“树”不倒,人不散—数据结构的核心
终于有机会重新回头学习一下一直困扰自身多年的数据结构了,赶脚棒棒哒。一直以来,对数据结构的掌握基本局限于线性表,稍微对树有一丢丢了解,而对于图那基本上就是不懂(不可否认,很多的考试中回避了图也是原因之一),而查找和排序只能算是了解点皮毛,简单的面试能应付的水平。关于数据结构方面的教材和视频有不少,首推严蔚敏老教授的书和视频,尤其是视频,记载的是其在清华大学的授课过程,全程通过不同的教具来演示不同的示例,非常直观。自身由于懒惰,一直也没坚持的把其看完,于是选择了相对简单的学习方法,就是选择了程杰老师的《大话数据结构》一书,该书诙谐幽默,让人的挫败感下降了很多,老话说的好,"兴趣是一切学习的老师",别小看任何入门书,它往往是决定你坚持你努力的初衷。随着年龄的增长,会发现一个新的开始是越来越难,推荐一篇园内博文《学习新东西的唯一方法》 http://kb.cnblogs.com/page/536332/ 。
言归正传,本文主要介绍数据结构中的树,可以说树是数据结构最为承上启下的部分,其可以转化为线性表(通过 二叉树的线索化 ),也是学习图的基础,此外在实际中,数据库索引使用的 B+树 数据结构也是经典中的经典,不过这部分将放到之后的查找主题再介绍。

树的定义:是n个结点的有限集,在任何非空树中,有且仅有一个 根结点 ,其余结点可以分为m个互不相交的有限集,其中的内一个集合又是一棵树,并称为根的 子树 。一种简单的描述为,树是由一个根节点和若干子树构成,树中结点具有相同数据类型和层次关系,是一种类似链表的递归式结构。
树中结点的定义:树的结点包含一个数据元素及若干指向其子树的分支,结点拥有的子树数称为结点的 度 (Degree)。度为0的结点称为叶子结点,大于0的为分支结点,树的度是树内各结点度的最大值。结点的子树称为该节点的 孩子 ,相应的该节点称为孩子的 双亲 (Parent)。同一个双亲的孩子之间互称兄弟(Sibling),结点的祖先是从根到该节点所经分支上的所有节点。
此外,森林是m棵互不相交的树的集合,对于任意一个结点来说,其子树的集合即为森林。
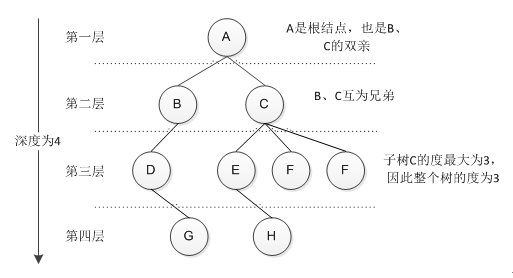
图 1树的基本概念
了解了树的基本概念,接下来学习树的存储结构,常见的包括 双亲表示法、孩子表示法和孩子兄弟表示法 。存储结构的设计是一个非常灵活的过程,一个存储结构设计的是否合适,取决于基于该存储结构的运算是否合适、是否方便、时间复杂度好不好。不过一般来说,一个树结点都具有 数据域 和 指针域 ,之后将分别介绍之前提及的三种表示法。
双亲表示法,相对比较简单,之后的例子为了方便兄弟的查找还添加了右孩子指针。
1 public class Tree1 2 { 3 public TreeNode[] NodeList { get; set; } 4 public int NodeCount { get; set; } 5 public int RootIndex { get; set; } 6 7 private class TreeNode 8 { 9 public object Data { get; set; } 10 public TreeNode Parent { get; set; } 11 public TreeNode RightSibling { get; set; } 12 } 13 } View Code 孩子表示法,由于每个结点可以有多个孩子,因此可以使用多重链表的表示法,在结点中,使用多个指针,每个指向一个孩子。此时有两种解决方案来构建器存储结构,一种是指针的个数就是树的度,缺点是由于每个结点的度和树的度可能差异很大,会造成大量的空间浪费;另一种是添加一个 度域 ,然后根据结点的度来构建指针域,其缺点是每个结点的结构不同,造运算性能上的下降。那有没有更好的方法,即保证结点结构相同并且避免空指针带来的空间浪费。必须是有的嘛,那就是将每个结点的孩子结点排列起来,以单链表作存储结构,n个节点构建n个孩子链表,叶子结点只有头指针。然后将n个头指针组成一个线性表,采用顺序结构存放在一位数组中。因此需要设计 头结点 和 链表的孩子结点 两种结构,整体方案如下所示。
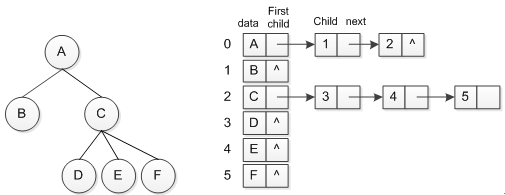
图 2树的孩子表示法
1 public class Tree2 2 { 3 public TreeNode[] NodeList { get; set; } 4 public int NodeCount { get; set; } 5 public int RootIndex { get; set; } 6 7 public class TreeNode 8 { 9 public object Data { get; set; } 10 public TreeNode FirstChild { get; set; } 11 } 12 13 public class LinkedNode 14 { 15 public int CurIndex { get; set; } 16 public TreeNode Next { get; set; } 17 } 18 } View Code 孩子双亲表示法,通过对之前树进行观察,不难发现,一个节点的第一个孩子如果存在就是唯一的,有兄弟也是如此,因而该表示法由数据域、firstchild指针和rightSibling指针组成,由于和之前类似,省略代码,这里的重点是,通过这种表示法,你会发现该表示法其实就是将该树转化为了一个特殊的树 (二叉树,树结构中的核心) ,一个值域,两个指向左右孩子的指针域,在下一节中将进行详细介绍。

- 二叉树
二叉树的定义:二叉树(Binary Tree)是一个特殊的树,由一个根结点和两个互不相交的、分别被称为左子树和右子树的二叉树组成。仍然是一个递归的概念,在与树有关的结构中,有很多往往最后都是通过转化为二叉树,再借助二叉树相关算法,达到化繁为简的效果。为了更好的学习二叉树,之后将介绍几种特殊的树。
斜树:所有的结点只有左或右子树的二叉树。
满二叉树:所有分支结点都存在左子树和右子树,且所有叶子都在同一层上的二叉树。
完全二叉树:最重要的一种特殊二叉树,理解起来也有一定难度。定义是,对一颗具有n个结点的二叉树按层序编号,如果编号为i的结点与相同深度的满二叉树中编号为i的结点在二叉树上的位置完全相同,则称其为完全二叉树,相关的图例如下。
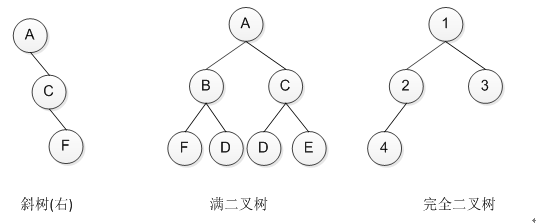
图 3特殊的二叉树
可以发现完全二叉树特点:叶子结点只能出现在最下两层;最下层叶子一定集中在左侧连续位置;倒数第二层叶子结点一定在右侧连续位置;如果结点度为1,也该结点只有左孩子;同样结点数的二叉树,完全二叉树深度最小。
二叉树的性质
1.在二叉树的第i层上至多有2 i-1 个结点。
2.深度为k的二叉树至多有2 i -1个结点。
3.对任意一颗二叉树,如果其终端结点数为n 0 ,度为2的节点数为n 2 ,则 n 0 =n 2 +1 。终端结点也就是叶子结点,除此之外就是度为1或2的结点数了,有结点总数 n=n 0 +n 1 +n 2 (式1)。通过连接线的角度来看,由于根结点只有分支出去,没有分支进入,因此连接线数为m = n-1;再从度的角度出发,有连接数m = n 1 +2n 2 ,因而推导出 n-1= n 1 +2n 2 (式2),联立式1、2得 n 0 =n 2 +1 。
4.具有n个结点的完全二叉树的深度为 ⌊ log 2 n + 1 ⌋ ,符号为向下取整。
5.如果对一个n个结点完全二叉树按层序编号,对任意结点i有:如果i=1,则结点i是二叉树的根,如果i>1,则其双亲是结点 ⌊ i/2 ⌋ ;如果 2i>n ,则结点 i 无左孩子,否则其左孩子为结点 2i ;如果 2i+1>n ,则结点 i 无右孩子,否则其右孩子为 2i+1 。
Tip:
Word快捷操作, 指数——按组合键"Ctrl+Shift+ ="上标,重复操作则恢复常规输入;下标—— 按组合键"Ctrl+ ="下标,重复操作则恢复常规输入。
二叉树的存储结构:包括顺序存储和二叉链表存储两种方式。对于任意的二叉树,我们把它模拟成一个对应的完全二叉树,其按照层序编号,可以很方便的存放在一维数组中,请见以下示例。
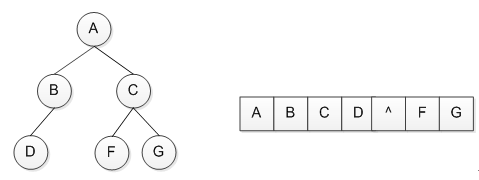
图 4二叉树的顺序存储结构
其中^表示不存在的结点,非常的方便的就将一个树的存储简化为了线性表的存储。顺序存储的缺点是,如果该二叉树是一个右斜树,那么会造成存储空间很大的浪费,此时需要考虑使用二叉链表的存储结构。这种结构理解起来很简单,即结点包含一个数据域和左右孩子两个指针域。
遍历二叉树:二叉树的遍历(traveling binary tree)的定义为指从根结点出发,按照 某种次序 依次访问二叉树中所有的结点,且每个结点被有且仅有一次访问。这个定义的重点是次序,其引申出二叉树遍历的4种方式:前序遍历、中序遍历、后序遍历和层序遍历,这儿的前中后均表示访问父结点的次序,示例图如下所示。

图 5二叉树的遍历方法
经过观察,无论是那种遍历方式,都将树这个复杂的逻辑结构转化为了简单的线性结构,称为了计算机真正可以处理的数据结构。接下来更进一步,通过代码来描述遍历方法,由于几种方式形式相近,这儿就选取中序遍历为例。
1 public class BinaryTree 2 { 3 public TreeNode Root { get; set; } 4 public void MiddleOrderTravel() { TreeManager.MiddleOrderTravel(Root); } 5 } 6 7 public class TreeNode 8 { 9 public object data { get; set; } 10 public TreeNode LeftChild { get; set; } 11 public TreeNode RightChild { get; set; } 12 } 13 14 public class TreeManager 15 { 16 public static void MiddleOrderTravel(TreeNode tree) 17 { 18 if (null == tree) return; 19 MiddleOrderTravel(tree.LeftChild); 20 Console.WriteLine(tree.data); 21 MiddleOrderTravel(tree.RightChild); 22 } 23 } View Code 接下里介绍一个很常见的数据结构考题,用于熟悉二叉树遍历的相关概念。一颗二叉树的前序遍历为ABDCFG,中序遍历为DBAFCG,那么这颗树后续遍历的结果是什么?其结构是怎么样的?分析过程如下所示。
通过前序遍历的ABDCFG,可以该树的根结点为A;再通过中序遍历可知A的左子树为DB,右子树为FCG;分析左子树DB,从前序遍历ABD可以看出B是该子树的根,通过中序遍历DBA可知,D为B的左孩子;对于右子树FCG,通过前序遍历ABDC可知,C为该子树的根,再通过中序遍历FCG可知,F为左子树,G为右子树;即为之前图5中的二叉树,后续遍历为DBFGCA。
此外,需要知道的是,已知前序遍历和中序遍历、后序遍历和中序遍历可以唯一确认一个二叉树,而前序遍历和后序遍历不能。例如前序遍历为ABC,后序遍历为CBA,该树的中序遍历可以为BAC,也可以是CBA等。

- 线索二叉树
之前介绍通过二叉链表的方式来存储二叉树,可以比较好的利用空间,但仍然有很多的空指针域存在(对于n个结点的二叉树,其指针域数量为2n,分支数为n-1,其空指针域有2n – (n-1) = n + 1个),造成空间的浪费,那么有木有什么好的办法将其利用起来呢?
那么就是空指针域记录结点的前驱和后继(和线性表一样),也称这些指针为线索,加上线索的二叉链表称为线索链表,相应的二叉树为线索二叉树(Threaded Binary Tree),以下通过以中序遍历为例,构建一个线索二叉树。
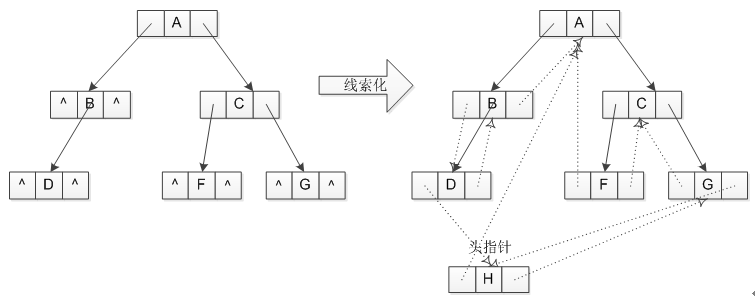
图 6二叉树的线索化
上图比较简陋,望见谅。简单来说,就是将结点空闲的左孩子指针记录其前驱,右孩子指针记录其后继,添加一个头结点指针方便遍历。此外,需要为结点增加左、右两个标识域,用于记录其指针是指向的其孩子还是其前驱/后继,线索二叉树的结构和创建代码如下所示。
1 public class ThreadedBinaryTreeNode 2 { 3 public ThreadedBinaryTreeNode Root { get; set; } 4 public void MiddleOrderTravel() { ThreadedBinaryManager.InThreading(Root); } 5 } 6 7 public class ThreadedBinaryTreeNode 8 { 9 public object data { get; set; } 10 public ThreadedBinaryTreeNode LeftChild { get; set; } 11 public ThreadedBinaryTreeNode RightChild { get; set; } 12 public TagType LeftTag { get; set; } 13 public TagType RightTag { get; set; } 14 } 15 16 public enum TagType : short 17 { 18 Child = 0, 19 Thread = 1 20 } 21 22 public class ThreadedBinaryManager 23 { 24 //用于记录前驱结点 25 public static ThreadedBinaryTreeNode PreNode { get; set; } 26 //中序遍历场景 27 public static void InThreading(ThreadedBinaryTreeNode tree) 28 { 29 if (null == tree) return; 30 InThreading(tree.LeftChild); 31 if (null == tree.LeftChild) 32 { 33 tree.LeftTag = TagType.Thread; //前驱线索 34 tree.LeftChild = PreNode; //指向前驱 35 } 36 if (null == tree.RightChild) 37 { 38 tree.RightTag = TagType.Thread; //后继线索 39 tree.RightChild = tree; //指向后继,即当前结点p 40 } 41 PreNode = tree; 42 43 InThreading(tree.RightChild); 44 } 45 } View Code -
树、森林与二叉树的转换
这部分内容有一些繁杂,需要耐心理解,其主要意图还是通过将树、森林转化为二叉树来简化问题,包括:树转化为二叉树,森林转化为二叉树,二叉树转化为树,二叉树转换为森林和树与森林的遍历,将重点介绍 树转化为二叉树 ,之后的几种转化和前者有相似之处,只做简要介绍。
树转化为二叉树,包含3个步骤: 加线 ,在所有兄弟结点之间加一条连线; 去线 ,对树中每个结点,只保留它与第一个孩子结点的连线,三处它与其他孩子结点之间的连线; 层次调整 ,以树的根结点为轴心,将整棵树顺时针旋转一定角度,使其层次分明。相关示例如下所示。
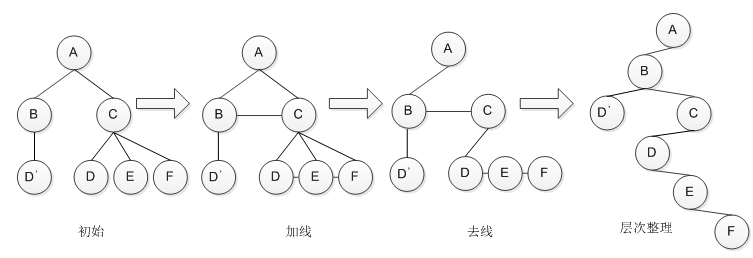
图 7树转化为二叉树
这儿需要提及的一点是,转换后的二叉树的左子树为其第一个孩子,右子树为其兄弟,虽然以上的转化结果看起来怪怪的,但确实是这样的结果。
森林转化为二叉树
森林由若干树组成,可以认为其中的树互为兄弟,先分别按照 树转化为二叉树 的方式转化,然后按序将后一棵二叉树添加为前一棵树的右孩子。
二叉树转化为树
其是树转化为二叉树的逆过程,步骤为:加线,若某结点的左孩子存在,则将结点的右孩子、右孩子的右孩子…于该结点连线;去线,去除原二叉树中所有结点与右孩子的连线;层次调整,使得之层次分明。
二叉树转化为森林:树的根节点有右孩子就是森林,否则就是二叉树。转化步骤为:从根结点开始,若右孩子存在,则把右孩子结点的连线删除,再递归的进行此步骤;将分离的二叉树转化为树。
这部分,最后补充 树与森林的遍历 ,其均支持先根遍历和后根遍历两种方式,过程和之前介绍的二叉树遍历相似。需要注意的是,树和森林的前序遍历和二叉树的前序遍历结果一致,森林的后续遍历和二叉树的中序遍历的结果相同。这说明当使用二叉链表作为树的存储结构时,树和森林的遍历可以转化为二叉树的相关遍历,将复杂问题简单化。

-
赫夫曼树及其应用
提到赫夫曼树,不得不提赫夫曼编码,它是一种基本的压缩编码方式,基于赫夫曼树这一数据结构。在介绍其定义之前,需要了解一个路径长度的定义:从树中一个结点到另一个结点的分支构成两个结点间的路径,路径上的分支数目叫路径长度。如果考虑路径的权重,则结点的带权路径长度为该结点到树根之间的路径长度与结点上权的乘积,整棵树的带权路径长度为所有叶子结点的带权路径长度之和。

图 8带权路径长度
通过上图可以,看到树B比树A带权路径短,那么还有更短的么?在这引入赫夫曼树的概念, 带权路径长度WPL最小的二叉树即为赫夫曼树 ,其构建过程包括如下4个步骤,具体过程请见图9。
1.根据给定的n个权值构建对应的n个二叉树集合F(只包含根结点,也是叶子结点)。
2.在F中选取 两棵权值最小的树作为左右子树构成一棵新的二叉树 ,且将该新树的根结点的权值设为左右子树之和。
3.在F集合中删除被组合的两棵树,新增组合后的新树。
4.重复2、3步骤,直到F集合只包含一棵树为止,此时,该树即为赫夫曼树。

图 9构建赫夫曼树
在学习了赫夫曼树之后,接着来学习 赫夫曼编码 。在1950年左右,那时的通信主要是通过电报进行,因而对优化数据传输的编码方式,节省信道资源非常重视。先举一个示例,例如用户甲想发送字符串ABBCCCD给用户乙,常见的,将其按照unicode编码发送,这将占用14个字节,56个Bit位,非常的浪费。最简单的可以使用2个bit位表示一个字母,那么结果是14bit,那么应用哈夫曼编码呢?
其编码结果为用100表示A,用11表示B、用0表示C、用101表示D,大小为13bit(这儿例子为了简化,数据太小,可能不能很好的显示其优势)。此外,可以发现赫夫曼编码的每一个码值均不为其他码值的前缀,保证了解码的正确性。
参考资料:
-
程杰 . 大话数据结构 [M]. 北京 : 清华大学出版社 , 2011.
-
严蔚敏 , 吴伟民 . 数据结构( C 语言版) [M]. 北京 : 清华大学出版社 , 2004.
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

