服务器进程异常的原因分析(第二篇)
最近看到一个报警,是显示某一个oracle的备库进程数达到了2000多个。
ZABBIX-监控系统:
但是问题也不总是一个模子里刻出来的,问题的原因也是千变万化。
对于这个问题,也是带着一丝的侥幸,首先登陆到服务器端。发现了下面的服务器情况。
top - 22:44:23 up 829 days, 1:35, 3 users, load average: 0.00, 0.03, 0.00
Tasks: 2075 total, 1 running, 1889 sleeping, 0 stopped, 185 zombie
Cpu(s): 0.1% us, 0.1% sy, 0.0% ni, 99.1% id, 0.7% wa, 0.0% hi, 0.0% si
Mem: 16425208k total, 16371888k used, 53320k free, 389780k buffers
Swap: 8385920k total, 449736k used, 7936184k free, 12533064k cached
目前的服务器进程有2000多个,而且io等待也不高。1889个在sleep,185个僵尸进程,所以还是有什么特别的问题。
大概翻了几页进程信息,就发现CROND和一个sh运行脚本的进程有很多。
# ps -ef|grep -i CROND|wc -l
449
# ps -ef|grep sh |wc -l
723
所以通过这些也能够大概看出来,应该是一个crontab的job相关的问题。
看一看磁盘的使用情况,df -h看看发现会卡住没有反应,那么问题似乎就是这儿了。
怎么知道df -h的时候命令卡在哪里呢? 可以简单使用strace测试一下。
#strace df -h
statfs("/tmp", {f_type=0x1021994, f_bsize=4096, f_blocks=2053151, f_bfree=1992224, f_bavail=1992224, f_files=2053151, f_ffree=2052612, f_fsid={0, 0}, f_namelen=255, f_frsize=4096}) = 0
write(1, "/dev/shm 7.9G 238M"..., 49/dev/shm 7.9G 238M 7.6G 3% /tmp
) = 49
statfs("/proc/sys/fs/binfmt_misc", {f_type=0x42494e4d, f_bsize=4096, f_blocks=0, f_bfree=0, f_bavail=0, f_files=0, f_ffree=0, f_fsid={0, 0}, f_namelen=255, f_frsize=4096}) = 0
statfs("/var/lib/nfs/rpc_pipefs", {f_type=0x67596969, f_bsize=4096, f_blocks=0, f_bfree=0, f_bavail=0, f_files=0, f_ffree=0, f_fsid={0, 0}, f_namelen=255, f_frsize=4096}) = 0
statfs("/home/oracle/backup_stage", <unfinished ...>
可以发现运行的结果可以看出来,最后是卡在了/home/oracle/backup_stage这一步上了。如果是明眼人可能已经猜出来缘由了。
看一下挂载点的信息:
[@actvnew.cyou.com oracle]# mount
/dev/sda1 on / type ext3 (rw)
。。。
/dev/shm on /tmp type none (rw,bind)
none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw)
sunrpc on /var/lib/nfs/rpc_pipefs type rpc_pipefs (rw)
10.11.148.174:/backup/10.127.xxxx.xxx_xxxx on /home/oracle/backup_stage type nfs (rw,bg,hard,intr,nolock,tcp,rsize=32768,wsize=32768,addr=10.11.148.174)
可以看到这个路径其实是使用了nfs的方式挂载的。
但是查看/etc/fstab的时候,发现已经注释了原来的挂载点信息
$ cat /etc/fstab
。。。
/dev/shm /tmp none rw,bind 0 0
#10.11.148.174:/backup/10.127.xxxx.xxxx_xxxx /home/oracle/backup_stage nfs rw,bg,soft,intr,nolock,tcp,rsize=32768,wsize=32768 0 0
从这个信息可以看似,之前的维护人员似乎意识到了这个挂载点失效了,直接给注释了。
但是实际上呢。查看/etc/mtab发现这个配置还在那里。
$ cat /etc/mtab
/dev/sda1 / ext3 rw 0 0
...
10.11.148.174:/backup/10.127.xxxx.xxx_xxx /home/oracle/backup_stage nfs rw,bg,hard,intr,nolock,tcp,rsize=32768,wsize=32768,addr=10.11.148.174 0 0
所以可以基本明确,这个是由nfs失效导致的一个问题。那么我们直接取消挂载好了。
# umount -f /home/oracle/backup_stage
umount2: Device or resource busy
umount: /home/oracle/backup_stage: device is busy
umount2: Device or resource busy
umount: /home/oracle/backup_stage: device is busy
强制也不行。
#umount -f /home/oracle/backup_stage
umount2: Device or resource busy
umount: /home/oracle/backup_stage: device is busy
而且进一步发现到了/home/oracle目录下,使用ls -l也会直接卡住。当然strace一下,发现还是由于这个/home/oracle/backup_stage导致的问题。
所以可以先初步解决问题,循序渐进,把问题的影响先降下来再除根。
所以清理了部分的进程情况,发现还有相当一部分的进程是由于rman相关的两个脚本导致的。而在这两个脚本中间接使用ll和mkdir -p的操作。
oracle 359 337 0 2015 ? 00:00:00 /bin/bash /home/oracle/dbadmin/scripts/rmanbak_stby.sh
oracle 577 575 0 2015 ? 00:00:00 /bin/sh -c . $HOME/.actvdbprofile;$HOME/dbadmin/scripts/rmanbak_stby.sh
对于NFS挂载点失效的情况下,简直就是灾难。所以简单使用awk命令生成批量的命令来清理
比如删除僵尸进程,可以采用下面的方式
# ps -ef|grep "defunct"|awk '{print "kill -9 " $2}'> kill_defunct.lst
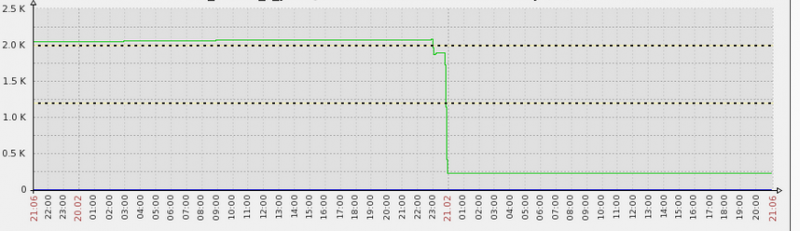
清理之后,进程数马上降了下来。效果还是非常显著的。
然后进一步处理。关键就是使用fuser来清理相关的进程
# umount /home/oracle/backup_stage
umount: /home/oracle/backup_stage: device is busy
# umount -l /home/oracle/backup_stage
# umount -lf /home/oracle/backup_stage
umount: /home/oracle/backup_stage: not mounted
# fuser -k /home/oracle/backup_stage
# umount /home/oracle/backup_stage
umount: /home/oracle/backup_stage: not mounted
再次查看这个问题就基本解决了。
df -h和ls -l都没有问题了,当然后续还需要查看crontab中对于这个路径的引用,还是需要考虑重新制定或者重新建立新的nfs映射。
ZABBIX-监控系统:
------------------------------------
报警内容: Too many OS processes on ora_xxx@10.127.13.123
------------------------------------
报警级别: PROBLEM
------------------------------------
监控项目: Number of processes:2003
------------------------------------
报警时间:2015.12.13-00:10:12
但是问题也不总是一个模子里刻出来的,问题的原因也是千变万化。
对于这个问题,也是带着一丝的侥幸,首先登陆到服务器端。发现了下面的服务器情况。
top - 22:44:23 up 829 days, 1:35, 3 users, load average: 0.00, 0.03, 0.00
Tasks: 2075 total, 1 running, 1889 sleeping, 0 stopped, 185 zombie
Cpu(s): 0.1% us, 0.1% sy, 0.0% ni, 99.1% id, 0.7% wa, 0.0% hi, 0.0% si
Mem: 16425208k total, 16371888k used, 53320k free, 389780k buffers
Swap: 8385920k total, 449736k used, 7936184k free, 12533064k cached
目前的服务器进程有2000多个,而且io等待也不高。1889个在sleep,185个僵尸进程,所以还是有什么特别的问题。
大概翻了几页进程信息,就发现CROND和一个sh运行脚本的进程有很多。
# ps -ef|grep -i CROND|wc -l
449
# ps -ef|grep sh |wc -l
723
所以通过这些也能够大概看出来,应该是一个crontab的job相关的问题。
看一看磁盘的使用情况,df -h看看发现会卡住没有反应,那么问题似乎就是这儿了。
怎么知道df -h的时候命令卡在哪里呢? 可以简单使用strace测试一下。
#strace df -h
statfs("/tmp", {f_type=0x1021994, f_bsize=4096, f_blocks=2053151, f_bfree=1992224, f_bavail=1992224, f_files=2053151, f_ffree=2052612, f_fsid={0, 0}, f_namelen=255, f_frsize=4096}) = 0
write(1, "/dev/shm 7.9G 238M"..., 49/dev/shm 7.9G 238M 7.6G 3% /tmp
) = 49
statfs("/proc/sys/fs/binfmt_misc", {f_type=0x42494e4d, f_bsize=4096, f_blocks=0, f_bfree=0, f_bavail=0, f_files=0, f_ffree=0, f_fsid={0, 0}, f_namelen=255, f_frsize=4096}) = 0
statfs("/var/lib/nfs/rpc_pipefs", {f_type=0x67596969, f_bsize=4096, f_blocks=0, f_bfree=0, f_bavail=0, f_files=0, f_ffree=0, f_fsid={0, 0}, f_namelen=255, f_frsize=4096}) = 0
statfs("/home/oracle/backup_stage", <unfinished ...>
可以发现运行的结果可以看出来,最后是卡在了/home/oracle/backup_stage这一步上了。如果是明眼人可能已经猜出来缘由了。
看一下挂载点的信息:
[@actvnew.cyou.com oracle]# mount
/dev/sda1 on / type ext3 (rw)
。。。
/dev/shm on /tmp type none (rw,bind)
none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw)
sunrpc on /var/lib/nfs/rpc_pipefs type rpc_pipefs (rw)
10.11.148.174:/backup/10.127.xxxx.xxx_xxxx on /home/oracle/backup_stage type nfs (rw,bg,hard,intr,nolock,tcp,rsize=32768,wsize=32768,addr=10.11.148.174)
可以看到这个路径其实是使用了nfs的方式挂载的。
但是查看/etc/fstab的时候,发现已经注释了原来的挂载点信息
$ cat /etc/fstab
。。。
/dev/shm /tmp none rw,bind 0 0
#10.11.148.174:/backup/10.127.xxxx.xxxx_xxxx /home/oracle/backup_stage nfs rw,bg,soft,intr,nolock,tcp,rsize=32768,wsize=32768 0 0
从这个信息可以看似,之前的维护人员似乎意识到了这个挂载点失效了,直接给注释了。
但是实际上呢。查看/etc/mtab发现这个配置还在那里。
$ cat /etc/mtab
/dev/sda1 / ext3 rw 0 0
...
10.11.148.174:/backup/10.127.xxxx.xxx_xxx /home/oracle/backup_stage nfs rw,bg,hard,intr,nolock,tcp,rsize=32768,wsize=32768,addr=10.11.148.174 0 0
所以可以基本明确,这个是由nfs失效导致的一个问题。那么我们直接取消挂载好了。
# umount -f /home/oracle/backup_stage
umount2: Device or resource busy
umount: /home/oracle/backup_stage: device is busy
umount2: Device or resource busy
umount: /home/oracle/backup_stage: device is busy
强制也不行。
#umount -f /home/oracle/backup_stage
umount2: Device or resource busy
umount: /home/oracle/backup_stage: device is busy
而且进一步发现到了/home/oracle目录下,使用ls -l也会直接卡住。当然strace一下,发现还是由于这个/home/oracle/backup_stage导致的问题。
所以可以先初步解决问题,循序渐进,把问题的影响先降下来再除根。
所以清理了部分的进程情况,发现还有相当一部分的进程是由于rman相关的两个脚本导致的。而在这两个脚本中间接使用ll和mkdir -p的操作。
oracle 359 337 0 2015 ? 00:00:00 /bin/bash /home/oracle/dbadmin/scripts/rmanbak_stby.sh
oracle 577 575 0 2015 ? 00:00:00 /bin/sh -c . $HOME/.actvdbprofile;$HOME/dbadmin/scripts/rmanbak_stby.sh
对于NFS挂载点失效的情况下,简直就是灾难。所以简单使用awk命令生成批量的命令来清理
比如删除僵尸进程,可以采用下面的方式
# ps -ef|grep "defunct"|awk '{print "kill -9 " $2}'> kill_defunct.lst
清理之后,进程数马上降了下来。效果还是非常显著的。
然后进一步处理。关键就是使用fuser来清理相关的进程
# umount /home/oracle/backup_stage
umount: /home/oracle/backup_stage: device is busy
# umount -l /home/oracle/backup_stage
# umount -lf /home/oracle/backup_stage
umount: /home/oracle/backup_stage: not mounted
# fuser -k /home/oracle/backup_stage
# umount /home/oracle/backup_stage
umount: /home/oracle/backup_stage: not mounted
再次查看这个问题就基本解决了。
df -h和ls -l都没有问题了,当然后续还需要查看crontab中对于这个路径的引用,还是需要考虑重新制定或者重新建立新的nfs映射。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

