MyCAT ER分片的验证
在这里,构造了两张表,熟悉Oracle的童鞋都知道,dept(部门表)和emp(员工表),其中dept中的deptno是emp表中dept_no的外键。
两表的建表语句如下:
create table dept(deptno int,dname varchar(10),datanode varchar(10));
create table emp(empno int,dept_no int,datanode varchar(10));
注意:在这里,最后一列都是datanode,通过插入database()函数可以很直观的获取插入的节点名,从而验证分片的效果。
分别测试以下两种情况:
1. 父表按照主键ID分片,子表的分片字段与主表ID关联,配置为ER分片2. 父表的分片字段为其他字段,子表的分片字段与主表ID关联,配置为ER分片
首先测试第一种情况,在这里,dept表作为父表,主键是deptno,empno为子表,关联字段为dept_no,分片字段为deptno。
schema.xml中的配置如下:
<table name="dept" primaryKey="deptno" dataNode="dn1,dn2,dn3" rule="sharding-by-intfile"> <childTable name="emp" primaryKey="empno" joinKey="dept_no" parentKey="deptno"> </childTable> </table>
rule.xml中的配置如下:
<tableRule name="sharding-by-intfile"> <rule> <columns>deptno</columns> <algorithm>hash-int</algorithm> </rule> </tableRule>
修改很简单,就是将原来的id修改为deptno,代表分片的字段
partition-hash-int.txt的值修改为:
10=0
20=1
验证如下:
插入父表的值,
datanode为db1,与partition-hash-int.txt中的配置相符
mysql> insert into dept(deptno,dname,datanode) values(10,'ACCOUNTING',database()); Query OK, 1 row affected (0.05 sec) mysql> select * from dept; +--------+------------+----------+ | deptno | dname | datanode | +--------+------------+----------+ | 10 | ACCOUNTING | db1 | +--------+------------+----------+ 1 row in set (0.12 sec)
日志输出信息如下:

接下来插入子表的值
mysql> insert into emp(empno,dept_no,datanode) values(7788,10,database()); Query OK, 1 row affected (0.01 sec)
日志输出信息如下:

关键点在于“using parent partion rule directly”。意思是直接使用父的分片规则。如果表本身并没有指定外键约束。
则即便父并没有相应的主键值,子表依旧可以插入,只要分片规则中有所定义。
如下所示:
mysql> select * from emp; +-------+---------+----------+ | empno | dept_no | datanode | +-------+---------+----------+ | 7788 | 10 | db1 | +-------+---------+----------+ 1 row in set (0.52 sec) mysql> select * from dept; +--------+------------+----------+ | deptno | dname | datanode | +--------+------------+----------+ | 10 | ACCOUNTING | db1 | +--------+------------+----------+ 1 row in set (0.13 sec) mysql> insert into emp(empno,dept_no,datanode) values(1234,20,database()); Query OK, 1 row affected (0.09 sec)
尽管dept中没有deptno为20的行。
但emp还是能插入dept_no为20的值
日志的输出信息如下:

所以,对于第一种情况,即父表按照主键分片,字表的分片字段与主表关联,结论就是,子表进行insert操作时,并不会检查父表中是否有相关的主键(对于子表的外键),而是直接根据分片规则进行判断。
如果分片规则中没有定义,则会报如下错误:
mysql> insert into emp(empno,dept_no,datanode) values(1234,30,database()); ERROR 1064 (HY000): can't find datanode for sharding column:DEPTNO val:30
2. 父表的分片字段为其他字段,子表的分片字段与主表ID关联,配置为ER分片
在这里,打算用dname作为分片字段,这样的话,只需要修改route.xml和partition-hash-int.txt了。
首先,修改rule.xml
<tableRule name="sharding-by-intfile"> <rule> <columns>dname</columns> <algorithm>hash-int</algorithm> </rule> </tableRule>
<function name="hash-int" class="org.opencloudb.route.function.PartitionByFileMap"> <property name="mapFile">partition-hash-int.txt</property> <property name="type">1</property> </function>
因dname是字符类型,故将type设置为1。
接着,修改算法配置文件的值
[root@mysql-server1 conf]# cat partition-hash-int.txt accounting,research=0 sales=1 operations=2
登录mycat管理端口,重新加载配置文件
[root@mysql-server1 conf]# mysql -h192.168.244.145 -utest -ptest -P9066
mysql> reload @@config; Query OK, 1 row affected (0.14 sec) Reload config success
现在进行测试:
mysql> insert into dept(deptno,dname,datanode) values(10,'accounting',database()); Query OK, 1 row affected (0.14 sec) mysql> insert into emp(empno,dept_no,datanode) values(1234,10,database()); Query OK, 1 row affected (0.29 sec)
日志的输出信息如下:
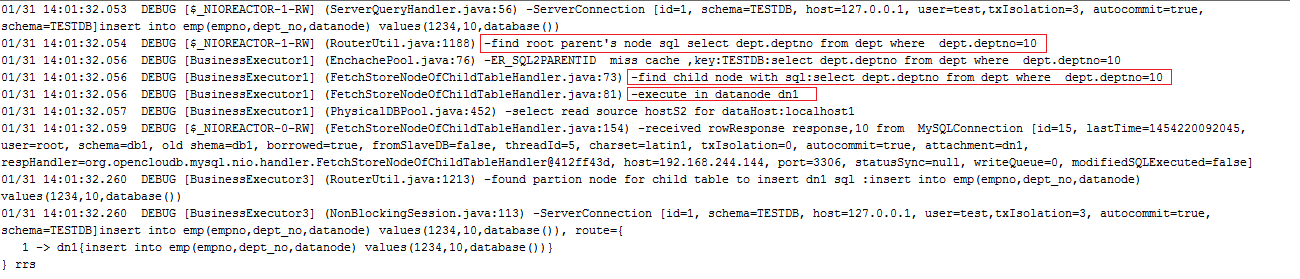
插入第二个分区中的值
mysql> insert into dept(deptno,dname,datanode) values(20,'sales',database()); Query OK, 1 row affected (0.01 sec) mysql> insert into emp(empno,dept_no,datanode) values(1234,20,database()); Query OK, 1 row affected (0.41 sec)
日志的输出信息如下:

这次是在两个分区查找子表的分区节点
插入第三个分区中的值
mysql> insert into dept(deptno,dname,datanode) values(30,'operations',database()); Query OK, 1 row affected (0.00 sec) mysql> insert into emp(empno,dept_no,datanode) values(4567,30,database()); Query OK, 1 row affected (0.62 sec)
日志的输出信息如下:
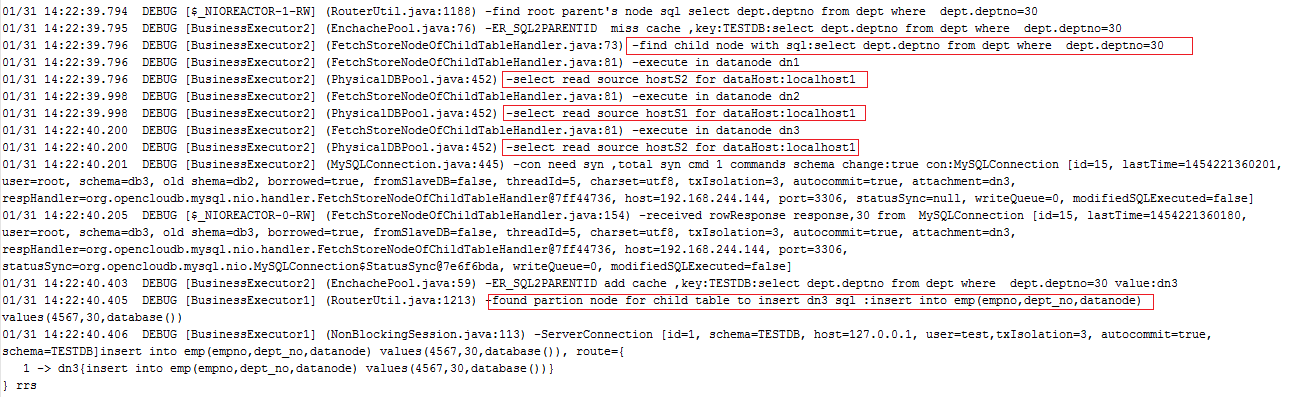
在三个分区中查找子表的分区节点
总结:在父表的分片字段为其他字段,子表的分片字段与主表ID关联这种情况下,子表的分区节点是顺序查找的,在该例中,依次从dn1,dn2和dn3中查找,如果dn1中存在,就直接插入到dn1中,反之,则继续查找dn2节点,如果仍不存在,则继续在dn3节点中查找。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

