【译】大数据分析平台搭建教程:基于Apache Zeppelin Notebook和R的交互式数据科学

介绍
这篇文章的目的是帮助您开始使用 Apache Zeppelin Notebook,它可以满足您用R做数据科学的需求。Zeppelin 是一个提供交互数据分析且基于Web的笔记本。方便你做出可数据驱动的、可交互且可协作的精美文档,并且支持多种语言,包括 Scala(使用 Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、 Markdown、Shell等等。
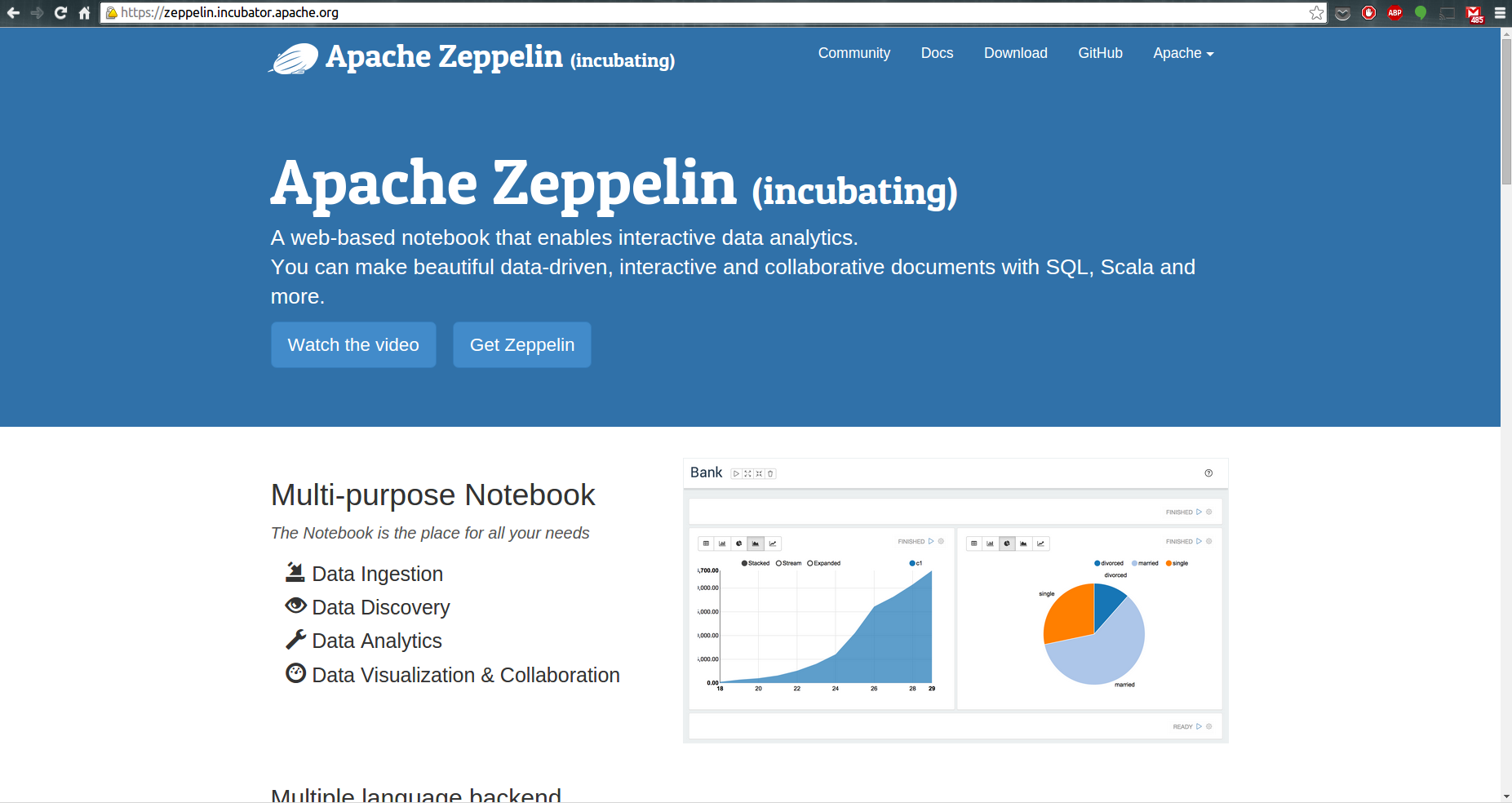
然而,最新的官方版本是0.5.0,还不支持R编程语言。幸运的是,NFLabs公司做了个开源项目,让我提供了一个R的编译器。这个编译器是让用户可以使用自定义的语言做为数据处理后端的一个 Zeppelin 插件。例如在 Zeppelin 使用scala代码,您需要一个 Spark编译器。所以,如果你像我一样有足够的耐心将R集成到Zeppelin中, 这个教程将告诉你怎样从源码开始配置 Zeppelin和R。
准备工作
-
我们将通过Bash shell在Linux上安装Zeppelin。如果您使用的是Windows操作系统,我建议您安装和使用Cygwin终端(它提供功能类似于Windows上的Linux发行版)。
-
确保 Java 1.7 和 Maven 3.2.x 是已经安装并且配置到环境变量中。
从源代码构建 Zeppelin
第一步:下载 Zeppelin 源代码
去这github分支下载源代码,将这个链接复制并粘贴到你的浏览器: https://github.com/elbamos/incubator-zeppelin/tree/rinterpreter
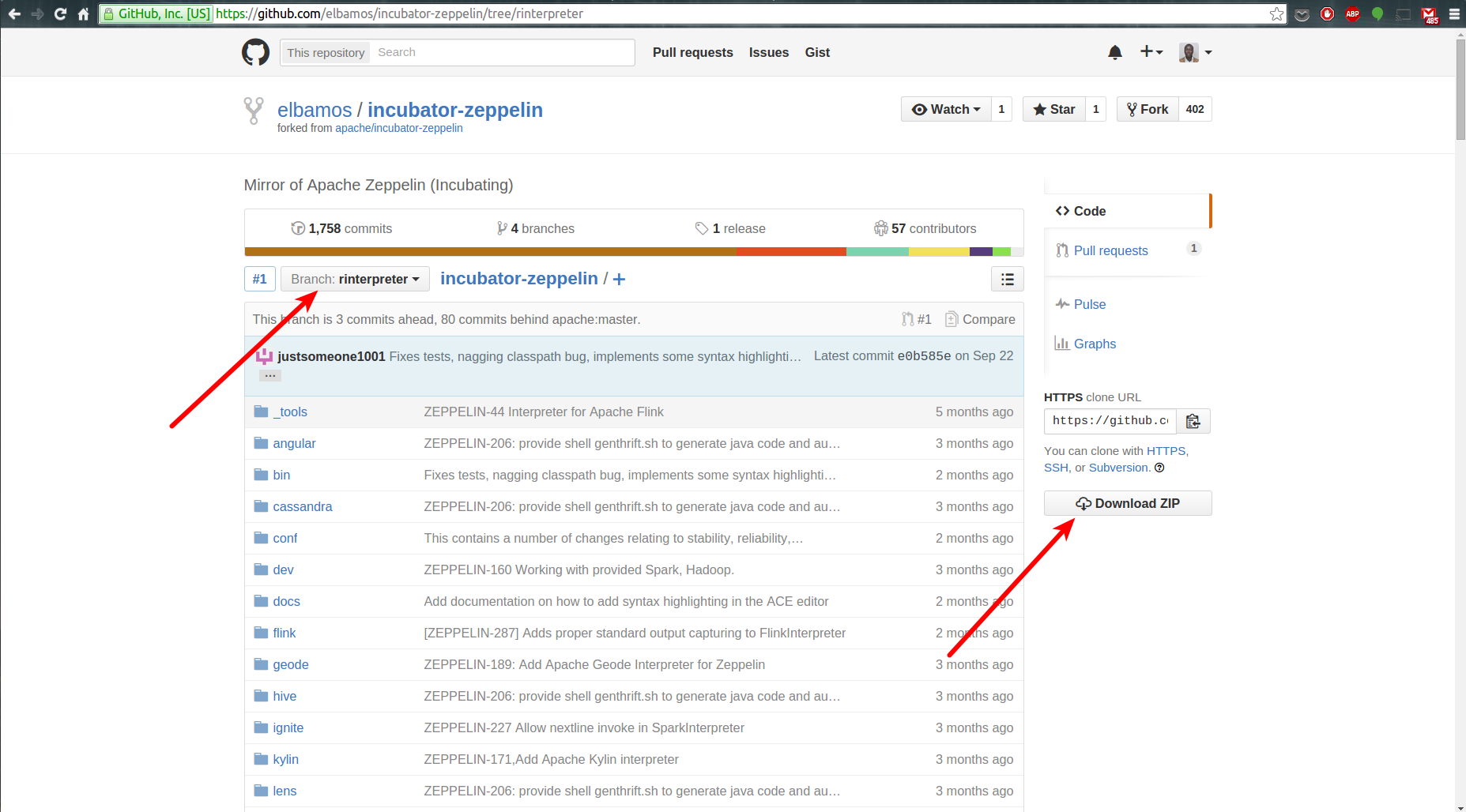
在我的例子中我已经下载并解压文件夹在我的桌面
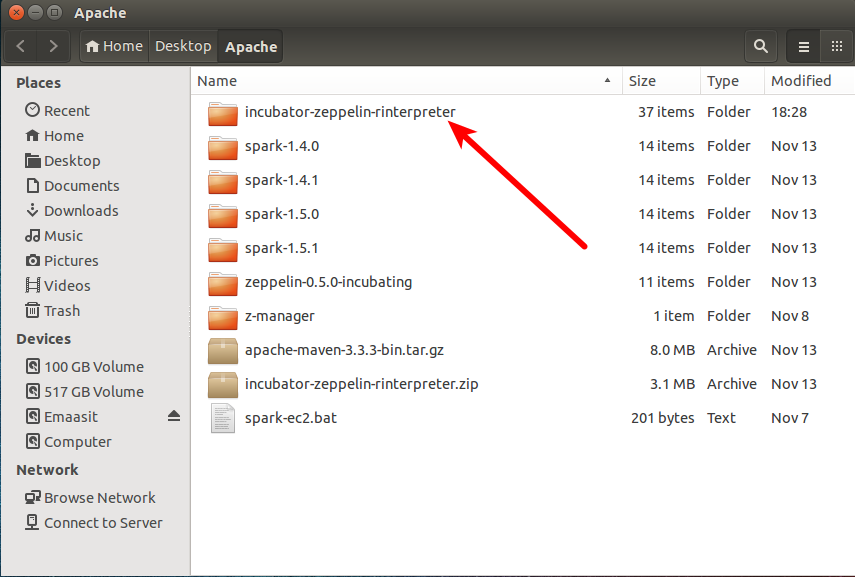
第二步:构建 Zeppelin
假设你是安装在单机,打开你的Terminal,运行下面的代码。如果你是安装在一个集群,会稍微复杂一点,具体步骤 Zeppelin 的文档 中找到。
$ cd Desktop/Apache/incubator-zeppelin-rinterpreter $ mvn clean package -DskipTests 
这将需要约16分钟构建Zeppelin、Spark,所有引擎包括R,markdown,shell,hive等。(见下图)。
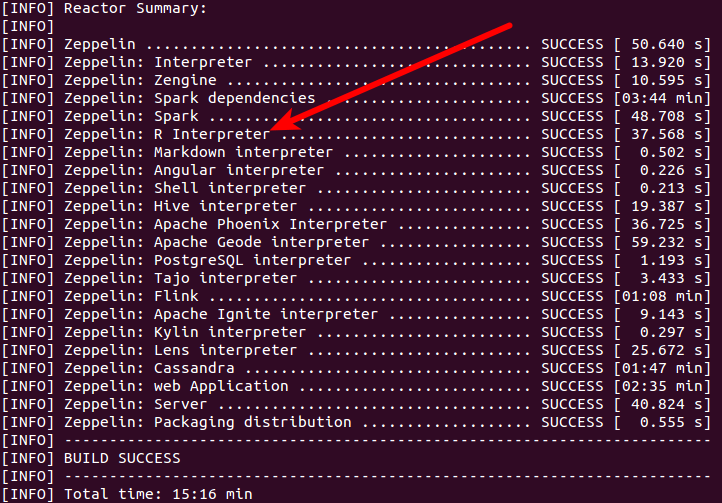
第三步:启动 Zeppelin
运行以下命令启动Zeppelin:
$ ./bin/zeppelin-daemon.sh start  打开web浏览器,访问 http://localhost :8080。此时,您已经准备好开始在 Zeppelin 用代码创建交互笔记本。
打开web浏览器,访问 http://localhost :8080。此时,您已经准备好开始在 Zeppelin 用代码创建交互笔记本。
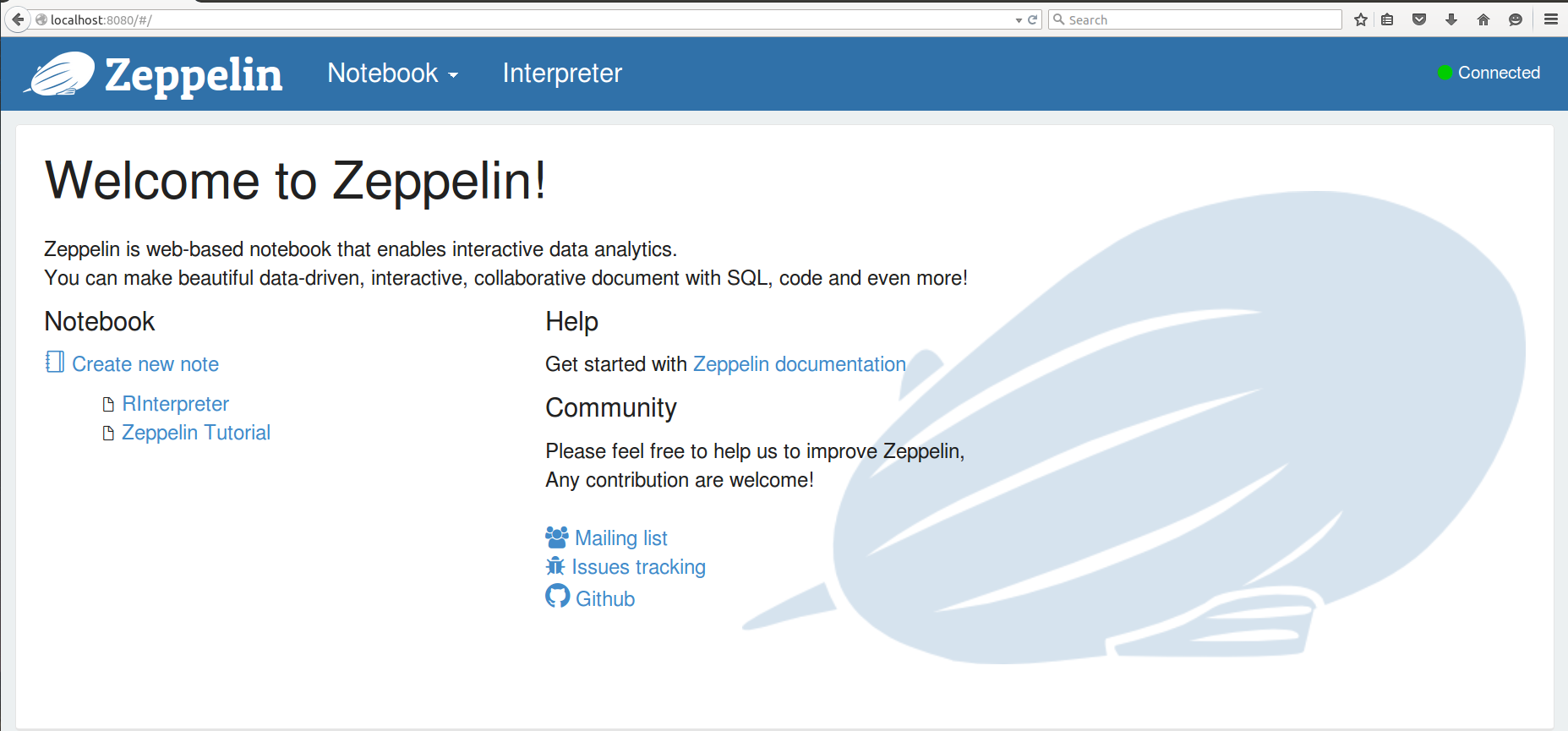
交互式数据科学
第一步:创建一个笔记本
单击下拉箭头旁边的“笔记本”页面,点击“创建新报告”。

给你的笔记本命名或您可以使用指定的缺省名称。我命名为“Base R in Apache Zeppelin”。
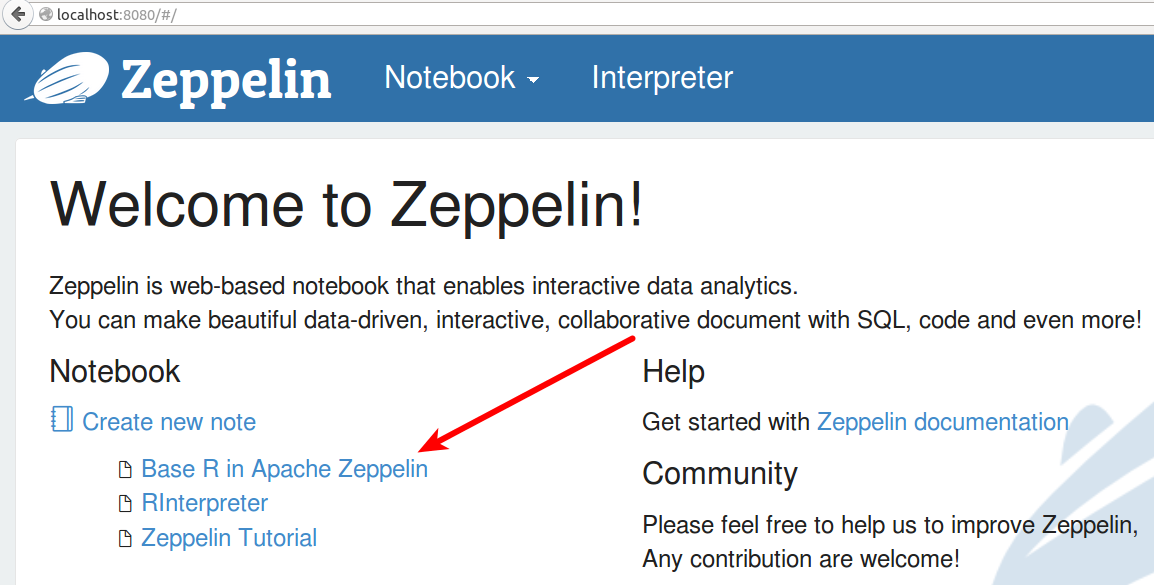
第二步:开始你的分析
如下图所示,调用R可以用“%spark.r”或“%spark.knitr”标签。首先让我们用 markdown 写一些介绍。

根据我们可能需要我们的分析,现在让我们来安装一些包。
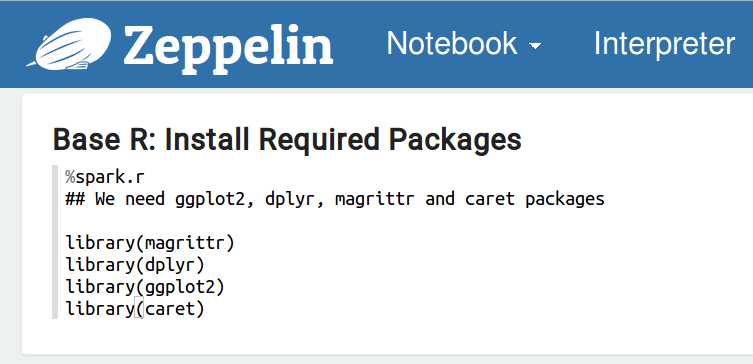
我们将使用“flights”数据集显示2013年离开纽约的航班,现在让我们读取数据集。
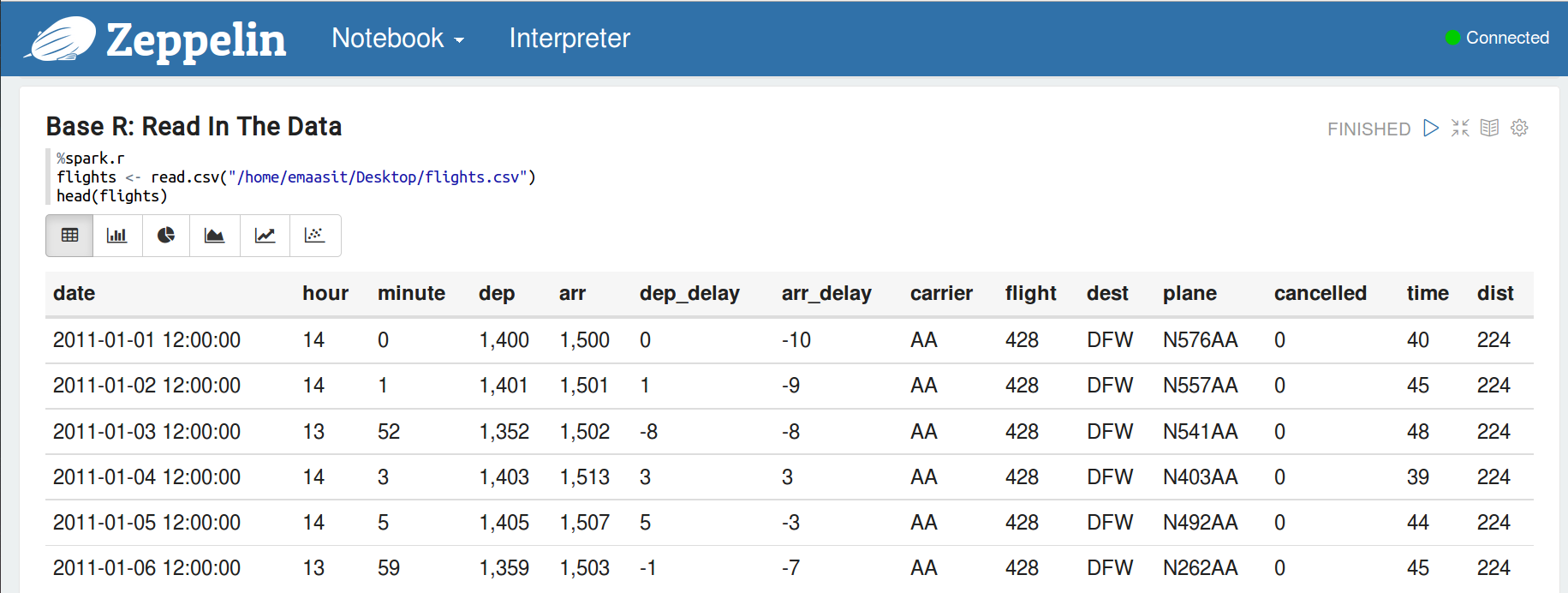
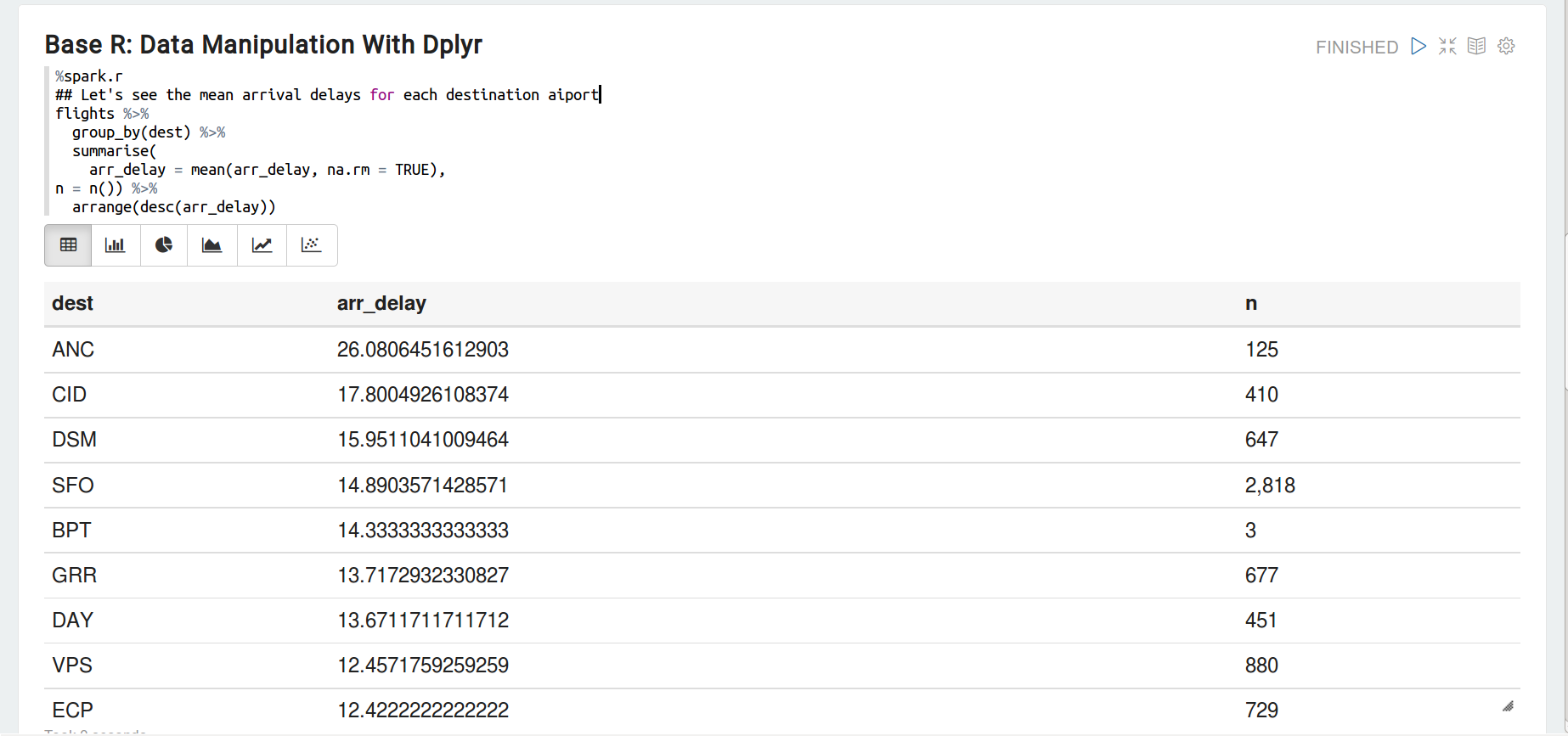
现在,让我们使用dplyr(用管道符)做一些数据操作。
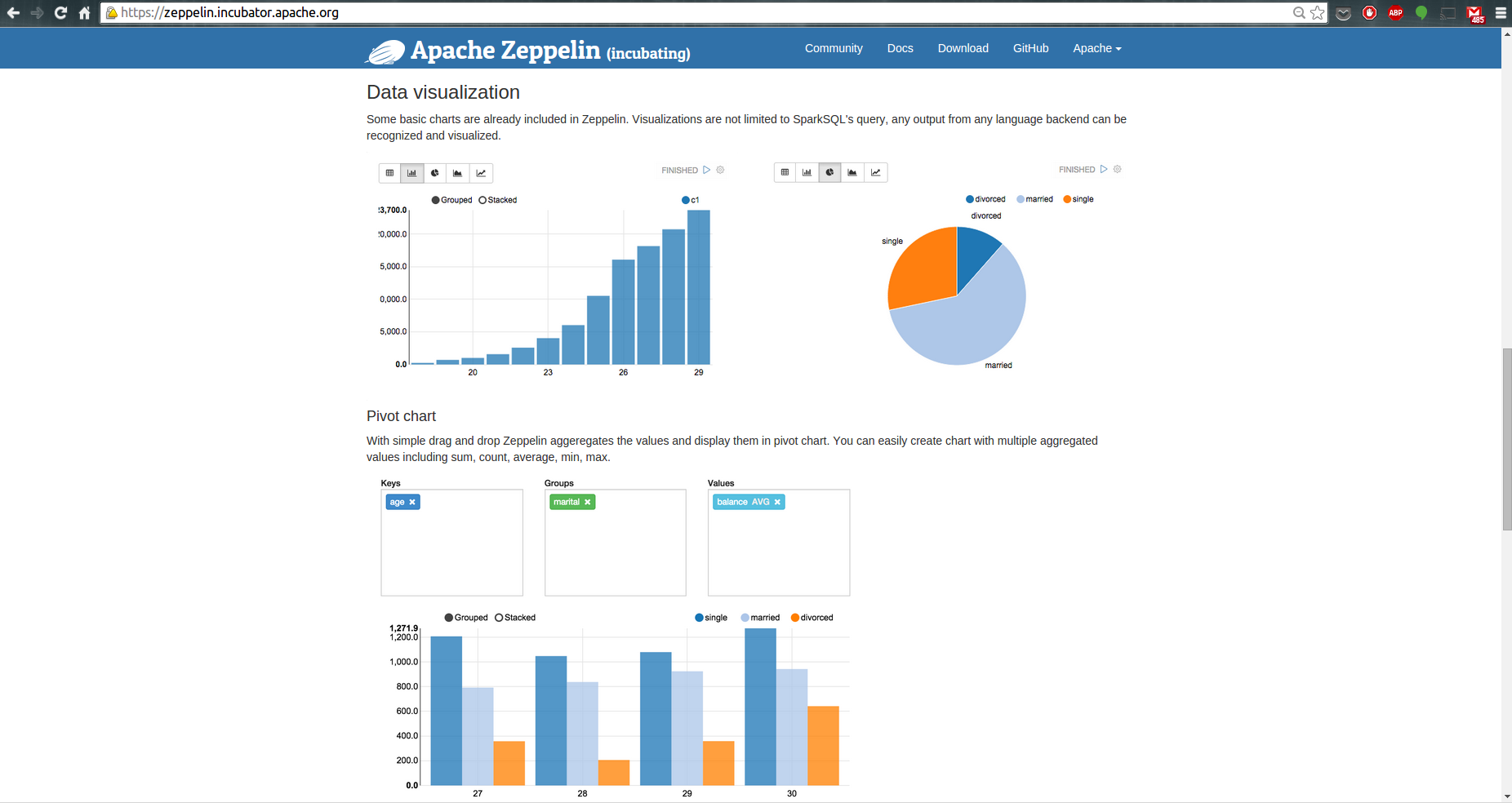
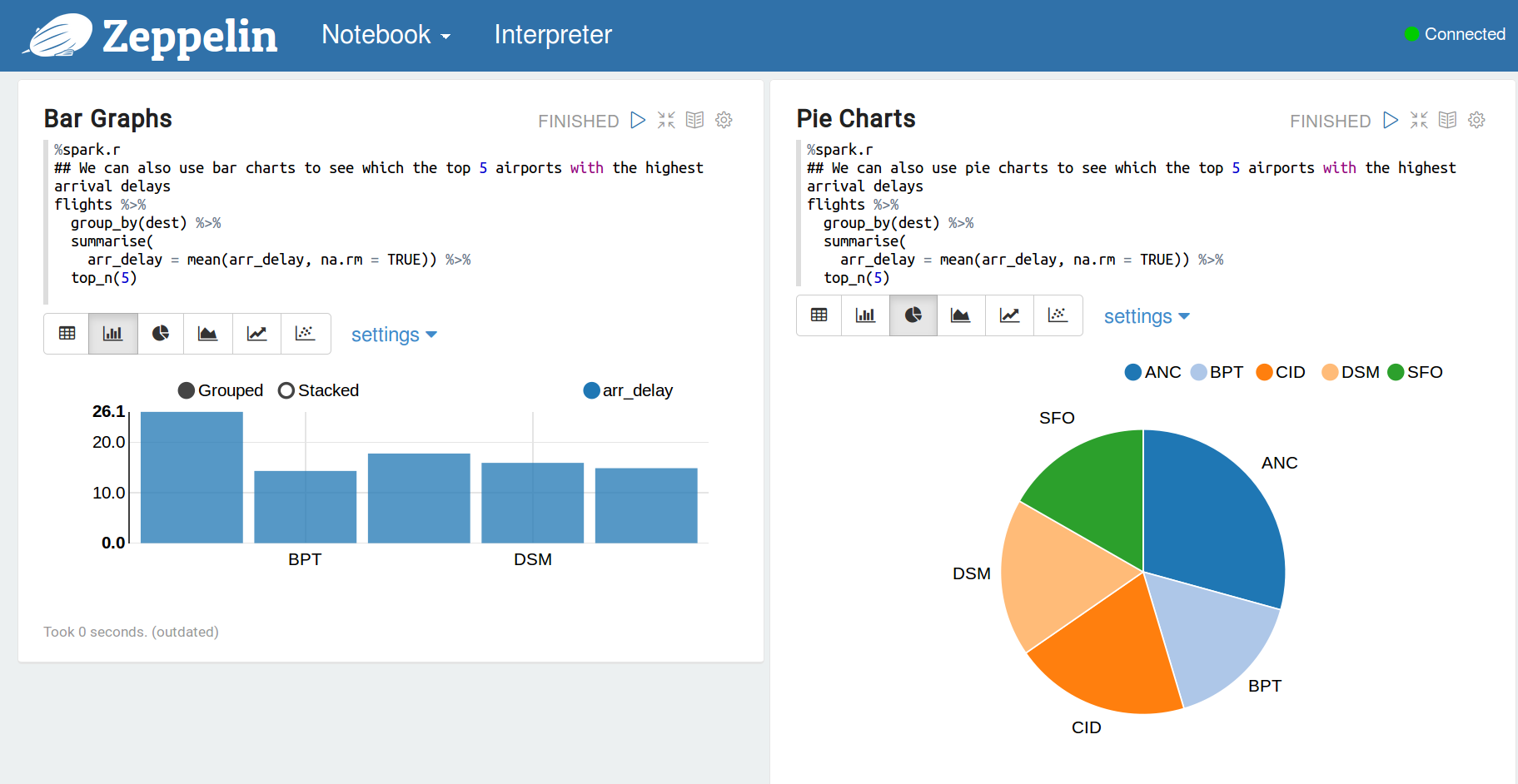
您还可以使用条形图和饼图来可视化一些描述性统计数据。
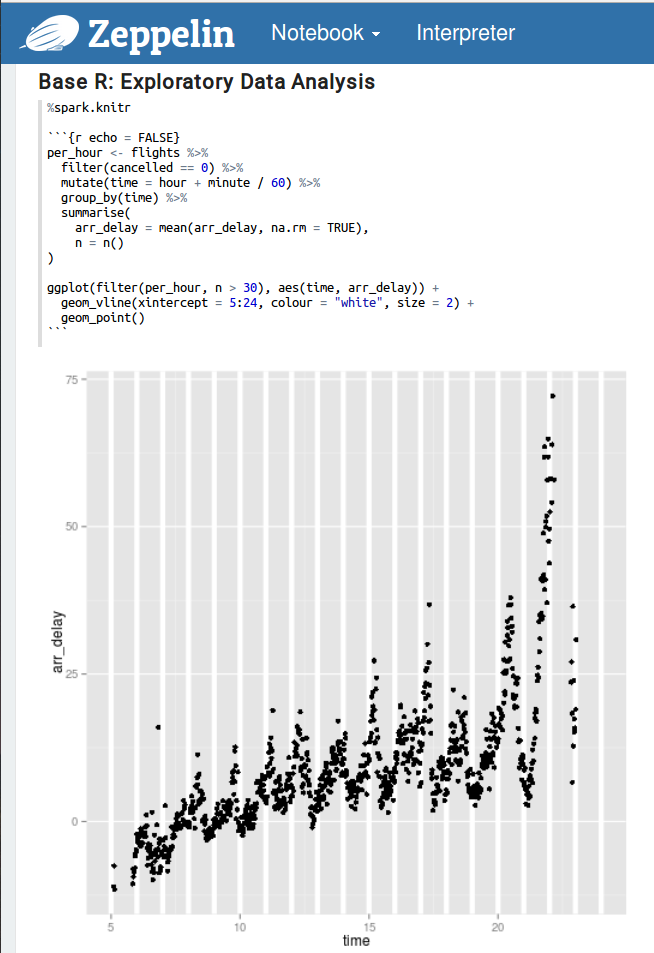
现在,让我们与ggplot2共舞。
现在,让我们用 caret 包做一些统计的机器学习。
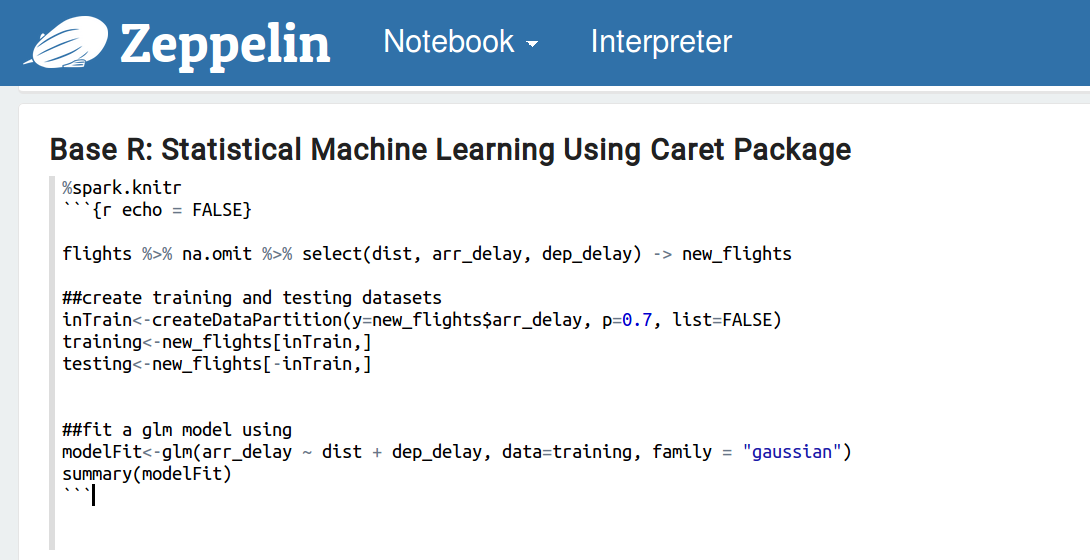
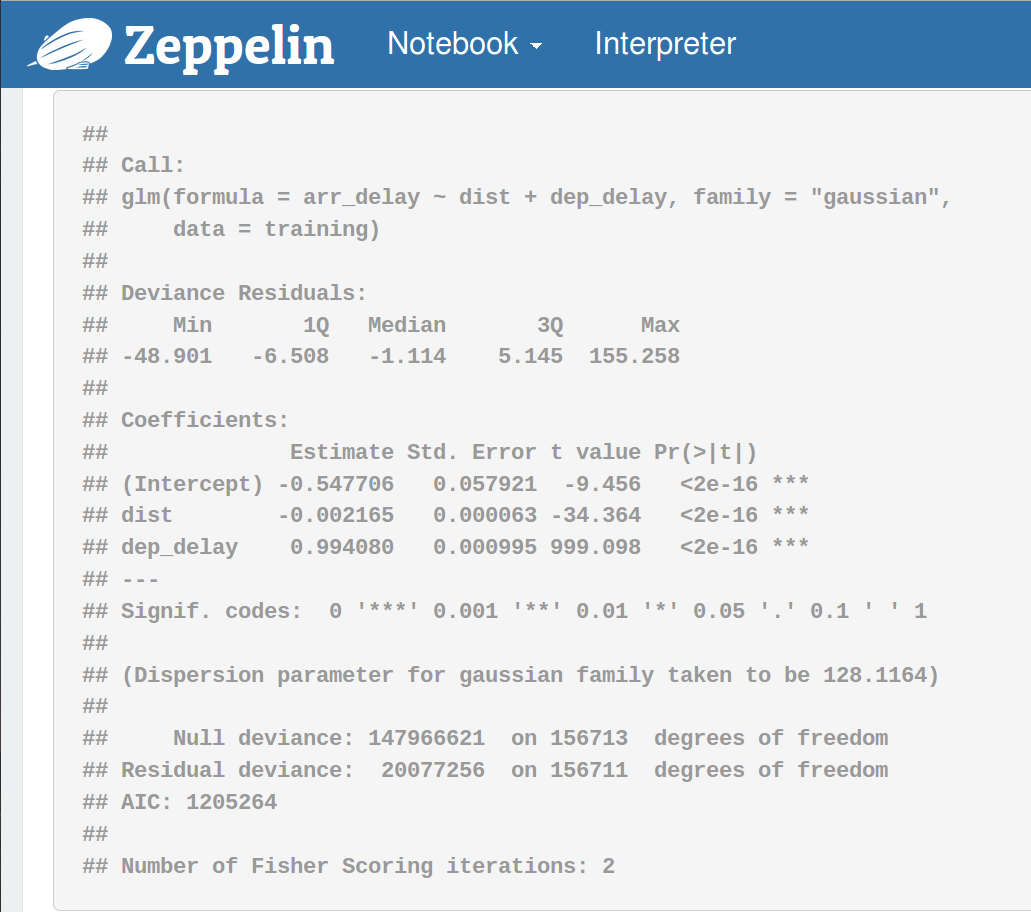
最后,绘制几个地图。

结束语
Zeppelin 帮助您使用多种编程语言创建交互式文档和美丽的图表。这篇文章的目的是帮助你配置 Zeppelin 和 R。希望这牛逼的的项目管理委员会(PMC)的开源项目可以用R引擎发布下一个版本。到时候安装 Zeppelin肯定会更快更方便,而不必从源代码构建。
还值得一提的是,还有另一个R的编译器是由 Data Layer 提供的。你可以在这里找到说明如何使用: https://github.com/datalayer/zeppelin-R 。
你可以尝试着两个编译器,然后然后在下面的评论区分享一下你的使用体验。
Data Layer提供的编译器
RCharts
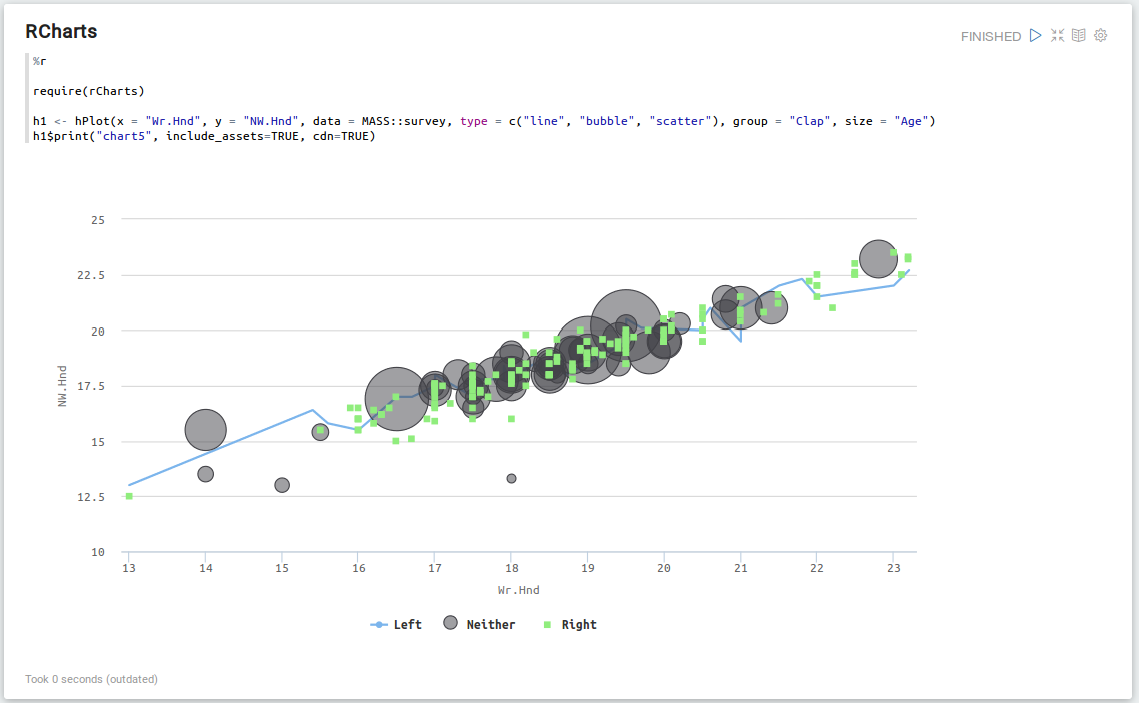
Rchats Map

GoogleViz
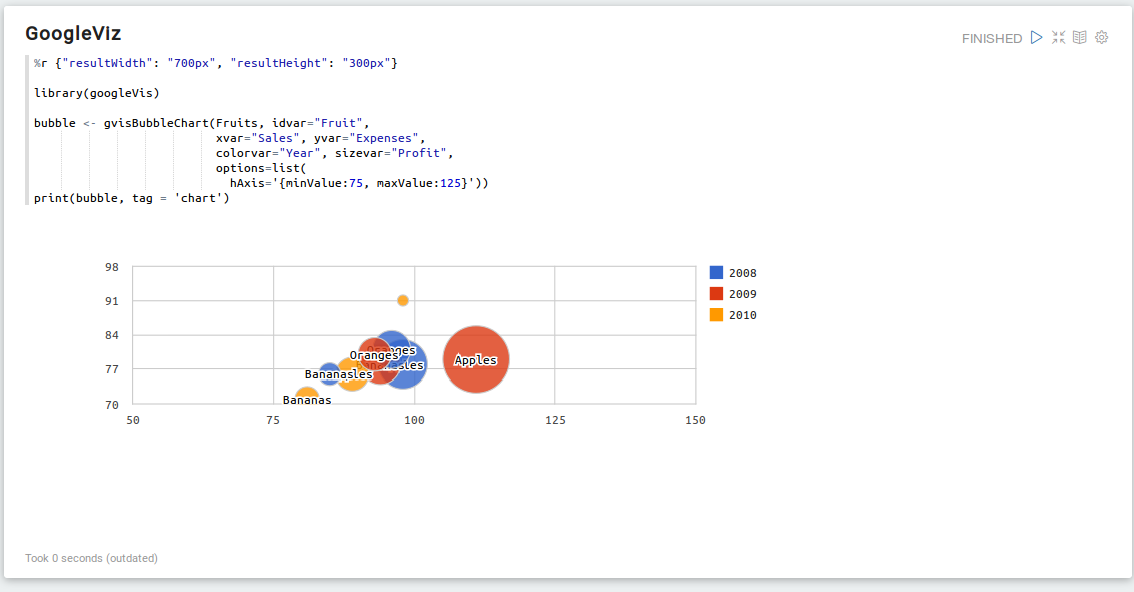
Scala R Binding

R Scala Dataframe Binding
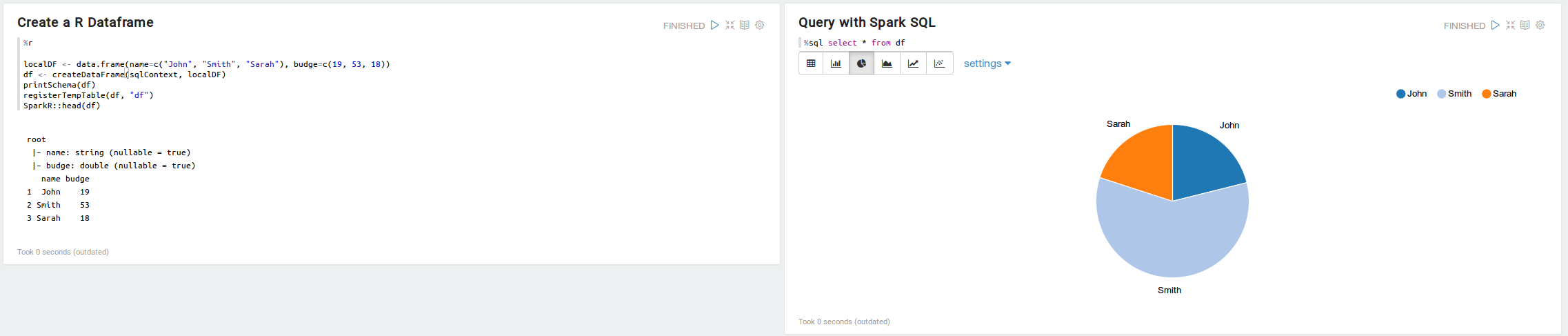
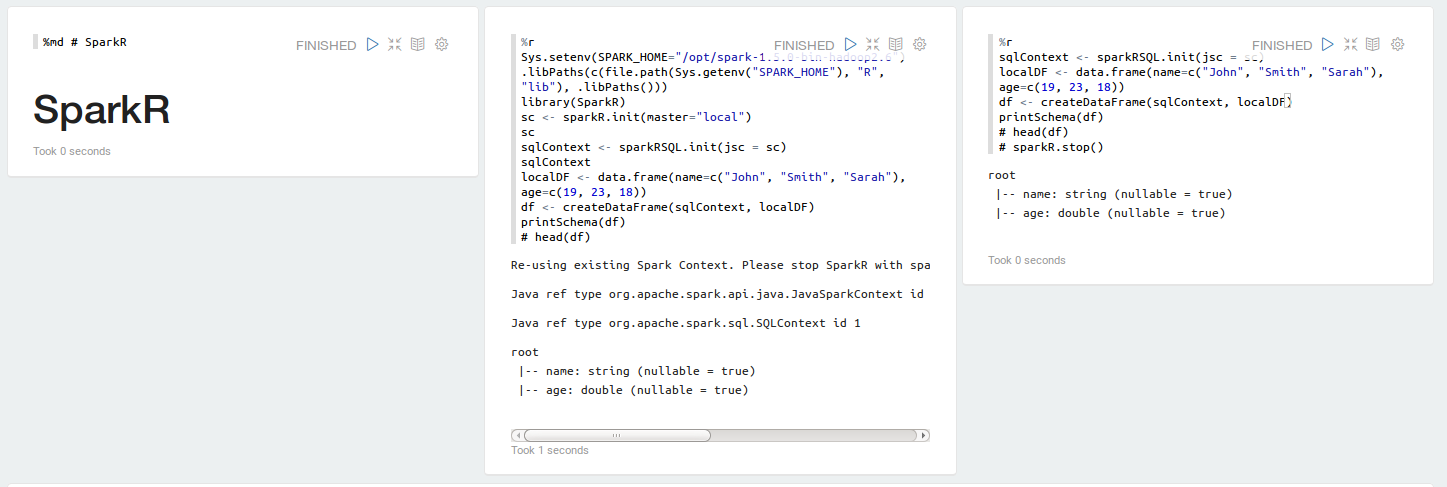
SparkR
用Docker镜像部署
为了您的方便, Datalayer 为Apache Zeppelin 提供了一个最新的 Docker镜像。你可以通过执行下面的命令来获取镜像
docker pull datalayer/zeppelin-rscala Run the Zeppelin notebook with: docker run -it -p 2222:22 -p 8080:8080 -p 4040:4040 datalayer/zeppelin-rscala 现在,你可以去 http://localhost:8080 测试这个R教程笔记了。
展望
作为后续这篇文章中,我们将看到在 Zeppelin 中如何使用 Apache Spark(尤其是SparkR)。
更新
此小节由于原文有可能变动,故不作翻译,望读者原谅,可以直接访问原文查看最新的更新情况。
【原文地址】 http://blog.sparkiq-labs.com/2015/11/16/interactive-data-science-with-r-in-apache-zeppelin-notebook/
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

