数据杂谈(一)
前言
记得几年前,曾经有人预测过未来最流行的三大技术:大数据、高并发、数据挖掘。到现在来看,这三种技术的确也随着这几年互联网的发展变得越发成熟和可靠。掌握这三种技术的人,不管是求职还是创业,都属于香饽饽。一个很深的印象就是当年研究生毕业的时候,专业是数据挖掘、大数据的学生都比较受各种企业的青睐,不管他是不是真的掌握了这些东西。虽然我对大部分高校的相关专业持怀疑态度,但是却也不得不承认,这些专业的确改变了很多东西,也给很多学生镀上了一层金。
自己一直从事的是Java EE中间件、基础架构等方面的研发工作,对数据这一块只是略知皮毛,在前东家的时候我也没有机会接触数据平台。但由于现公司业务的原因,却不得不去触碰这一块,到目前为止也就仅仅半年时间(其间穿插各种协调、管理的杂事)。因此,数据相关的东西对我来说完全是一个新的领域,算是离开了自己的舒适区。不过,逃离舒适区这个想想也挺兴奋的。
数据
什么是数据?
最近有一本很火的书叫《精益数据分析》,其核心的一个观点就是:需要用数据驱动产品和公司的发展,而不能靠直觉或者拍脑袋。可见,数据是多么的重要。在一个产品的生命周期中,会产生很多数据:用户信息、用户行为信息、ugc数据等等。这些数据表现形式可以为文字、图片、日志、视频、音频等等。
从技术角度来讲,数据一般分为结构化数据、半结构化数据和非结构化数据。
- 结构化数据:指的是行数据库可以存储的,数据具有相同的字段,以及相同的存储大小,可以用二维表的逻辑结构来表达实现。
- 半结构化数据:半结构化数据,指的整体上是结构化数据形式,但字段数目不定,数据结构和内容混杂在一起。
- 非结构化数据:不方便用二维表描述的数据,如各种文档、图片、音/视频等。
能用来干什么?
说到数据的作用,不得不提数据分析师这个职位。此职位一般来说倾向的是数学相关专业人士,使用数据来指导产品、运营、市场等工作,是公司中使用数据最多的人。在公司中,市场运营销售这几个部门也都是和数据关系很密切的。市场需要参考数据分析哪一个渠道推广效果更好,运营部门需要根据数据分析什么内容更能提高产品的活跃度,销售部门则需要数据反映公司的收入情况。当然,除了这些,数据挖掘就是另一个很重要的使用数据的方面了,可以使用数据对用户进行行为分析,从而挖掘用户的兴趣,最终达到精准推荐、精准营销的目的。
概括来看,数据的作用有以下两点:
- 数据统计→指导产品、市场、运营、销售工作
- 数据挖掘→个性化推荐→提高产品活跃度→变现
数据库&&数据仓库
有了数据,就需要有存放数据的地方。数据库和数据仓库即存放数据库的两种形式。两者在本质上没有区别,都是为了存储数据。
-
数据库:面向业务设计,一般针对的是在线业务,存储的是在线业务数据。如:Oracle、DB2、MySQL、Sybase、MS SQL Server等。
-
数据仓库:是数据库概念的升级,面向分析,存储的是历史数据。从数据量来说,数据仓库要比数据库更庞大得多。主要用于数据挖掘和数据分析,代表软件为Hive。
ETL: 数据仓库很多时候是需要从其他地方传输数据到数据仓库的,这个过程就是ETL:extract-抽取、transform-转换、load-加载。
数据的生命周期
无论是历史数据还是线上数据,都是有生命周期的。比如,对于一个产品的用户活跃度统计业务,最近半年的数据是热点数据,访问较频繁;而随着时间的推移,慢慢的这些数据不再被频繁关注,变为了一般数据;再随着时间的推移,总有一天这些数据不再会被关注就成为了冷数据。
热点数据→一般数据→冷数据,这就是数据的一个生命周期,对于不同的生命周期,所需要的技术选型也应该不一样。
数据系统
不管是数据统计还是数据挖掘,构建一个数据系统都是做好这些的前提。一般来说,构建一个完善的数据系统有以下几点:
-
数据采集
无论是移动端还是web上,要做好数据采集集最重要的一点就是埋点。也就是要在你需要采集数据的地方做一个标记,向服务端发起一个日志请求。当然,对于服务端能够通过业务逻辑获取的内容,原则上不要打点。比如,统计某一篇新闻的阅读数目、点赞数,这些行为其实在用户打开此新闻、点赞时已经发起了服务端请求,不需要再埋一个点;此外,统计用户数目这种,在用户数据库中就可以计算出来,也不需要埋点。埋点主要针对的是通过产品的业务逻辑无法获取到的一些数据,如一个站点中某一个模块的pv、uv等。
埋点后向服务端发起日志请求,这些请求在用户量规模并不很大的架构设计中直接实时计算数据入库即可,但是在用户请求量很大的情况下,这种设计是有问题的,会增加业务请求的压力,从而影响线上服务,因此好的设计应该是数据请求只形成一条日志(一般通过nginx日志实现)。因此,这里很关键的一点就是如何将这些日志收集起来进行处理。目前常用的技术有flume、Scribe、Chukwa等。其中,flume是目前比较成熟且应用比较广泛的方案。
-
数据队列
数据采集之后需要通过数据队列传输,这里的队列主要起的是缓冲作用以及其他非采集数据源的输入(比如某一业务逻辑产生了一条统计报文,可以直接写入队列中),可以采取本地队列或者分布式队列。目前,比较成熟的队列有kafka、rabbitMQ等。其中,在数据统计领域kafka是应用比较广泛的。
-
数据处理
对于采集到的数据,很多是需要计算才能得到需要的统计结果的。这时候就牵扯到了计算模型。这里分为离线计算和实时计算两种模型。离线计算针对实时来讲,就是非实时的,可以定时调度进行计算的,一般来说是耗时比较长,对结果需求没那么实时的业务场景,适合非线上业务;实时计算则是需要在数据一到达就开始进行计算、处理的,适合对实时性要求高的一些业务场景,比如广告的实时结算等。
-
数据存储
服务端在数据统计中一个关键的功能是对采集到的内容进行存储。对于中小规模的数据,使用mysql等传统数据库即可应对,大一点规模采用分表、分库也能应对。再大一点的那就只能祭出大数据数据库了。此外,数据的存储结构也需要慎重考虑,尤其是在应对多维度查询的时候,不合理的数据结构设计会导致低下的查询效率和冗余的存储空间。
-
数据可视化
数据存储的下一步是要把数据展示出来,也就是数据可视化。通常情况下,导出excel表格是一种形式,此外,web端/移动端甚至pc端也需要展示数据的话,就引出了数据可视化技术,尤其是在大数据量情况下如何更加高效快速地展示数据。
数据采集+数据队列+数据处理+数据存储+数据可视化即组成了一个完整的数据系统。而从本质上来看,数据系统=数据+查询,万变不离其宗。
对于一般规模的产品,数据其实远远没有达到需要使用大数据技术的地步。使用传统的收集数据→定时调度程序计算,存储到mysql中即可解决。如果有大的并发请求,那么使用数据队列做缓冲。当数据规模大到一定规模时,例如mysql数据库在分表分库的情况下,单表数据量还是达到了千万的规模、单机存储依然不够或者单机计算已经慢到无法容忍。应对这种情况,就需要分布式技术出场了。
说到这里,借用《计算广告》一书中所讲,对于数据分为三种:
- 小规模数据:此种数据可以通过采样部分数据即可反映出数据的特征。这时候,根本无需什么大数据技术,单机规模即可妥妥应对这种场景。
- 中等规模数据:小规模数据无法反应数据特征,当数据规模达到一定规模时,再增大特征趋向于平稳,那么此时也无需大数据技术的出场。
- 大规模数据:不能通过采样来反应数据特征,必须全量采集数据才能获取到数据特征。此时,就需要大数据技术来解决。
其中,大规模数据就不是一般架构可以解决的了的了。
大数据
相关技术
大数据是一个很宽泛的概念。当单机无法处理数据时,就有了大数据。而应对各种不同的业务场景,诞生了很多不同的软件。完成一个功能完备的系统需要多个软件的组合。
-
文件/数据存储
传统的文件存储都是单机的,不能横跨不同的机器,一般会使用raid做安全冗余保障。但是还是无法从根本上解决问题。HDFS(Hadoop Distributed FileSystem)则是为了应对这种业务场景产生的,其基本原理来自于google的gfs,让大量的数据可以横跨成千上百万台机器。但是对用户来说,看到的文件和单机没任何区别,已经屏蔽掉了底层细节。
除了文件存储,还有数据的存储,即数据库。传统的mysql等数据库,在存储结构化、小规模数据的时候可以妥妥应对。但当需要存储半结构化或者非结构化数据,或者用分表、分库来解决存储性能、空间问题带来了复杂的管理、join时,就需要一种更好的数据库的出现。大数据领域的Hbase就是为了这种场景产生的,其原理是google的BigTable。当然,hbase底层还是依赖于hdfs,是一个针对半结构化、非结构化、稀疏的数据的数据库。
此外,hbase和hdfs相比起mysql这种毫秒级数据库,其响应速度是很慢的。如果线上业务场景需要使用这些数据,那么这时候就需要更好的数据库的出现。elasticserach就是其中的佼佼者,当然,使用这种基于索引、高效的查询数据库,并不建议存储全量数据(除非你钱有的是)。一般情况下,存储热点数据即可。
-
离线数据处理
大数据的处理是非常关键的一个环节。当单机的处理程序无法在期望的时间内处理完数据时,就需要考虑使用分布式技术了。于是就出现了MapReduce、Tez、Spark这些技术。MapReduce是第一代计算引擎,Tez和Spark是第二代。MapReduce的设计,采用了很简化的计算模型,只有Map和Reduce两个计算过程(中间用Shuffle串联),用这个模型,已经可以处理大数据领域很大一部分问题了。但是,MR模型很简单,但也很笨重,有不少缺点,比如:编程模型非常复杂;计算过程磁盘IO过多。于是催生出了第二代数据处理技术,Tez、Spark这些鉴于MR模型的缺点,引入了内存cache之类新的feature,让Map和Reduce之间的界限更模糊,数据交换更灵活,更少的磁盘读写,以便更方便地描述复杂算法,取得更高的吞吐量。
如上面所说,编写MR的编程复杂度非常高,于是就产生了Hive、Pig,在MR上面又抽象了一层更高级的语法出来,大大简化了MR的编程复杂度。其中以Hive为代表是Sql on xx的一个典型应用。之所以使用sql,一方面是容易编写、容易维护;另一方面SQL可以让没有编程技能的诸如数据分析师都可以不依赖工程师就可以使用数据。但由于一开始的hive还是基于MR之上的,因此,其运算速度还是受到不少人的诟病。于是Hive on Tez / Spark和SparkSQL也出现了。它们都旨在用新一代通用计算引擎Tez或者Spark来跑SQL,这样就避免了基于MR带来的运算瓶颈。
对于程序的离线数据处理,hive一般情况下都能够满足需求。但是对于数据分析师的数据分析需求来说,这速度就真的有点龟速了。因此为了应对数据分析的需求,Impala、Presto、Drill这些交互式sql引擎应运而生。这些系统的唯一目标就是快,能够让用户更快速地处理SQL任务,因此牺牲了通用性稳定性等特性。
一个典型的数据仓库系统可以满足中低速数据处理的需求:底层HDFS,之上是MR、Tez、Spark,再上面则是Hive、Pig;此外,直接跑在HDFS上的Presto、Impala等也是另一种方案。
由于是离线计算,因此是需要一个任务调度工具来定时调度计算过程的。比较流行的一个任务调度工具是azkaban,是一个基于工作流的调度软件,在一定程度上能够满足目前的离线调度需求。
-
实时计算
上面说的都是数据仓库以及离线处理需求,也是低速数据处理需求。对于高速的数据处理,则需要引出实时计算的概念,也叫流式计算。目前,storm是比较成熟和流行的流式计算技术,spark streaming则是另外一种基于批量计算的流式计算技术。所谓流式计算,就是指数据过来的时候立刻进行处理,基本无延迟,但是不够灵活,计算过的数据也不能回放,因此也无法替代上面说的数据仓库和离线计算技术。
-
资源调度
综上的所有东西都在同一个集群上运行,需要达到一个有序工作的状况。因此,需要一个资源调度系统来调度这些工作,MR2.0带来的yarn就是负责此工作的一个框架。目前,docker on yarn,storm on yarn等on yarn技术的出现都得益于此框架,大大提高了大数据集群的资源使用率。此外,mesos也是另一种资源调度框架。
-
协调服务
一个分布式系统能够有条不紊的运行离不开协调服务的功劳。不管是hadoop还是storm、kakfa等,都是需要通过zookeeper进行协调的。zookeeper在分布式服务中扮演的角色就类似其字面意思-动物园管理员,而大数据的各个组件就类似动物园中的动物们。
-
集群监控
集群的稳定性对于一个数据系统是至关重要的。因此,集群监控技术也是需要重点考虑的一点。目前,ganglia是对hadoop进行监控一个较好的工具。除了hadoop之外,ganglia也可以对kafka、zookeeper、storm等集群进行监控。当然,只要支持jmx,任何集群都是可以通过ganglia进行监控的。
-
数据可视化
最近几年,数据可视化是一个很火的概念。尤其是大数据的可视化,考虑到高效、速度以及体验等等问题,并非是个很简单的事情。目前,百度开源的echarts是比较好的一个可视化前端解决方案,在大数据可视化方面支持的也比较好。
一般架构
下图为一个典型的大数据系统架构:
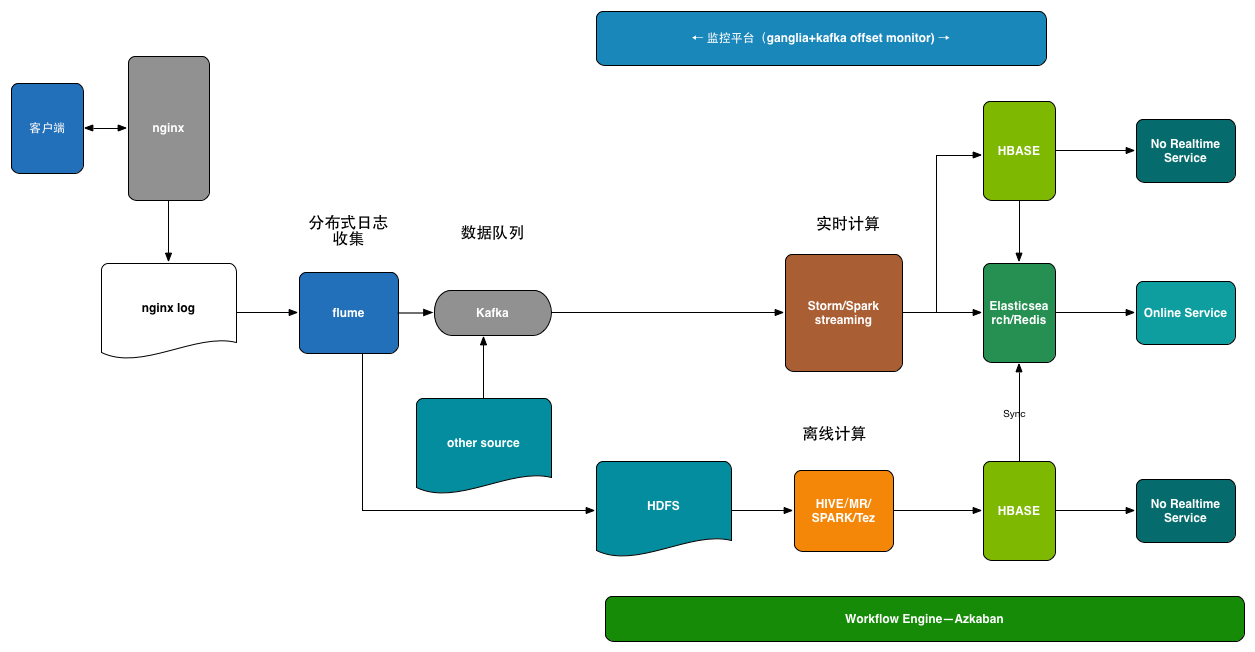
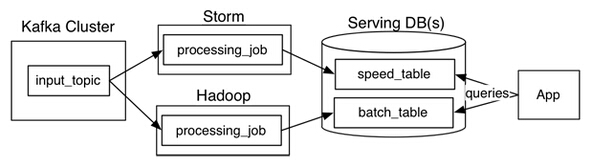
这里还需要提到的是Lambda架构这个概念。Lambda架构是由Storm的作者Nathan Marz提出的一个实时大数据处理框架。目标是设计出一个能满足实时大数据系统关键特性的架构,包括有:高容错、低延时和可扩展等。Lambda架构整合离线计算和实时计算,融合不可变性(Immunability),读写分离和复杂性隔离等一系列架构原则,可集成Hadoop,Kafka,Storm,Spark,Hbase等各类大数据组件。
数据挖掘
此部分见后续文章《数据杂谈(二)》^_^
正文到此结束
- 本文标签: apr 数据 Excel dist 阅读数 Hadoop 广告 Ganglia UI Docker 企业 数据挖掘 站点 数据库 HDFS 系统架构 空间 SQL Server 生命 Nginx Oracle 集群 map 时间 开源 http web 创业 产品 sql 需求 百度 推广 java 互联网 zookeeper Google REST 运营 mysql db HBase 管理 软件 统计 db2 压力 安全 大数据 key src 文章 tab 学生
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

