那些常见的Oracle错误
虽然Oracle数据库的故障千奇百怪,甚至让客户有种防不胜防的感觉,但还是有很多故障是比较常见的,这些问题也是我们Oracle服务部门在客户现场经常遇见,也经常处理的问题。
事实上,针对这些常见问题,Oracle公司不仅提供了诊断和解决问题的思路和方式,甚至针对具体问题,提供了专门的官方处理文档。如果我们能在平日的运行维护工作中,提前预读这些文档,甚至自己编写相应的故障处理手册,一旦这些常见故障真正发生时,我们就不会那么手足无措,即便不一定完全胸有成竹,也至少可以做到一定的心中有数了,就像打仗一定要有作战预案、一定要打有准备之战一样。
本章就将介绍这些常见故障的诊断和处理过程。例如ORA-00600、内存不够、数据库空间不够、snapshot too old、UNDO表空间无法扩展等。
ORA-00600:内部错误
什么是ORA-00600错误?
ORA-00600是常见的一类错误,以下是Oracle 11g中关于该错误的官方描述:
ORA-00600: internal error code, arguments: [string], [string], [string], [string], [string], [string], [string], [string], [string], [string], [string], [string] Cause: This is the generic internal error number for Oracle program exceptions. It indicates that a process has encountered a low-level, unexpected condition. The first argument is the internal message number. This argument and the database version number are critical in identifying the root cause and the potential impact to your system. Action: Visit My Oracle Support to access the ORA-00600 Lookup tool (reference Note 600.1) for more information regarding the specific ORA-00600 error encountered. An Incident has been created for this error in the Automatic Diagnostic Repository (ADR). When logging a service request, use the Incident Packaging Service (IPS) from the Support Workbench or the ADR Command Interpreter (ADRCI) to automatically package the relevant trace information (reference My Oracle Support Note 411.1). The following information should also be gathered to help determine the root cause: - changes leading up to the error - events or unusual circumstances leading up to the error - operations attempted prior to the error - conditions of the operating system and databases at the time of the error Note: The cause of this message may manifest itself as different errors at different times. Be aware of the history of errors that occurred before this internal error.
即ORA-00600是Oracle软件当遇到内部不一致或其它异常情况时发出的内部错误,通常而言该错误与Oracle Bug相关,但也不尽然,也可能与操作系统、资源缺乏、硬件故障等相关。
ORA-00600错误信息通常包括一组以中括号形式的参数信息,例如:
ORA-00600: internal error code, arguments: [string], [string], [string], [string], [string], [string], [string], [string], [string], [string], [string], [string]
这些参数是一组内部数字或字符串,其中第一个参数非常重要,表示错误信息是在哪个代码中发生的,这是诊断ORA-00600错误的关键信息。其它参数则提供了进一步的诊断信息,例如内部变量值等。另外,数据库版本信息对问题诊断也非常关键。
ORA-00600错误的诊断方法
ORA-00600错误实际包含的内容非常广泛,但诊断方法却有一定规律。
ORA-OO600错误发生时,Oracle通常会在alert.log文件中进行记录。因此,ORA-OO600错误诊断的第一个动作就是去查看alert.log文件。同时,alert.log文件中会显示与该错误相关的更详细的trace文件信息。
如果是11g之前版本,假设错误是因为用户进程所导致,trace文件将位于USER_DUMP_DEST目录。假设错误是因为后台进程(如PMON、SMON)所导致,trace文件将位于BACKGROUND_DUMP_DEST目录。如果是11g之后版本,trace文件将位于DIAGNOSTIC_DEST参数所定义的目录。
假设trace文件结束处出现“MAX DUMP FILE SIZE EXCEEDED”,则说明因为MAX_DUMP_FILE_SIZE参数设置过小或者没有设置成“unlimited”,导致trace文件被截断了。这样可能导致非常重要的诊断信息没有记录下来,因此应调整MAX_DUMP_FILE_SIZE参数,确保诊断信息的完整。
为提高ORA-00600/ORA-7445/ORA-00700等内部错误的诊断效率,Oracle公司在metalink中提供了这类错误的诊断工具,可通过ID 153788.1访问该工具,以下就是其界面:
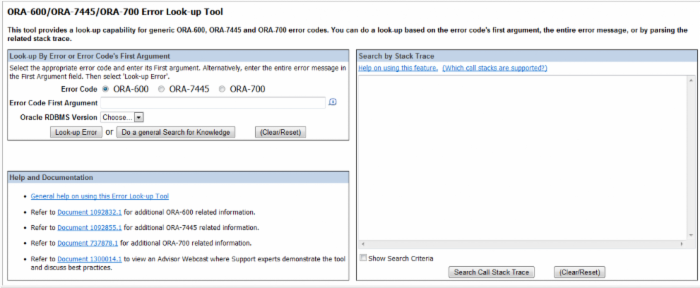
即输入ORA-00600的第一个参数以及数据库版本号,再点击“Loop-up Error”,就可有效检索出与该类错误相关的诊断信息。如果未检索出有效信息,则可以点击“Do a general Search for Knowledge”进行更广泛的搜索。
同时,可在上述页面的“Search by Stack Trace”区域中输入Trace文件中Call Stack相关信息进行更准确的检索。具体办法是将Trace文件中以“—- Call Stack Trace —-”开头到“Argument/Register Dump”结束的内容,或者将“—- Call Stack Trace —-”开头的前15-20行内容复制粘贴到“Search by Stack Trace”区域中,然后点击“Search Call Stack Trace”按钮进行检索。首发于askmaclean.com
ORA-00600毕竟是Oracle内部错误信息,而且很可能是Oracle Bug。因此,如果可能,尽量还是通过创建SR求助Oracle Support,得到官方的权威分析和解决方式建议。为此,建议在SR至少提供如下信息给Oracle Support:
ORA-00600错误诊断举例
假设我们遇见了“ORA-00600 [729] [space leak]”错误,我们在600/7445/700诊断工具中输入第一个参数“729”,以及数据库版本号,我们将快速搜索出相应的文章:ORA-600 [729] “UGA Space Leak” [ID 31056.1]。该文章对该错误的描述如下:
该错误表示UGA内存泄露了,该错误是由于Oracle内部内存管理程序导致,但不会导致数据损坏,也只是在logoff操作时才发生。总之,影响较小,内存泄露也比较少,基本可以忽略。
通过设置如下参数:
event = “10262 trace name context forever, level 4000”
并重新启动数据库。该参数将使得低于4000字节的内存泄露信息被忽略掉,不再写入alert.log文件。建议不要将level设置为1,这样将关闭内存泄露检查功能。
ORA-04030:PGA内存不够
什么是ORA-04030错误?
ORA-04030错误表示Oracle后台服务进程(Server Process)从操作系统分配不到内存了,这部分内存主要是PGA内存。在专用连接模式(Dedicated)下,Oracle PGA内存包括如下部件:
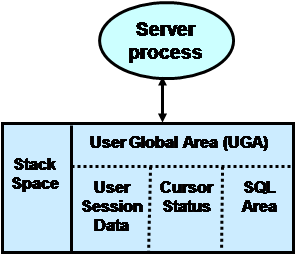
其中SQL Area包括Sort Area、Hash join Area、Bitmap merge Area、Bitmap Create Area等。
而在多线程连接模式(Multithread)或共享服务器连接模式(Shared Server)下,UGA将从SGA中进行分配,因此UGA不会导致ORA-04030错误。
ORA-04030错误的诊断
ORA-04030错误原因是多方面的,例如:应用本身内存申请过多、操作系统内存耗尽、操作系统内存分配限制。以下以UNIX操作系统为环境进行深入探讨:
通过操作系统提供的工具:top、vmstat等,可以监控当前内存使用情况,例如,以下是在Linux平台top工具的显示结果:
top - 10:17:09 up 1:27, 4 users, load average: 0.07, 0.12, 0.05 Tasks: 110 total, 4 running, 105 sleeping, 0 stopped, 1 zombie Cpu(s): 0.3% user, 1.6% system, 0.0% nice, 98.0% idle Mem: 1033012k total, 452520k used, 580492k free, 59440k buffers Swap: 1052248k total, 0k used, 1052248k free, 169192k cached .....
可见该系统还有580492k空闲内存。
如果有空闲内存,则可能是操作系统内存分配有限制了。通过操作系统的limit或ulimit命令,将显示操作系统内存分配限制。以下是Linux平台的执行情况:
aroelant@aroelant-be:~> ulimit -a core file size (blocks, -c) 0 data seg size (kbytes, -d) unlimited file size (blocks, -f) unlimited max locked memory (kbytes, -l) unlimited max memory size (kbytes, -m) unlimited open files (-n) 1024 pipe size (512 bytes, -p) 8 stack size (kbytes, -s) unlimited cpu time (seconds, -t) unlimited max user processes (-u) 7168 virtual memory (kbytes, -v) unlimited
请注意,有些操作系统的unlimited设置并非是无限制的,而实际上是由于历史原因而导致的2G限制。因此,如果内存不够,最好按需要的实际上限进行设置。
Oracle从9i开始提供了PGA内存自动管理功能,即通过设置PGA_AGGREGATE_TARGET参数,为一个实例提供了所有可使用的PGA内存。以下就是查询所有会话所使用的PGA内存情况:
select sum(value)/1024/1024 Mb from v$sesstat s, v$statname n where n.STATISTIC# = s.STATISTIC# and name = 'session pga memory';
另外,Oracle有一个内部参数_PGA_MAX_SIZE,该参数缺省值为200MB,表示每个进程所能分配的最大PGA内存。
许多大型PL/SQL程序、大数据量排序操作等,的确需要消耗大量PGA内存,如何找到这些操作,请执行如下语句:
col name format a30 select sid, name, value from v$statname n, v$sesstat s where n.STATISTIC# = s.STATISTIC# and name like 'session%memory%' order by 3 asc;
上述语句根据PGA消耗大小,由大到小排序。进一步,根据上述语句返回的sid号,查询到正在执行的相应SQL语句:
select sql_text from v$sqlarea a, v$session s where a.address = s.sql_address and s.sid =;
通过如下设置,可生成相关dump信息,供Oracle Support人员分析内存超量分配问题:
SQL> oradebug setorapid 10 (this is for the oracle pid, use setospid for the os process id) SQL> oradebug unlimit SQL> oradebug dump heapdump 5 SQL> oradebug tracefile_name (shows the path and filename information) SQL> oradebug close_trace
若问题是偶发的,也可通过设置如下event来捕获相关信息:
-- 会话级 SQL> alter session set events '4030 trace name heapdump level 5'; -- 实例级 SQL> ALTER SYSTEM SET EVENT='4030 trace name heapdump level 5' scope=spfile;
在9.2.0.5之后,可以将level设置为536870917,将收集到更多dump信息。
如何解决或避免ORA-04030错误
ORA-04031:shared pool内存不够
什么是ORA-04031错误?
当Oracle不能从共享内存区(shared pool)分配一大块连续内存时,Oracle首先尝试刷新(Flush)当前已经不使用的共享内存,并将这些内存进行合并。如果依然不能分配到需要的内存时,则会报ORA-04031错误。以下就是该错误的官方描述:
ORA-04031: unable to allocate string bytes of shared memory (“string”,”string”,”string”,”string”)
Cause: More shared memory is needed than was allocated in the shared pool or Streams pool.
Action: If the shared pool is out of memory, either use the DBMS_SHARED_POOL package to pin large packages, reduce your use of shared memory, or increase the amount of available shared memory by increasing the value of the initialization parameters SHARED_POOL_RESERVED_SIZE and SHARED_POOL_SIZE. If the large pool is out of memory, increase the initialization parameter LARGE_POOL_SIZE. If the error is issued from an Oracle Streams or XStream process, increase the initialization parameter STREAMS_POOL_SIZE or increase the capture or apply parameter MAX_SGA_SIZE.
可见,ORA-4031错误不仅涉及shared pool,也包括large pool、java pool、streams pool等共享内存不够的问题。该类错误是一类比较常见的错误,本人在metalink搜索与之相关的文章就达到400多篇。其中与shared pool相关的错误原因诊断更复杂一些,因此本书重点介绍与shared pool相关的分析诊断和解决方法。
与shared pool相关的参数
欲深入了解ORA-4031在shared pool方面的错误原因,需要先了解与shared pool相关的如下参数:
该参数指定了shared pool缓存区的大小,单位为Byte,或者为K、M、G等。
通过该参数在shared pool中可指定一片预留空间,从而满足一些大的连续空间需求。该参数与下述的SHARED_POOL_RESERVED_MIN_ALLOC参数的综合使用,可以有效避免shared pool缓存区碎片问题的发生。
通常该参数应足够大到避免Oracle进行刷新(Flush)操作,但为合理使用内存资源,Oracle一般建议SHARED_POOL_RESERVED_SIZE参数设置为SHARED_POOL_SIZE的10%。
首先需要说明的是该参数在8i之后即变为内部隐含参数了,也就是变为_SHARED_POOL_RESERVED_MIN_ALLOC了。即该参数通常不需要客户来定义,但为诊断ORA-4031错误,我们还是不妨介绍该参数的含义。
该参数表示每次从预留内存中分配的最小内存。若扩大该值,意味着Oracle从预留内存可分配的次数将减少,也意味着Oracle需要更多的预留内存。虽然为隐含参数,但通过如下语句能查询到该参数的当前值:
SELECT nam.ksppinm NAME,val.ksppstvl VALUE
FROM x$ksppi nam,x$ksppsv val
WHERE nam.indx = val.indx
AND nam.ksppinm LIKE ‘%shared%’
ORDER BY 1;
10g/11g的自动内存管理与ORA-4031错误
Oracle 10g和11g分别推出了自动内存共享管理(Automatic Shared Memory Management,ASMM)和自动内存管理(Automatic Memory Management,AMM)功能。在这种自动管理模式下,Oracle可对shared pool, buffer cache, java pool 和 large pool进行自动管理,甚至在11g中可在SGA和PGA之间也进行自动管理。当需要从shared pool中分配内存而不够时,Oracle可自动从SGA其它区域甚至 PGA(11g)中分配内存。因此,在这种模式下,发生ORA-4031错误的可能性大大降低。
为使用ASMM特性,可设置SGA_TARGET参数。为使用AMM特性,可设置 MEMORY_TARGET参数。通过V$SGA_DYNAMIC_COMPONENTS、 V$SGA_RESIZE_OPS、V$MEMORY_DYNAMIC_COMPONENTS、V$MEMORY_RESIZE_OPS等视图,可了解当前的内存参数配置和自动调整情况。
尽管建议采用自动内存管理特性,但Oracle还是建议继续设置SHARED_POOL_SIZE、SHARED_POOL_RESERVED_SIZE等参数,从而确保shared pool的最小空间,避免过于频繁地自动调整内存,从而导致系统负载的增加。
ORA-04031错误的诊断
通常而言,ORA-04031错误的原因主要分为shared pool空间不够和shared pool空间碎片问题严重两类。以下就对这两类问题进行深入诊断:
首先通过查询V$SHARED_POOL_RESERVED视图,如果满足如下条件:
REQUEST_FAILURES > 0 and LAST_FAILURE_SIZE > SHARED_POOL_RESERVED_MIN_ALLOC
上述条件中REQUEST_FAILURES > 0,表示Oracle在预留的shared pool中申请不到空间了。而LAST_FAILURE_SIZE > SHARED_POOL_RESERVED_MIN_ALLOC,则表示最后一次申请失败的空间大于可分配的最小内存。此时说明shared pool空间可能的确不够了。
Oracle官方的建议是首先考虑降低SHARED_POOL_RESERVED_MIN_ALLOC参数值,这样可以在预留的shared pool空间中保存更多的对象。其次,再考虑扩大SHARED_POOL_SIZE和SHARED_POOL_RESERVED_SIZE值。
但本人建议直接尝试扩大SHARED_POOL_SIZE和SHARED_POOL_RESERVED_SIZE值,因为SHARED_POOL_RESERVED_MIN_ALLOC参数毕竟已经是隐含参数,一般不需要客户去设置了。
如果不是上述shared pool空间不够问题,并且满足如下条件:
REQUEST_FAILURES > 0 and LAST_FAILURE_SIZE < SHARED_POOL_RESERVED_MIN_ALLOC
最后一次申请失败的空间小于可分配的最小内存,也就是说不是空间不够。此时则是shared pool碎片问题了,导致该问题的原因通常是应用本身所导致,例如没有合理使用绑定变量等。下面将就这类问题的诊断和解决进行更深入的探讨。
需要说明的是,上述诊断方式依然适合于10g/11g之后自动内存管理功能。
ORA-04031错误的解决
通过如下查询:
SELECT SUM(pins) “EXECUTIONS”,
SUM(reloads) “CACHE MISSES WHILE EXECUTING”,
SUM(reloads)/SUM(pins)*100 “Hit Ratio”
FROM v$librarycache;
该查询是计算shared pool命中率的公式。如果Hit Ratio > 1%,则需要考虑扩大SHARED_POOL_SIZE参数。
如前所述,如果shared pool空间足够,但依然发生ORA-4031错误,则通常是以下原因导致的shared pool碎片问题:
为确定上述具体应用问题,可执行如下查询:
SELECT SUBSTR(sql_text,1,40) “SQL”, COUNT(*), SUM(executions) “TotExecs”
FROM v$sqlarea
WHERE executions < 5
GROUP BY SUBSTR(sql_text,1,40)
HAVING count(*) > 30
ORDER BY 2;
上述语句可显示使用常量,适合于绑定变量改造的SQL语句。
ORA-04031错误和Large Pool
Large Pool主要用于多线程连接(Multi-threaded)模式、XA协议分布式处理、RMAN备份恢复、并行处理等应用场景。Large Pool与其它内存区域管理不同之处是没有采用LRU算法,也就是说Large Pool中的内容不会被Oracle淘汰出去,只会在会话级被分配和释放。如果Large Pool空间不够,则会显示如下错误:
ORA-04031: unable to allocate XXXX bytes of shared memory (“large pool”,”unknown object”,”session heap”,”frame”)
通过如下查询,可显示large pool使用情况:
SELECT pool, name, bytes
FROM v$sgastat
WHERE pool = ‘large pool’;
解决与large pool相关的ORA-04031错误的通常做法就是扩大Large_Pool_Size参数。
ORA-04031错误和Shared Pool Flushing操作
在上述解决与shared pool相关的ORA-04031错误中,最有效的办法还是应用改造,特别是合理使用绑定变量。另外,可以通过设置CURSOR_SHARING为Similar/Force来强制使用系统绑定变量,但该解决办法将导致所有使用常量的语句都变为系统绑定变量,可能导致执行计划出现异常。因此,该办法也需谨慎使用,特别是需要经过测试验证其有效性和稳定性。
如果上述解决办法无法合理实施,但shared pool碎片问题的确比较严重,则可以考虑刷新shared pool的操作,即:
alter system flush shared_pool;
但该操作需考虑如下因素:
ORA-04031错误的高级诊断方法
如果上述诊断和分析还不能有效解决ORA-04031错误,则建议通过Metalink求助于Oracle Support专家了。通常,老外会让你进行如下设置,以便问题重现时,收集更多诊断信息,以便于问题分析和定位。
设置如下初始化参数:
event = “4031 trace name errorstack level 3”
event = “4031 trace name HEAPDUMP level 2”
设置这些参数需要数据库重启。或者在会话级进行如下设置:
SQL> ALTER SESSION SET EVENTS ‘4031 trace name errorstack level 3’;
SQL> ALTER SESSION SET EVENTS ‘4031 trace name heapdump level 536870914’;
当错误重现时,将在USER_DUMP_DEST目录或者11g的ADR中产生相应的trace文件,赶紧将这些文件上传到相应的SR中,让老外去分析和解决。
一个案例
很久以前的2004年,本人曾在一个项目上进行了一次比较专题的ORA-04031问题的处理,现摘取其中主要内容如下:
XX生产数据库系统在2004年1月30日频繁出现ORA-04031错误,表现为shared pool内存不够。现有shared_pool有关的参数设置如下:
shared_pool_size 300000000
shared_pool_reserved_size 25000000
在试图扩大shared_pool_size参数(800M、500M、350M…)时,出现如下错误:
ORA-27123:unable to attach to shared memory segment
这是由于在 32位的Oracle环境中,当SGA区大于256M时,需要重新定位(relocate)SGA区。否则会出现ORA-27123错误。考虑32位Oracle早已是被淘汰技术,而且限于篇幅,本书不介绍此问题的解决了。
其实,该系统当年在扩大shared_pool_size参数之后,仍然出现ORA-04031错误。这是就是shared pool的碎片问题了。为缓解碎片问题,特别是无法为大对象分配shared pool的问题,我们建议将大对象进行常驻的方法。以下就是相关脚本:
set pagesize 0;
set feedback off;
spool xhs_keep.sql;
select * from (
select ‘exec dbms_shared_pool.keep(‘||chr(39)||owner||’.’||name||chr(39)||’);’
from v$db_object_cache
where type in(‘PACKAGE’,’PACKAGE BODY’,’FUNCTION’,’PROCEDURE’)
order by sharable_mem desc)
where rownum <=200;
spool off;
在2004年1月30日出现ORA-04031错误的日志中,出现匿名package无法申请到shared pool:
ORA-04031: unable to allocate 4200 bytes of shared memory (“shared pool”,”unknown object”,”sga heap”,”library cache”)
建议尽量减少使用匿名package,并转换为存储过程,从而有利于管理和维护。
如果频繁出现ORA-04031错误,建议DBA定期对shared pool进行flush操作:
SQL> alter system flush shared_pool;
此操作能避免ORA-04031错误,但应用系统性能会有短时间的影响。
如果上述建议仍然不能解决ORA-4031错误。建议在init.ora文件中增加如下设置,以便在错误重现时能产生更多的trace文件,供Oracle Support进行深入分析。
event = “4031 trace name errorstack level 3”
event = “4031 trace name HEAPDUMP level 2”
11.4空间不够的问题
随着数据量的不断增长,数据库经常会出现空间不够的问题。导致空间不够的原因很多,解决办法也不是一味地增加空间。以下就是根据Oracle知识库的相关文章,对空间不够问题进行的分析和处理。
错误信息
针对不同数据对象的空间不够问题,Oracle提供了不同的错误信息:
ORA-1650: unable to extend rollback segment %s by %s in tablespace %s
ORA-1651: unable to extend save undo segment by %s in tablespace %s
ORA-1652: unable to extend temp segment by %s in tablespace %s
ORA-1653: unable to extend table %s.%s by %s in tablespace %s
ORA-1654: unable to extend index %s.%s by %s in tablespace %s
ORA-1655: unable to extend cluster %s.%s by %s for tablespace %s
ORA-1658: unable to create INITIAL extent for segment in tablespace %s
ORA-1659 unable to allocate MINEXTENTS beyond %s in tablespace %s
ORA-1683: unable to extend index %s.%s partition %s by %s in tablespace %s
ORA-1688: unable to extend table %s.%s partition %s by %s in tablespace %s
ORA-1691: unable to extend lob segment %s.%s by %s in tablespace %s
ORA-1692: unable to extend lob segment %s.%s partition %s by %s in tablespace %s
ORA-3233: unable to extend table %s.%s subpartition %s by %s in tablespace %s
ORA-3234: unable to extend index %s.%s subpartition %s by %s in tablespace %s
ORA-3238: unable to extend LOB segment %s.%s subpartition %s by %s in tablespace %s
… …
Oracle错误信息手册中针对上述大部分问题,基本都给出了增加数据文件的如下建议:
Action: Use ALTER TABLESPACE ADD DATAFILE statement to add one or more files to the tablespace indicated.
但实际上,导致空间不够的原因很多,应深入分析,并给出相应的解决方案。
诊断步骤
空间不够“unable to extend”的根本原因是无法为数据段(Segment)分配连续的空间。因此,应按如下步骤进行诊断:
首先对报错误的表空间,执行如下语句:
SELECT max(bytes) FROM dba_free_space WHERE tablespace_name = ‘<tablespace name>’;
如果针对TEMP临时表空间,则执行如下语句:
select tablespace_name, file_id, bytes_used, bytes_free from v$temp_space_header ;
如果是基于数据字典管理表空间并且PCT_INCREASE = 0,或者是基于本地化管理并且采用UNIFORM管理的表空间,则执行如下语句:
SELECT NEXT_EXTENT, PCT_INCREASE
FROM DBA_SEGMENTS
WHERE SEGMENT_NAME = <segment name>
AND SEGMENT_TYPE = <segment type>
AND OWNER = <owner>
AND TABLESPACE_NAME = <tablespace name>;
其中:
如果是基于本地化管理并且采用SYSTEM/AUTOALLOCATE管理的表空间,则没有合适的语句来确定NEXT_EXTENT值。但可以根据出错信息中显示的无法分配多少数据块数,再乘以该表空间的数据块大小,来确定NEXT_EXTENT值。
如果是基于数据字典管理表空间并且PCT_INCREASE > 0,则按照如下公式计算:
extent size = next_extent * (1 + (pct_increase/100)
例如,假设next_extent = 512000,pct_increase = 50 ,则:
next extent size = 512000 * (1 + (50/100)) = 512000 * 1.5 = 768000
针对“ORA-01650 Rollback Segment”错误,Oracle新版本回退段的PCT_INCREASE永远为0。针对“ORA-01652 Temporary Segment”,临时段的PCT_INCREASE为TEMP表空间相应的缺省存储参数。当然,诊断临时表空间不足的更有效办法,是找到相应的排序SQL语句,并对这些语句进行尽可能的优化。
针对数据文件,执行如下语句:
SELECT file_name, bytes, autoextensible, maxbytes FROM dba_data_files WHERE tablespace_name='<tablespace name> ‘;
针对临时文件,执行如下语句:
SELECT file_name, bytes, autoextensible, maxbytes FROM dba_temp_files WHERE tablespace_name='<tablespace name> ‘;
解决步骤
在完成上述诊断分析之后,可按如下步骤进行解决:
详细命令如下:
ALTER TABLESPACE <tablespace name> COALESCE;
ALTER DATABASE DATAFILE|TEMPFILE ‘<full path and name>’ AUTOEXTEND ON MAXSIZE <integer> <k | m | g | t | p | e>;
建议最好设置MAXSIZE参数,避免空间被消耗殆尽。
ALTER TABLESPACE <tablespace name> ADD DATAFILE|TEMPFILE ‘<full path and file name>’ SIZE <integer> <k | m | g | t | p | e>;
针对非临时和非分区数据段:
ALTER <SEGMENT TYPE> <segment_name> STORAGE ( next <integer> <k | m | g | t | p | e> pctincrease <integer>);
针对非临时和分区数据段:
ALTER TABLE <table_name> MODIFY PARTITION <partition_name> STORAGE ( next <integer> <k | m | g | t | p | e> pctincrease <integer>);
针对临时数据段:
ALTER TABLESPACE <tablespace name> DEFAULT STORAGE (initial <integer> <k | m | g | t | p | e> next <integer> <k | m | g | t | p | e> pctincrease <integer>);
ALTER DATABASE DATAFILE|TEMPFILE ‘<full path and file name>’ RESIZE <integer> <k | m | g | t | p | e>;
11.5 ORA-00376: 数据库文件不可读
故障现象
由于硬件、操作系统、集群软件、存储系统、人为操作失误等各方面原因,可能导致某个数据库文件出现异常,导致Oracle数据库无法读取这些文件,出于数据保护目的,Oracle会自动将这些文件设置为OFFLINE状态,并在alert.log文件中记录类似如下的错误信息:
ORA-00376: file 9 cannot be read at this time
ORA-01110: data file 9: ‘/u01/test.dbf’
ORACLE Instance PROD (pid = 8) - Error 376 encountered while recovering transaction (25, 37) on object 109359.
Tue Jul 12 10:35:46 2011
故障诊断
检查相关数据文件是否为Offline状态
SQL>Select status,file#,name from v$datafile where file#=<file value reported in ORA-01110>
例如,上例中:
SQL>Select status,file#,name from v$datafile where file#=9
STATUS FILE# NAME
———- ——- — ———
Recover 9 /u01/test.dbf
可见,9号文件状态为Recover,需要进行Recover操作。进一步查询该文件的当前SCN号:
SQL>column checkpoint_change# format 99999999999999999
SQL>select file#, status, fuzzy, checkpoint_time, checkpoint_change#,resetlogs_change#, resetlogs_time from v$datafile_header where file#=9
FILE# STATUS FUZ CHECKPOIN CHECKPOINT_CHANGE# RESETLOGS_CHANGE# RESETLOGS
———- ——- — ——— —————— —————- ———
9 OFFLINE YES 20-JUL-11 8517808305328 4263932 21-JUN-11
这样,上述9号文件的当前SCN为8517808305328,我们需要通过该SCN号之后的日志文件对9号文件进行recover操作。
故障恢复
查询包含上述SCN号的归档日志,并通过该归档日志至当前日志对该文件进行恢复:
SQL>Select sequence#,name from v$archived_log where 8517808305328 + 1 between first_change# and next_change# ;
SEQUENCE# NAME
—— ——————————————-
68 /u01/app/archivelog/O1_MF_1_68_72FLC6FO_.ARC
即针对9号文件,从68号归档日志至当前日志进行恢复,并将该文件恢复为Online状态。
SQL>Select name,sequence# from v$archived_log where sequence# >=68 ;
— 确保68号至当前归档日志都存在
SQL> recover datafile 9;
ORA-00279: change 8517808305328 generated at 07/20/2011 14:45:13 needed for thread 1
ORA-00289: suggestion :
/u01/app/archivelog/O1_MF_1_68_%U_.ARC
ORA-00280: change 8517808305328 for thread 1 is in sequence #68
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
auto
Log applied.
Media recovery complete.
SQL>Alter database datafile 9 online ;
故障根源分析及防范
如上所述,ORA-00376错误通常是由硬件、操作系统、集群软件、存储系统、人为操作失误等各方面原因而导致。因此,当ORA-00376错误发生时,一定要通过操作系统类似errpt命令去查找硬件和操作系统等环境是否存在问题,或者相关系统软件是否有Bug存在。
例如,本人曾在AIX平台就遭遇过一次此故障,就是通过IBM HACMP命令对LV设备做扩容操作时,触发了HACMP一个Bug而导致该LV不可见,触发了ORA-00376错误。另外,在该次故障中,客户对LV进行的扩容操作是对联机操作情况下进行的,即在数据库仍然对外服务的情况下进行的。因此,如果业务允许,建议大家尽量在停止对外服务的情况下,进行这类数据库变更操作。
11.6 ORA-01555: 快照太旧
什么是ORA-01555错误?
ORA-01555是Oracle数据库运行过程中常见的一个错误。以下就是Oracle关于ORA-01555错误的经典描述:
ORA-01555: snapshot too old (rollback segment too small)
Cause: rollback records needed by a reader for consistent read are
overwritten by other writers
简单而言,就是为保证一致性读的回退段数据被其它写进程所覆盖了。以下就是一个典型例子:
ORA-01555错误的原因和解决方案比较复杂,Oracle有关该错误处理的文章也比较多。本书我们一方面主要针对9i之后的自动UNDO管理技术(Automatic UNDO Management),另一方面也只针对普通表的ORA-01555错误处理,而不关注LOB等特殊对象的ORA-01555错误处理。
如何获取ORA-01555错误相关信息?
首先,分别从应用会话窗口和alert.log中分别获取相关信息。
例如,应用会话窗口显示错误信息:
ORA-01555: snapshot too old: rollback segment number 9 with name “_SYSSMU1$” too small
Alert.log中显示:
ORA-01555 caused by SQL statement below (Query Duration=9999 sec, SCN:0x000.008a7c2d)
其次,通过alert.log确定QUERY DURATION。上例中为9999秒。
第三,从应用会话信息中确定undo segment名称。例如:_SYSSMU1$。
最后,确定UNDO表空间的UNDO_RETENTION值。
SQL> show parameter undo_retention
如何解决ORA-01555错误?
此时,Oracle无法保证当提交的事务过期,也就是超过UNDO_RETENTION时间之后,还能确保数据的一致性读取。
这种情况下,最有效的解决办法是优化查询语句,降低语句的QUERY DURATION时间。如果无法优化了,则只能参考QUERY DURATION时间值来扩大UNDO_RETENTION值,确保Oracle保存更长时间的UNDO信息。
扩大UNDO_RETENTION值,意味着需要更多的UNDO表空间,下面还将介绍UNDO表空间的计算方法。
在这种情况下,通常而言是UNDO表空间满了。如何进一步确定UNDO表空间是否满了呢?执行如下脚本:
set pagesize 25set linesize 120
select inst_id,
to_char(begin_time,’MM/DD/YYYY HH24:MI’) begin_time,
UNXPSTEALCNT “# Unexpired|Stolen”,
EXPSTEALCNT “# Expired|Reused”,
SSOLDERRCNT “ORA-1555|Error”,
NOSPACEERRCNT “Out-Of-space|Error”,
MAXQUERYLEN “Max Query|Length”
from gv$undostat
where begin_time between
to_date(‘<start time of the ORA-1555 query>’,’MM/DD/YYYY HH24:MI:SS’)
and
to_date(‘<time when ORA-1555 occured>’,’MM/DD/YYYY HH24:MI:SS’)
order by inst_id, begin_time;
其中:
Tue May 26 16:16:57 2009ORA-01555 caused by SQL statement below (SQL ID: 54yn3n36w24ft, Query Duration=922 sec, SCN: 0x0007.8a55f4e3)
922秒为15分22秒。这样 ORA-1555开始发生的时间为 May 26 16:01:35 2009(16:01:35 = 16:16:57 - 15:22)。
如何计算UNDO表空间大小?
UNDO表空间的计算公式如下:
UndoSpace = UR * (UPS * DBS)
其中:
上述UNDO_RETENTION、DB_BLOCK_SIZE可通过初始化参数文件获取,而UPS则可以通过查询v$undostat视图而获得。Oracle建议查询业务高峰时段产生的UNDO数据块数量。为此,执行如下查询:
SELECT undoblks / ((end_time - begin_time) * 86400) “Peak Undo Block Generation”
FROM v$undostat
WHERE undoblks = (SELECT MAX(undoblks) FROM v$undostat);
最终,计算高峰时段所需UNDO表空间大小的语句如下:
SELECT (UR * (UPS * DBS)) AS “Bytes”
FROM (SELECT value AS UR FROM v$parameter WHERE name = ‘undo_retention’),
(SELECT undoblks / ((end_time - begin_time) * 86400) AS UPS
FROM v$undostat
WHERE undoblks = (SELECT MAX(undoblks) FROM v$undostat)),
(SELECT block_size AS DBS
FROM dba_tablespaces
WHERE tablespace_name =
(SELECT UPPER(value)
FROM v$parameter
WHERE name = ‘undo_tablespace’));
11.7 ORA-30036: UNDO表空间无法扩展
什么叫ORA-30036错误?
ORA-30036也是Oracle数据库运行过程中常见的一个错误。以下就是Oracle关于ORA-30036错误的经典描述:
Error: ORA-30036 (ORA-30036)
Text: unable to extend segment by %s in undo tablespace ‘%s’
—————————————————————————
Cause: the specified undo tablespace has no more space available.
Action: Add more space to the undo tablespace before retrying the operation. An alternative is to wait until active transactions to commit.
该错误表示就是UNDO表空间不够了,简单解决办法就是对UNDO表空间进行扩容。但如同Oracle其它空间不够的类似错误一样,扩容并非唯一解决办法。
UNDO表空间分配算法
欲深入了解ORA-30036错误原因和解决办法,其实应从深入了解UNDO表空间分配算法开始。以下就是该算法主要思路:
诊断和解决办法
select sum(bytes) from dba_free_space where tablespace_name=’UNDOTBS1′;
select sum(bytes) from dba_data_files where tablespace_name=’UNDOTBS1′;
select autoextensible from dba_data_files where tablespace_name=’UNDOTBS1′;
SELECT DISTINCT STATUS, SUM(BYTES), COUNT(*) FROM DBA_UNDO_EXTENTS GROUP BY STATUS;
如果没有过期(expired)而只有非过期(unexpired)的Undo Extent,以及Active Extents,则Undo表空间的确太小,需要对Undo表空间大小进行重新规划并扩容。关于Undo表空间大小的计算方法,请见本章前述内容。在10g中还可以通过OEM中的Undo Advisor特性来进行Undo表空间的规划。
假设Undo表空间不够,则Oracle会尝试偷取非过期(unexpired)的Undo Extent,此时可能会导致ORA-1555错误。如果也没有非过期(unexpired)的Undo Extent,则的确需要对Undo表空间进行扩容。
10g中可以为Undo表空间指定Guaranteed Undo Retention特性。例如:
create undo tablespace undotbs1 datafile ‘undotbs1.dbf’size 1000M autoextend on
retention guarantee;
这样,Oracle就不会重复使用非过期(unexpired)的Undo Extent。因此,此时只能对Undo表空间扩容了。
关于Bug 5442919
如果有过期(expired)的Undo Extent,意味着这些extent是可以被重用的。但系统却报出ORA-30036,则很有可能是撞上Oracle Bug 5442919了。以下就是满足该Bug的所有条件:
select count(*) from dba_rollback_segs where status=’OFFLINE’;
select sum(bytes) “UNEXPIRED BYTES” from dba_undo_extents where tablespace_name=’UNDOTBS1’and status=’UNEXPIRED’;
select sum(bytes) “EXPIRED BYTES” from dba_undo_extents where tablespace_name=’UNDOTBS1’and status=’EXPIRED’;
该Bug在10.2.0.4以及11g中就已经修复了。在之前的版本,例如9i和10.2.0.1/2/3中,在某些平台可以向Oracle服务部门申请补丁回退(Backport),但这些版本早已经过了Oracle产品服务期,估计已经很难得到Oracle服务部门支持了。
11.8 日志切换频度过高问题
10多年之后才搞明白的一个原理
本人自从1988年开始接触并使用Oracle数据库,但直到1999年在某网站从事专职 DBA之后,才弄明白Oracle一个基本原理:我们都知道如果通过Word编写文档,当我们按“保存”按钮时,Word会将最新的文档存到硬盘文件系统中去了。但是,在我们执行Oracle SQL语句或应用,提交(Commit)一个事务之后,Oracle并没有马上把数据真正写到硬盘上去,而只是把该事务的DML/DDL语句写到联机日志文件去了。
下图先描述了Oracle的Redo log buffer、LGWR进程和Redo Log日志文件的工作原理图:
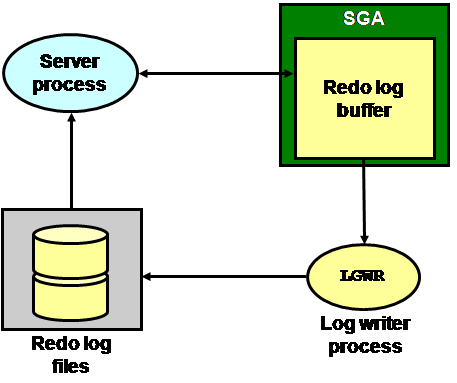
即当Oracle在执行DML/DDL语句时,先将这些语句写入到SGA的Redo Log Buffer之中。当发生如下几种情况时,才通过LGWR进程将这些语句,也就是日志项(Redo Log Entry)写入到Redo Log日志文件之中:
也就是说,当执行Commit语句之后,Oracle只是把该事务的DML/DDL语句写到联机日志文件去了,而并没有马上把数据真正写到硬盘上去。那什么时候Oracle才真正把修改的数据写入到硬盘呢?一种情况下是在redo log一个(组)日志文件被写满,切换到另一个(组)redo log时候,此时叫做Log Switch。另一个就是在CHECKPOINT事件发生时。
Oracle这种“延迟+批量”进行数据库操作的目的就是降低因频繁commit操作而产生的小事务对I/O读写操作的冲击,而是到事务堆积到一定程度,具体而言就是写满一个日志文件或发生CHECKPOINT事件发生时,才成批地进行数据库写操作,降低存储操作次数,提高整体处理性能。
这样,联机日志文件大小成了影响数据库日常交易操作性能的一个重要因素。联机日志文件设计比较大,显然能降低Log Switch次数,即降低I/O次数。但凡事都有两面性,如果设计过大,一旦数据库发生故障,特别是实例宕机而重启时,smon后台进程需要恢复的日志太多,故障恢复时间可能很长,从而影响整个系统的高可用性和故障恢复能力。
因此,联机日志文件大小的设计是需要综合平衡、全面考虑的。这就是Oracle作为企业级软件供应商考虑问题的角度和全面性。
本节下面内容主要讨论因联机日志文件太小,而引发的日志文件切换太频繁问题的诊断,以及可能造成的严重后果。
日志文件切换太频繁问题的诊断和解决
首先,关于日志文件大小的设置,Oracle公司并没有提出官方的建议,因为不同应用系统特点不同,Oracle很难给出一个文件大小建议的确切数据。但是,Oracle 公司给出了日志切换时间的建议。即:在数据库平时正常工作情况下,日志文件切换频度不应该低于15分钟,而在数据库工作高峰期,切换频度不应该低于5分钟。
如何诊断?一方面通过检查alert.log日志文件。当日志文件切换时,Oracle都会将切换时间记录在alert.log中。因此,粗略检查一下alert.log,就能看出redo log切换频度。
另一方面,通过检查alert.log文件,如果频繁出现“checkpoint not complete”报警信息,也说明日志产生非常多,系统都无法顺利完成checkpoint操作了。
再则,通过v$log、v$log_history等视图和如下语句,就能了解更精确的信息。例如日志文件切换和生成速度、大小等信息:
SQL> select group#,bytes from v$log;
SQL> select to_char(FIRST_TIME, ‘yyyy-mm-dd hh24’), count(*)
from v$log_history
where thread# = 1
group by to_char(FIRST_TIME, ‘yyyy-mm-dd hh24’)
order by to_char(FIRST_TIME, ‘yyyy-mm-dd hh24’);
上述第二个语句就是查询每小时的联机日志产生个数。根据这些视图,可以进行各种日志文件产生量的统计分析。以下就是我的同事通过这些视图,以及Oracle相关工具,对某系统的日志文件产生量进行的统计分析:

可见,该系统当前日志文件切换分布在0~5分钟之间的量,已经占到全部时段的77%。也就是说,该系统日志文件太小切换频度太高,导致存储I/O操作太多,是影响系统整体性能的重要因素。
上述系统的问题原因其实很简单,就是在数据库最初设计时,设计人员没有深入研究日志文件工作原理,更没有仔细规划日志文件大小,而是采用了缺省的配置:50M。再次验证:企业级数据库就需要专业化的精细化设计。
如何改造?就是新建一批更大的日志文件组,并通过Log Switch操作,逐渐切换到新的日志文件组,并删除老的、小的日志文件组。以下就是大致过程:
―― 新建一批更大的日志文件组
alter database add logfile group 4 (‘/home1/oradata/DMCEDMAA/redo04.log’) size 256M;
alter database add logfile member ‘/home3/DMCEDMAA/oradata/redo04_A.log’ to group 4;
alter database add logfile group 5 (‘/home1/oradata/DMCEDMAA/redo05.log’) size 256M;
alter database add logfile member ‘/home3/DMCEDMAA/oradata/redo05_A.log’ to group 5;
alter database add logfile group 6 (‘/home1/oradata/DMCEDMAA/redo06.log’) size 256M;
alter database add logfile member ‘/home3/DMCEDMAA/oradata/redo06_A.log’ to group 6;
―― 强行切换到新日志文件组
alter system switch logfile;
alter system switch logfile;
alter system switch logfile;
―― 删除旧日志文件组
alter database drop logfile group 1;
alter database drop logfile group 2;
alter database drop logfile group 3;
再次说明,至于新的日志文件到底设置到多大,Oracle并没有给出明确建议。笔者的建议是:首先,需要考虑日志文件大小对联机交易和数据库恢复能力两方面都有影响,切忌片面追求单一目标,例如盲目追求联机交易性能,而将日志文件设置太大。其次,逐步扩大日志文件大小,满足Oracle切换频度和切换时间建议值即可,即平时15分钟,高峰5分钟。
最严重情况:宕机!
就在撰写此章时,本人耳闻了一个重要客户RAC数据库异常宕机的严重故障。故障的起因是硬件报错,即光纤出现问题,但给Oracle带来的影响是:硬件故障期间,应用正在进行批处理操作,产生了大量日志,而日志文件设置过小,日志文件切换太频繁,阻塞了Oracle其它操作,Oracle居然把CHKP后台进程杀掉,最终导致数据库宕机。
以前知道日志文件设置太小,会引起数据库I/O操作太多,影响性能。这次居然导致数据库宕机了,这可是前所未闻,也让我开眼了,呵呵。以下就是该故障的详细过程,
某客户的RAC系统出现硬件报错,后确认是光纤出现问题。系统报错信息如下:
[jtdba@sxyxydb2 bdump]$errpt | more
IDENTIFIER TIMESTAMP T C RESOURCE_NAME DESCRIPTION
DCB47997 0930121413 T H hdisk142 DISK OPERATION ERROR
3074FEB7 0930121413 T H fscsi2 ADAPTER ERROR
F7FA22C9 0929074513 I O SYSJ2 UNABLE TO ALLOCATE SPACE IN FILE SYSTEM
36A12C28 0929064313 T S VRTS:VXFS
… …
即节点2连接存储的链路出现硬件报错,造成IO效率下降。在硬件故障期间,节点2的Oracle实例居然宕机了,以下就是alert.log记录的当时错误信息:
… …
Sun Sep 29 03:21:08 2013
Errors in file /u01/oracle/admin/chnldb/bdump/chnldb2_dbw0_1979152.trc:
ORA-00240: control file enqueue held for more than 120 seconds
Sun Sep 29 03:28:18 2013
System State dumped to trace file /u01/oracle/admin/chnldb/bdump/chnldb2_diag_1876292.trc
Sun Sep 29 03:28:26 2013
Errors in file /u01/oracle/admin/chnldb/bdump/chnldb2_diag_1876292.trc:
ORA-00494: enqueue [CF] held for too long (more than 900 seconds) by ‘inst 2, osid 1979152’
Sun Sep 29 03:28:33 2013
… …
根据上述ORA-00494错误信息,我的同事很快在metalink中找到了《Database Crashes With ORA-00494 (Doc ID 753290.1)》,结合客户系统实际情况,给出了如下分析结论:
当硬件故障发生期间,数据库正在进行大批量数据处理,由于日志文件太小,导致REDO切换频繁,而CHECK POINT 、DBWR、LGWR进程都需要进行大量I/O操作,I/O写入速度很低。也使得Oracle访问控制文件操作超时,超过了900秒,在上述红色错误信息中,实例2的1979152进程阻塞了控制文件资源(CF enqueue)。此时,Oracle LGWR进程开始杀阻塞进程1979152,而1979152进程正是CKPT 后台进程,因此最终导致节点2宕机。
当然在此次事故中,硬件光纤故障是“罪魁祸首”,在硬件厂商修复相关问题之后,系统很快平稳下来。但数据库日志文件设置太小,导致切换频度过高和过多的I/O操作,也在此次事故中起到了推波助澜的作用,并最终导致宕机。因此,Oracle建议适当扩大日志文件大小,确保日志文件切换频度满足Oracle建议值。Oracle甚至建议:如果采用Oracle相关智能建议工具(Advisor),可以通过查询V$INSTANCE_RECOVERY视图的OPTIMAL_LOGFILE_SIZE字段值,参考Oracle给出的日志文件大小建议。
11.9 故障处理的感和悟
故障诊断需要一颗伟大的心脏!
先回顾本人在《品悟性能优化》一书中针对故障诊断所叙述的一些观点:
可见,故障诊断真是一门需要技术、方法、经验和心理素质皆备的学科。相比《品悟》一书,本书在故障诊断领域更为浓墨重彩一些,上一章和本章就分别以案例叙述不同故障的处理方法和思路,并介绍了数据库常见诊断工具的使用、常见故障分析等内容。
下面还将结合上述内容,针对故障处理发出更多的感和悟。
更多的感和悟
一旦故障发生,特别是出现数据库宕机、Hang、数据坏块、数据文件损坏、数据库无法启动和打开等严重故障时,首先应保持一颗冷静的心和清醒的头脑,其次,应判断故障的影响范围,特别是对业务的影响,初步确定解决方案,例如若数据库宕机,先尝试重新启动实例并打开数据库;若数据坏块,初步确定坏块所影响的数据对象,并初步确定恢复方案等。再则,尽量先考虑恢复业务,例如,将损坏的数据文件隔离(Offline),先打开数据库等。
总之,即便客户特别是领导已经是火急火燎,也应谋定而动,切忌自己乱了分寸,毛毛躁躁。
就像看病就诊需要做各种检查一样,故障诊断、分析和处理同样需要全面的故障信息。因此,一方面当故障发生时,一定要注意保留故障现场信息,例如各种前台报错信息,alert.log、crsd.log等日志信息和trace文件信息,另一方面就像本书前一章所介绍的一样,主动、全面、准确地掌握一些常用的故障诊断工具的使用,将有效提高问题的诊断、分析和解决效率,也能加快与Oracle后台技术人员的沟通效率。
故障的发生是任何人都不愿意看到的,故障的类型也是多种多样的。但针对一些诸如ORA-4030、ORA-4031、ORA-1555等常见错误,其实Oracle公司都提供了一些规范化的分析和处理流程文档。如果我们能在平日就研究这些文档,并形成自己的问题处理预案,那就像打仗需要提前准备作战方案一样,即便不是百战不殆,至少也能大大提高这些常见故障的处理效率。
数据库出现故障的原因千奇百怪,也涉及硬件、系统软件、Oracle数据库软件、应用软件等各个层面。就像前一章介绍的第一个案例一样,我们可以根据故障情况,先从Oracle错误信息文档开始,也可自己去Metalink等Oracle官方技术支持站点去查找原因和解决方式。如果都未奏效,或者故障非常严重、情形非常紧急,特别是在怀疑可能是Oracle产品本身问题的情况下,则建议迅速通过在Metalink中创建SR,而寻求Oracle官方技术支持。Oracle全球技术支持中心毕竟有庞大的技术专家资源,也有大量的案例经验,如果是产品问题,更可与Oracle研发部门直接沟通,毕竟解铃还需系铃人。此时,就需要提高SR处理效率,提高与后台技术专家的沟通效率。这些内容本章就不详述了。
11.10本章参考资料及进一步读物
本章参考资料及进一步读物:
| 序号 | 资料类别 | 资料名称 | 资料概述 |
| 1. | My Oracle Support | 《ORA-600/ORA-7445/ORA-700 Error Look-up Tool (Doc ID 153788.1)》 | 专门介绍ORA-00600/ORA-7445/ORA-00700等内部错误的诊断工具的官方文档。 |
| 2. | My Oracle Support | 《ORA-600 [729] “UGA Space Leak” (Doc ID 31056.1)》 | 一篇介绍ORA-600 [729]错误处理的文档。 |
| 3. | My Oracle Support | 《Diagnosing and Resolving ORA-4030 errors [ID 233869.1]》 | PGA不够导致ORA-4030常见错误的文档:原理、原因、诊断和处理方法。 |
| 4. | My Oracle Support | 《Master Note for Diagnosing OS Memory Problems and ORA-4030 (Doc ID 1088267.1)》 | 该文档包含了更多有关ORA-4030错误处理的文档。 |
| 5. | My Oracle Support | 《Diagnosing and Resolving Error ORA-04031 on the Shared Pool or Other Memory Pools [Video] (Doc ID 146599.1)》 | 常见的ORA-4031错误的处理文档,还有视频哦。 |
| 6. | My Oracle Support | 《Troubleshooting and Diagnosing ORA-4031 Error [Video] (Doc ID 396940.1)》 | 常见的ORA-4031错误处理的又一篇文档,更多的原理介绍。 |
| 7. | My Oracle Support | 《Master Note for Diagnosing ORA-4031 (Doc ID 1088239.1)》 | 该文档包含了更多有关ORA-4031错误处理的文档。 |
| 8. | My Oracle Support | 《Resolving ORA-00376 Error Encountered in database (Doc ID 1339985.1)》 | 数据文件不可访问ORA-00376错误的标准处理文档。 |
| 9. | My Oracle Support | 《TROUBLESHOOTING GUIDE (TSG) - UNABLE TO CREATE / EXTEND Errors (Doc ID 1025288.6)》 | 无法创建或扩展空间的原因和处理方法。 |
| 10. | My Oracle Support | 《Master Note: Troubleshooting Oracle Tablespace Management (Doc ID 1522807.1)》 | 但凡遇到表空间管理方面问题,这篇文章都值得参考。包括SYSTEM、SYSAUX、Temporary、UNDO,以及普通表空间,内含很多链接文章。 |
| 11. | My Oracle Support | 《Overview Of ORA-01653: Unable To Extend Table %s.%s By %s In Tablespace %s (Doc ID 151994.1)》 | 表空间不够了,简单的增加增加数据文件吗?不尽然,这篇文章介绍了多种可能的处理方法:增加数据文件,Resize数据文件,设置自动扩展,碎片管理… … |
| 12. | My Oracle Support | 《ORA-01555 “Snapshot too old” - Detailed Explanation [ID 40689.1]》 | ORA-01555(快照太旧)一类经典错误的详细原理解释。 |
| 13. | My Oracle Support | 《How To Size UNDO Tablespace For Automatic Undo Management [ID 262066.1]》 | 如何计算UNDO表空间大小?这篇文章给出了详细的计算过程和公式。 |
| 14. | My Oracle Support | 《TROUBLESHOOTING GUIDE (TSG) - ORA-1555 [ID 467872.1]》 | 有关ORA-1555处理的一篇指导性官方文档。 |
| 15. | My Oracle Support | 《Full UNDO Tablespace In 10gR2 [ID 413732.1]》 | 10g以上版本的UNDO表空间经常处于100%使用率状态,这是问题吗?需要为UNDO扩容吗?这不是问题,是正常现象,除非遇到了ORA-1555或ORA-30036错误。该文章进行了详细的原理解释。 |
| 16. | My Oracle Support | 《Troubleshooting ORA-30036 - Unable To Extend Undo Tablespace [ID 460481.1]》 | 这是对UNDO表空间无法扩展错误的诊断和处理的标准文档。 |
| 17. | My Oracle Support | 《Database Crashes With ORA-00494 (Doc ID 753290.1)》 | 日志文件太小,导致REDO切换频繁,最终居然会导致数据库实例宕机。这篇文章就描述了这样一件典型故障。 |
正文到此结束
- 本文标签: 配置 API App 操作系统 ask logo 协议 ip 线程 map 管理 智能 解决方法 DDL linux 服务器 db 数据库 sql 领导 operating system 参数 统计 文章 站点 db2 Oracle 集群 大数据 空间 软件 core ACE 备份 IBM description 网站 NSA 时间 文件上传 src Word root tab 事故 IDE 需求 value lib 删除 java aix swap cat 数据 代码 实例 dist http rmi unix tar 产品 UI 多线程 Select 企业 ECS 目录 测试 进程
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

