简单验证码识别及工具编写思路
注:此文章只适合简单验证码,最后也将编写的工具附上以及关键部分代码和使用说明文档
0x00 简介
虽然验证码发展到如今有许多人类都难以识别的状态了,但人有部分老系统使用的验证码异常的简单。还有一些网站由于程序员本身的素质或者缺乏相关图像相关的知识,所以并没有自己写验证码的生成程序,而是直接在网上随便复制粘贴一个Demo级别的代码来用,以达到网站有验证码的目的,而忽略了验证码的强弱性,导致很多网站的验证码都是爆款弱验证码
如:

还有更傻缺的比如:
直接就能复制的...这种是完全不知道验证码的意义或者为了应付而做的验证码
0x01 处理方式
好吧忽略上面的图继续说
对于那些简单验证码他们的共同点是
- 标准字体
- 背景单简单甚至纯色没有背景
- 字体并没有粘贴在一起
而本文讨论的就是这类的验证码。对于那种连背景都没有的纯色、标准字体、没有黏贴的那种再简单不过了直接就是100%的识别率
这种就不讨论了 下面来看看wooyun的验证码
Wooyun的验证码有两种状态

一种是白色文字深色背景 一种是黑色文字浅色背景
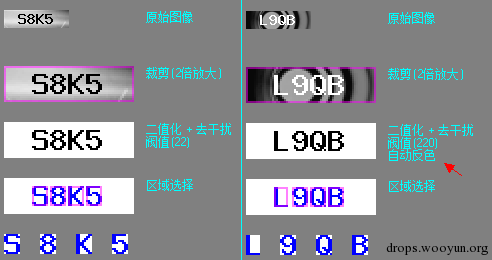
如果只有一种无论是那种设定一个阀值都能很好的二值化 但现在的情况却是有两种 所以我能想到的最简单的方式 那好 我就给出两个阀值 对于黑色文字我就用一个较小一点的阀值 对于白色文字我就用一个较大一点的阀值
但是这样还是会出现一个问题 白色文字二值化后背景黑色文字白色 而黑色文字二值化后背景白色文字黑色 就像下面一下

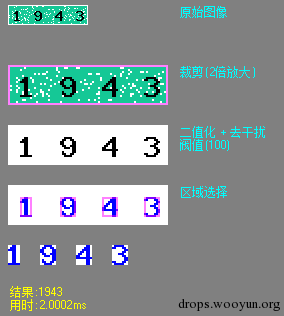
可以看出上面我左边框选区域一切正常 而右边却出了问题 那是因为在我写程序的时候我认为二值化后文字都是黑色背景是白色 所以我就把黑色区域当作文字来框选就看到了如上的效果 所以说这是一个问题 不仅要二值化二值化后还要到底白色是文字还是黑色是文字
于是我又想到一种办法 通常情况下一张图上背景的面积都会大于文字所占用的面积 所以在二值化的同时我还做了一件事情 二值化的同时记录下黑点个数和白点个数 如果黑点的个数大于了白点的个数那么我就把黑白反色一下让黑色像素点变成最少 这样再把黑色像素当作文字处理
这样做还有一个问题就是 我应该怎么知道什么时候应该使用那一个阀值来二值化 当然办法可以有很多 比如当图像上深色像素多余浅色像素的时候使用较大阀值 否则相反 不过我并不是这样做的

在工具上我提供了一个框让用户输入验证码的字符个数 这样的话我对体统的阀值挨个遍历 二值化后去识别区域 如果框出来的区域个数是有问题的 那么就换下一个阀值 如果所有阀值都遍历完了还是有问题 那么这验证码确实也是超出这个工具的范围了 因为这个工具的目的是通用 对于那些需要单独写代码来识别的不在他的能力范围内
在这之前一些验证码可能还需要一些处理比如很常见的一些验证码有边框的
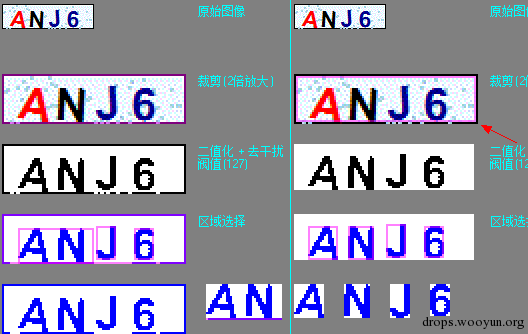
左边是没有裁剪的边框一起被二值化成为了黑色 然后拆字就悲剧了 右边是裁剪掉了一个像素的把边框去掉了 然后就一切正常了 这种情况就不说了 都懂的
还有一种比较复杂的情况 因为二值化并不是万能的 并不是说什么验证码一进行二值化后文字和背景就出来了 下面这张图是我以前程序需要做的百度推广的验证码识别

上面这张图不怎么能看到效果 因为都是好几年前的事情了 验证码连接访问已经是500了 这张图都是测试的时候的截图
我描述一下情况吧 上面的验证码 首先有边框 文字 干扰线 即使能把边框裁剪掉也找不到一个合适的阀值来把线条和文字分离 很简单因为他的线条的颜色比文字的颜色深 如果我的阀值太小 那么我的文字就没有了 只会剩下一些线条在哪里

这图为上面那张图片上验证码的NZ两个字符在ps中放大的效果(尽管上面图像原来并非保存的png格式已经失真 但大概还是能看到点什么的) 我也去翻了翻以前的代码来看 当初我二值化的时候并非直接二值化的 在二值化之前还单独对RGB进行了判断 代码截图如下

别百度推广的验证码是我做的第一个验证码识别程序 所以我一直记得很清楚 不是一个二值化就能搞定的 所以说在这个工具中我也加入了同样可以单独处理RGB的功能
由于百度的这个验证码已经访问不了了 所以我找了一个同样有线条的验证码 但是这个验证码线条颜色比文字颜色浅 所以我就用默认的127作为阀值 假设二值化无法搞定

用127阀值上面线条一起被黑化了 但是图片中文字颜色接近黑色而线条颜色却要浅一点 所以判断的时候 可以认为RGB的平均值大于20的就视为背景 就可以这样干

然后效果就成了这样
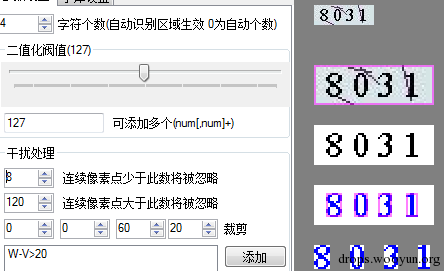
这样线条就被处理掉了 不过这个验证码直接设置阀值就能搞定 只是为了说明所以采用127作为阀值 还有一点这个验证码和百度的那个 他们线条都是在文字的下方 如果是在文字上方 那么同样的超出了这个工具的范围 对于线条在上方的 我想过一些处理方式 假设线条为红色的时候 我在遍历的时候遇到一个红色像素点 我就把红色像素设置为和他相邻像素的非红色的颜色 但是我想了一想这个“相邻”就涉及了它周围八个像素点 我应该取那一个像素点的颜色 如果是在背景上还好 他周围应该都是背景的颜色 那一个都无所谓 可是如果是在线条、背景还有文字的交界处就不好处理了 所以工具里面暂时还没提供这样的功能 还有那种很难分离背景或者字黏贴在一起的但是每个文字都是一个颜色的那种 也想过一些处理方式 但是实现起来我感觉都会纯在一些小问题 所以就还展示没有做 就不扯那么多了 等做好了再来扯 才比较有证据
0x02 拆字和识别
下面来说说验证码识别中的一个难点 -> 拆字
基本上在我看来 能正确的拆字 那么就已经成功了80%了 因为剩下的就是比对的问题了 我在工具中只提供了两种方式拆字
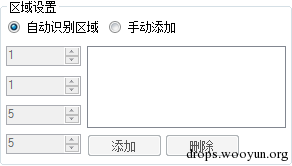
手动添加就不用说了 我这里的自动识别是最传统的深度遍历 从图像的第一个像素点开始遍历 因为图像已经二值化 按照我的工具的理解 就只剩下白色背景和黑色文字 所以遇到一个黑色像素点的时候开始记录 然后开始深度遍历 大概效果如下
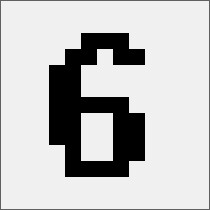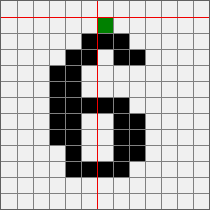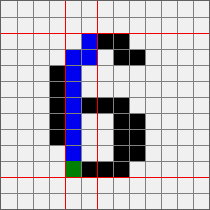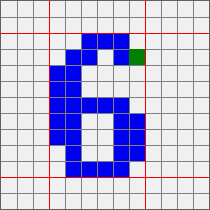
大概代码如下
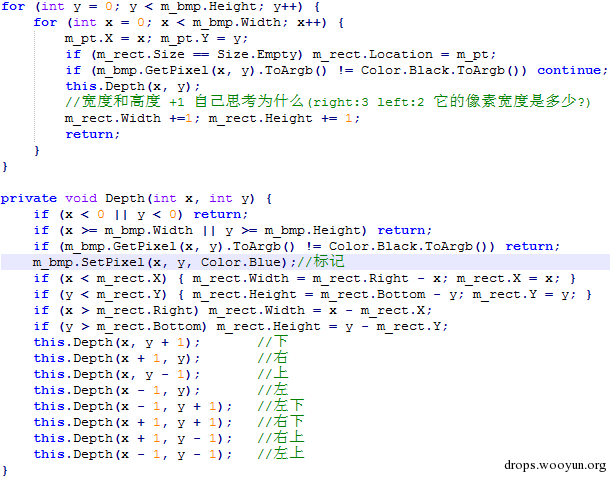
对于拆字还有很多其他的方式 这里只是最普通的也是最简单的一种 对于其他方式这个工具中并没有提供 因为工具只针对简单通用的验证码 对于那种需要单独写代码的验证码不考虑 而且工具上功能附加太多也就变得复杂了 其实重点就是感觉有点付出和回报不成正比 而且对于那些流传的拆字理论知识 说起来确实简单 但是实际做的时候才会发现 这些理论其实是存在漏洞的 只会在特定条件下才会成立 而验证码却是变幻多端的 这里也就不扯那么多了
剩下来的就是识别了 我采用的识别方式比较简单 就是两张图来对比 一张是验证码上面截取出来的图像 一张是已知的样本图像
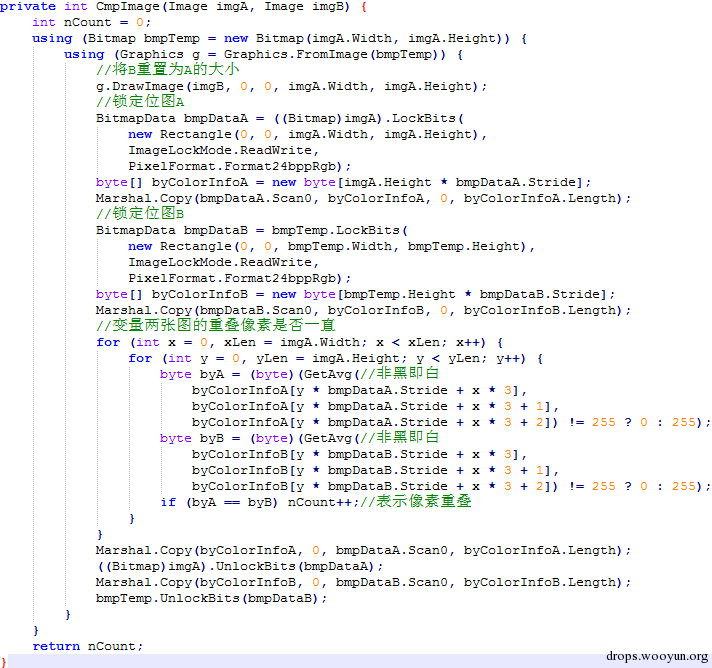
调用函数会返回这两张图的重叠的像素的个数 这样我把截取出来的验证码字符和我所有的样本对比一次 取出nCount最高的一个 作为结果 也就是说取出和样本中重叠率最高的一个出来作为结果 在工具中我有两种方式提供样本 一种是使用系统的字体 一种是手动采集
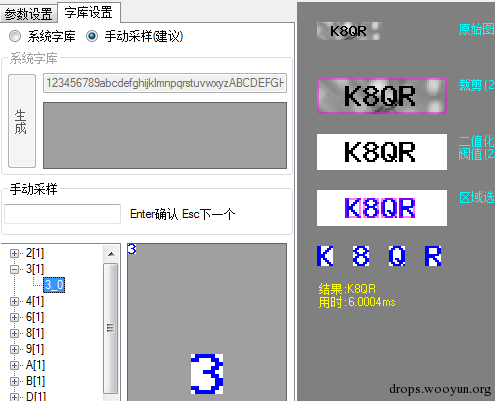
如果使用系统字体在文本框内输入验证码可能出现的字符 然后点击 生成 会弹出系统对话框设置字体从而产生样本 不过对于一些非标准字体 系统字体就很难搞定了 无论是标准字体还是非标准的字体都建议使用手动采集的方式 因为直接从验证码上截取下来的图怎么说也是原配 重复的图片工具也只会采集一次不会重复添加降低效率比对 下面就是一个非标准字体
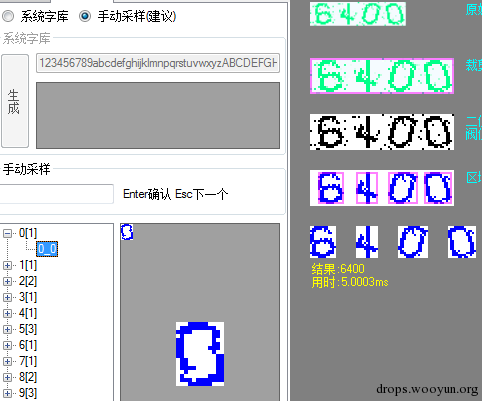
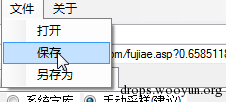
理论上来说 样本采集越多越全 识别率就越高 反正我每次都是使用的手动采集样本 对了这个工具只是一个配置工具而已 并不能用来做什么其他事情 当一切都配置好了之后就可以点击工具上的 文件 -> 保存 将这些所有的配置 保存成一个文件 可以保存为两种后最(.ci和.ci.png) 后者以图片保存方便电脑上查看
而识别是另一个独立的工具调用 如果是.NET则直接调用提供的dll来识别 之所以这样设计是因为 我并不知道别人 会用验证码识别来做什么事情 所以除了识别以外我也不知道别人想要什么功能 所以把所有东西全部独立出来共别人调用或者使用 对于识别我提供了一个命令行调用工具供给非.NET平台的程序调用

以python举例:
#!python # coding: UTF-8 import os result = os.popen('verifytool.exe D://woo.ci.png -f D://woo-verify.png').readlines() print (result) 在我的D盘有这样一张图

这样别人就可以自己写脚本去做自己爱做的事情 不过我还是建议使用 -p 的方式来调用
#!python # coding: UTF-8 import urllib2 from socket import * h = urllib2.urlopen('http://www.wooyun.org/captcha.php') str = h.read() #获取验证码 s = socket(AF_INET,SOCK_DGRAM); s.sendto(str,('localhost',14250)) #将获取到的验证码发送给识别程序 code = s.recvfrom(65500) #接受识别出来的验证码 print(code) 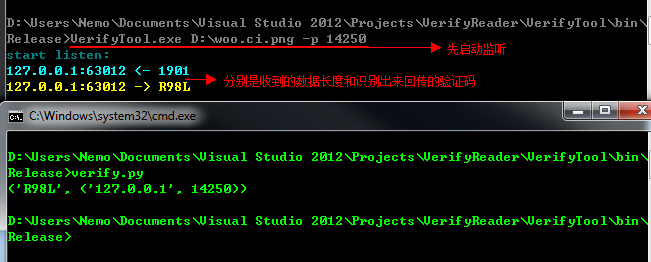
如果程序是.NET平台编写 则可直接使用VerifyReader.dll文件 将其添加引用然后:
#!vb CodeInfo ci = CodeInfo.LoadFromFile("D://woo.ci.png"); CodeHelper helper = new CodeHelper(ci); string code = helper.GetCodeString(Image.FromFile("D://woo-verify.png")); 另外这里还单独的做了一个账户爆破的工具出来
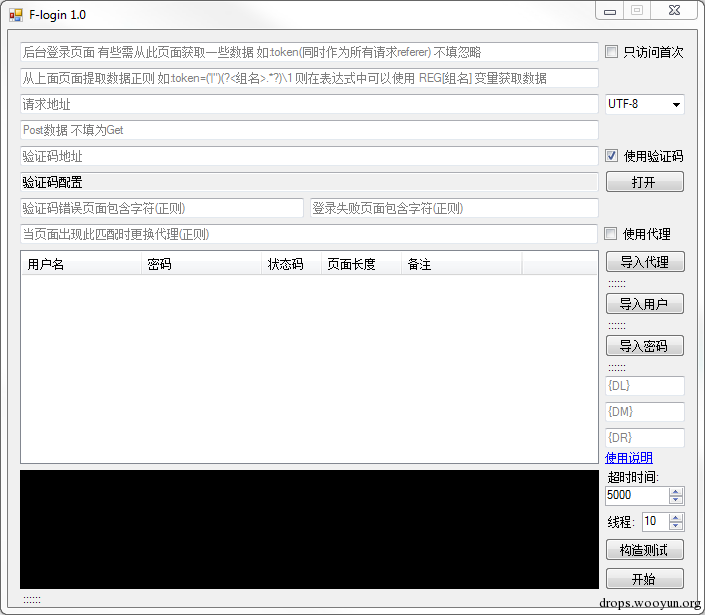
以下是用自己测试的结果
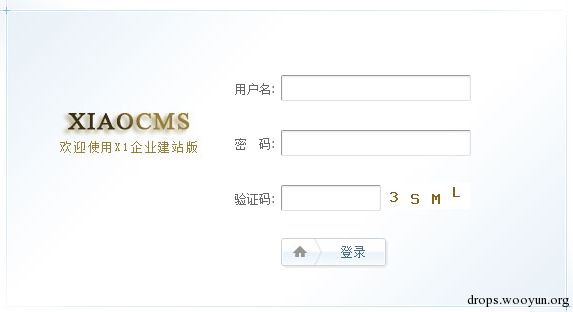

双击列表即可查看数据
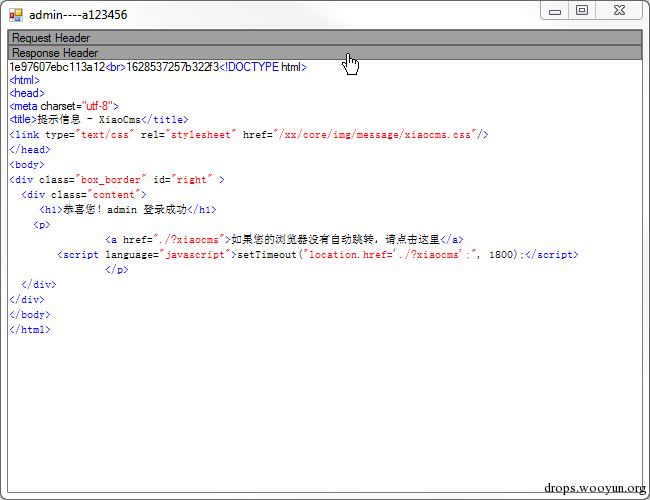
0x03 相关链接
全套工具及核心代码和使用说明下载连接: http://static.wooyun.org/drops/20160229/2016022903020853186VerifyReader.zip
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

