。
海量多标记分类
介绍完PCA的基本知识,再来介绍一个PCA加先验的工作。这个工作都应用在海量多标记分类任务上。在多标记分类问题,一个实例同时拥有多个类别(标记)。比如一篇关注全球变暖的新闻报道既属于科学类别,也属于环境类别。有些任务中标记数量特别巨大,我们称之为海量多标记分类。比如多标记分类可以应用于标签推荐任务中,标签数量成千上万。用 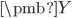
表示已经去中心化之后的标记矩阵,其中每一行代表一个实例的标记情况;用
表示实例,其中每一行代表一个实例的特征。
我们自然会想着把标记向量降维到一个低维向量,然后学习一个从实例到低维向量的模型,最后从低维向量还原出标记来(妈蛋!!什么叫自然!!!09年才有人这么做好吧!!!)。作为最常用的数据降维方法,自然有人将PCA应用在这个问题上。但只用PCA是有缺陷的。PCA只会考虑怎么有效地将标记向量压缩成低维向量,但低维向量是否适合学习就不管了。压缩得到的低维向量和实例特征有可能没有一点相关性,导致很难学习到一个从实例到低维向量的模型。这时候我们就应该往PCA模型加点“容易学习”的先验了。
Chen et al (2012) 假设实例到低维向量的模型是线性模型 
,这时“容易学习”的先验知识可以表示为
/begin{eqnarray}
min||/pmb{X}/pmb{W} - /pmb{Y}/pmb{C}||_F^2 /nonumber //
/end{eqnarray}
根据最小二乘法,我们得
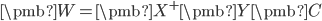
。
将这个“容易学习”的先验加入PCA,我们能够得到
/begin{eqnarray}
& max_{/pmb{C}}& ||/pmb{Y}/pmb{C}||_F^2 - ||/pmb{X}/pmb{W} - /pmb{Y}/pmb{C}||_F^2 /qquad subject: /pmb{C}^T/pmb{C} = /pmb{I} /nonumber //
/Rightarrow
& max_{/pmb{C}}& tr(/pmb{C}^T/pmb{Y}^T /pmb{Y}/pmb{C}) - /pmb{C}^T/pmb{Y}^T (/pmb{I} - /pmb{X}/pmb{X}^{+}) /pmb{Y}/pmb{C} /qquad subject: /pmb{C}^T/pmb{C} = /pmb{I} /nonumber //
/Rightarrow
& max_{/pmb{C}}& tr(/pmb{C}^T/pmb{Y}^T /pmb{X}/pmb{X}^{+} /pmb{Y}/pmb{C}) /qquad subject: /pmb{C}^T/pmb{C} = /pmb{I} /nonumber //
/end{eqnarray}
求解上面的优化问题就可以将“容易学习”的先验加入PCA,使之适用于海量多标记分类任务。而且求解上面的问题也是蛮简单的,只要求解
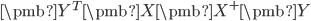
前m个特征向量即可。
参考文献
http://www.cse.psu.edu/~rtc12/CSE586Spring2010/lectures/pcaLectureShort_6pp.pdf
Chen, Yao-Nan, and Hsuan-Tien Lin. "Feature-aware label space dimension reduction for multi-label classification." Advances in Neural Information Processing Systems. 2012.
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

