python爬虫学习(一)分析ajax请求
Introducation
Python爬虫学习目录
本文先从分析网页开始,了解要干的目标是什么。
以 https://www.gebiz.gov.sg/ 网站为例,使用chrome的开发者工具。
chrome开发者工具
F12打开chrome的开发者工具,我们关心的主要有这样几个列目:
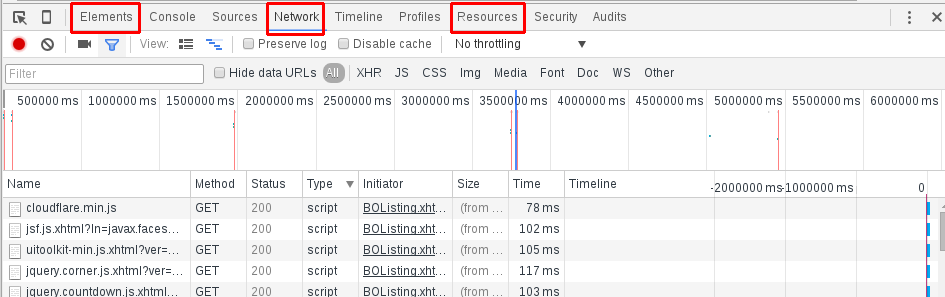
- Elements: 允许我们从浏览器的角度看页面,也就是说我们可以看到chrome渲染页面所需要的的HTML、CSS和DOM(Document Object Model)对象。此外,还可以编辑这些内容更改页面显示效果;
- Network: 可以看到页面向服务器请求了哪些资源、资源的大小以及加载资源花费的时间,当然也能看到哪些资源不能成功加载。此外,还可以查看HTTP的请求头,返回内容等;
- Resources: 对本地缓存(IndexedDB、Web SQL、Cookie、应用程序缓存、Web Storage)中的数据进行确认及编辑;
比如要抓取Opportunities,在点击opportunities之后,跳转到了一个详细的列表页面,期间,network自动更新,中间访问的页面包括js,css等等都列表在这里。
如果network标签页下面的栏目没有Method一列,则在Name上右键,把method勾中即可。可以看到每个元素都列出了get或者post方式。
而从Type一列可以看到请求到的文件类型,是script脚本、stylesheet css样式表还是document页面主文件等等。
查看post请求
要了解http的get和post请求,请参看文章
简易HttpServer(500行左右代码)
在opportunities页面,network下可以看到主页面的文件BOListing.xhtml。
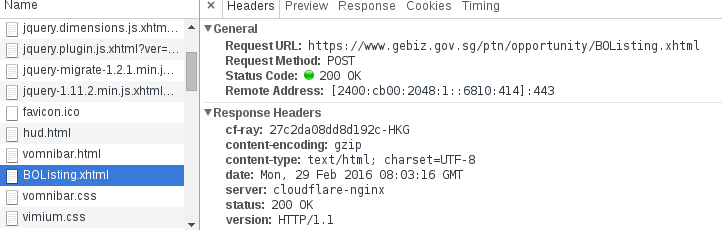
点击下一页以后,浏览器地址栏的网址并没有变,判定是javascript异步加载的网页,应该是ajax。
AJAX 是 Asynchronous JavaScript and XML(异步的 JavaScript 和 XML)的缩写。AJAX 通过使用原有的 web 标准组件,实现了在不重新加载整个页面的情况下,与服务器进行数据交互。例如在新浪微博中,你可以展开一条微博的评论,而不需要重新加载,或者打开一个新的页面。但是这些内容并不是一开始就在页面中的(这样页面就太大了),而是在你点击的时候被加载进来的。这就导致了你抓取这个页面的时候,并不能获得这些评论信息(因为你没有『展开』)。
AJAX 的一种常见用法是使用 AJAX 加载 JSON 数据,然后在浏览器端渲染。如果能直接抓取到 JSON 数据,会比 HTML 更容易解析。
AJAX 实际上也是通过 HTTP 传输数据的
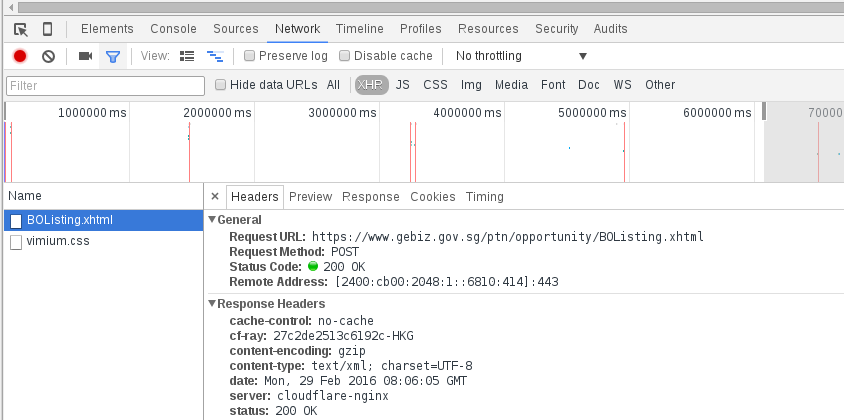
找到真实的请求
AJAX 一般是通过 XMLHttpRequest 对象接口发送请求的,XMLHttpRequest 一般被缩写为 XHR。点击网络面板上漏斗形的过滤按钮,过滤出 XHR 请求。挨个查看每个请求,通过访问路径和预览,找到包含信息的请求
Reference
pyspider 爬虫教程(二):AJAX 和 HTTP
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

