Linux内核分析:页回收导致的cpu load瞬间飙高的问题分析与思考
摘要
本文一是为了讨论在Linux系统出现问题时我们能够借助哪些工具去协助分析,二是讨论出现问题时大致的可能点以及思路,三是希望能给应用层开发团队介绍一些Linux内核机制从而选择更合适的使用策略。
前言
搜索团队的服务器前段时间频繁出现CPU load很高( 比如load average达到80多 )的情况,正所谓术业有专攻,搜索的兄弟们对Linux底层技术理解的不是很深入,所以这个问题困扰了他们一段时间。
相信我们在遇到问题时都有类似的经历,如果这个问题涉及到我们不熟悉的领域,我们往往会手足无措。
由于虚拟化团队具备一些Linux底层背景知识,所以在知晓了这个搜索团队遇到的困难后,就开始协助他们定位出问题根因并帮助他们解决了问题。
我希望能借助这个机会给大家介绍一下在Linux系统出现问题时我们能够借助哪些工具去协助分析;以及介绍一下Linux在内存管理方面的一些机制以及我们的使用策略。
Linux系统出现问题,我们该如何去分析
工欲善其事,必先利其器。要解决问题,首先得去定位问题的原因。在Linux系统里面有很多的问题定位工具,可以协助我们来分析问题。于是我们就针对目前搜索服务器的现象,思考可以借助哪些工具来找到问题原因。
Linux系统响应慢,从内核的角度看,大致可能有以下几种情况:
-
线程在内核态执行的时间过长,这个时间超出了它被调度算法给分配的执行时间,它在内核态长时间的占用CPU,而且也不返回用户态。
这种现象有个术语,叫做softlockup。
通过一个现象来简单说下内核态和用户态。我们可能遇到这个现象,执行完一个命令,CTRL+C怎么都杀不死它,而且敲键盘也反应,这可能就是因为此时这个进程正运行在内核态,CRTL+C是给进程发signal的方式通知进程,而进程只有在从内核态返回用户态的时候才会去检查有没有信号,所以如果它处在内核态的话显然是无法被杀死的。( 当然这种情况还可以是因为进程在代码里屏蔽掉了SIGQUIT信号 )这种现象就给我们系统很忙的感觉。
针对softlockup,内核里有一套检测机制,它提供给用户一个sysctl调试接口:kernel.softlockup_panc,我们可以将该值设置为1,这样在出现这种问题的时候,让内核主动的去panic,从而dump出来一些现场信息。
ps: 建议我们的服务器都使能该选项 -
CPU load值高,说明处于Running状态和D状态的线程太多。
线程等待资源而去睡眠,就会进入D状态( 即Disk sleep,深度睡眠 ),进入D状态的线程是不能够被打断的,他们会一直睡眠直到等待的资源被释放时主动去唤醒他们。( 大致的原理是,这些线程在等待什么资源,比如某个信号量,它就会被加入到这个信号量的等待队列里,然后其它的线程释放这个信号量的时候会去检查该信号量的等待队列,然后把队列里线程给唤醒。 )
D状态的线程可以通过“ps aux”命令来看,“D”即表示D状态:
root 732 0.0 0.0 0 0 ? S Oct28 0:00[scsi_eh_7]
root 804 0.0 0.0 0 0 ? D Oct28 5:52[jbd2/sda1-8]
root 805 0.0 0.0 0 0 ? S Oct28 0:00[ext4-dio-unwrit]
root 806 0.0 0.0 0 0 ? D Oct28 12:16[flush-8:0]
而正常的处于CPU调度队列上的线程,则是Sleep状态:
$ ps aux | grep "flush /| jbd"
root 796 0.0 0.0 0 0 ? S 2014 52:39 [jbd2/sda1-8]
root 1225 0.0 0.0 0 0 ? S 2014 108:38 [flush-8:0]
yafang 15030 0.0 0.0 103228 824 pts/0 S+ 0:00 grep flush|jbd
对于这种现象,内核也有个术语,叫做hung_task, 而且也有个监测机制。默认如果线程120S都处在D状态,内核就会打印出一个告警信息,这个时间是可以调整的。而且我们也可以让内核在出现这个状况时去panic。
ps:让内核panic的目的是为了在panic时dump出现场信息。 - 在内核态,出了进程上下文外,还有中断上下文,( PS:在我们用的2.6的内核上,中断仍然还是使用的内核栈,它没有自己独立的栈空间 )。中断也可能有异常,比如长时间被关中断。
中断长时间被关闭,这个现象叫做hardlockup。
针对hardlockup,内核也有监测机制,是NMI watchdog
。可以通过/proc/interrupts来看系统是否使能了NMI watchdog。
$ cat /proc/interrupts | grep NMINMI : 320993 264474 196631 16737 Non-maskable interrupts
值不为0,说明系统使能了NMI watchdog。然后我们通过sysctl将kernel.nmi_watchdog设置为1,即,在触发了NMI watchdog的时候主动让内核去panic。从而监测出hardlockup这种故障。
ps: 我们的服务器上NMI watchdog应该是都使能了 部署工具,搜集现场信息
我们部署了前面那些工具的目的是为了搜集故障现场信息,以此来帮我们找出root cause。Linux内核搜集故障现场信息的大杀器是kdump+kexec。
kdump的基本原理是,内核在启动时首先会预留一部分物理内存给crash kernel,在有panic时,会调用kexec直接启动crash kernel到该物理内存区域,由于是使用kexec启动,从而绕过了boot loader的一系列初始化,因而整个内存的其它区域不会被更改(即事故现场得以保留),然后新启动的这个kernel会dump出来所有的内存内容(这些内容可以裁剪),然后存储在磁盘上。
来看下我们的系统上是否启用了kdump。
$ cat /proc/cmdlinero root=UUID=1ad1b828-e9ac-4134-99ce-82268bc28887 rd_NO_LUKS rd_NO_LVM LANG=en_US.UTF-8 rd_NO_MD SYSFONT=latarcyrheb-sun16 crashkernel=133M@0M KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM rhgb quiet
内核启动参数"crashkernel=133M@0M"告诉我们系统已经启用了kdump。当然Crash kernel的地址空间并不是在0M的地方,而是:
$ cat /proc/iomem | grep Crash03000000-0b4fffff : Crash kernel
接着去看kdump内核服务是否已经开启:
$ sudo service kdump statusKdump is operational
说明已经开启了。kdump是通过/etc/kdump.conf来配置的,默认它会把抓取到的内核现场信息(即vmcore)给生成到/var/crash目录下,通过crash这个命令来分析该vmcore。
ps: 建议我们的所有服务器都配置好kdump 抓取现场信息:CPU到底在干什么
在有一天的早晨,刚来到办公室后( bug出现的时间点还挺人性化 ),一台服务器出现了load高的告警信息。然后尝试去登录上去,很慢,还是登录了进去;再尝试敲命令,非常非常慢,不过还是响应了。
用 perf top 观察到很多线程都是在spinlock或者spinlock_irq(关中断自旋)状态,( PS:原谅我没保存当时的图 )。看起来内核里面有死锁或者什么。
ps: perf是协助分析问题的一个有力工具,建议我们的服务器都装上perf 这个时候CPU到底在干什么?为此我们不得不祭出终极大杀招:使用sysrq让内核panic( 这个服务器的流量已经导走,所以可以重启 ),然后panic触发kdump来保存现场信息。( 还有个更终极的杀器:键盘的sysrq键+字母的组合,这可以应用于我们无法登录到服务器的情况, 可以借助于管理卡,然后使用键盘中断来触发信息的搜集。 )
ps: 建议我们的服务器上都配置好sysrq 首先sysrq得是使能的:
$ cat /proc/sys/kernel/sysrq1
然后让内核panic:
$ echo c > /proc/sysrq-triggger
于是就在/var/crash目录下获取到了vmcore。
#现场信息的分析过程
可以通过crash这个命令来分析vmcore,由于这个vmcore不是ELF格式,所以是不能用gdb之类的工具来分析的。
以下是对该vmcore的部分关键信息分析:
$ crash /usr/lib/debug/lib/modules/2.6.32-431.el6.x86_64/vmlinux vmcore crash> bt -a PID: 8400 TASK: ffff880ac686b500 CPU: 0 COMMAND: "crond" ... #6 [ffff88106ed1d668] _spin_lock at ffffffff8152a311 #7 [ffff88106ed1d670] shrink_inactive_list at ffffffff81139f80 <br> #8 [ffff88106ed1d820] shrink_mem_cgroup_zone at ffffffff8113a7ae #9 [ffff88106ed1d8f0] shrink_zone at ffffffff8113aa73 #10 [ffff88106ed1d960] zone_reclaim at ffffffff8113b661 ... PID: 8355 TASK: ffff880e67cf2aa0 CPU: 12 COMMAND: "java" ... #6 [ffff88106ed49598] _spin_lock_irq at ffffffff8152a235 #7 [ffff88106ed495a0] shrink_inactive_list at ffffffff8113a0c5 #8 [ffff88106ed49750] shrink_mem_cgroup_zone at ffffffff8113a7ae #9 [ffff88106ed49820] shrink_zone at ffffffff8113aa73<br> #10 [ffff88106ed49890] zone_reclaim at ffffffff8113b661<br> ... PID: 4106 TASK: ffff880103f39540 CPU: 15 COMMAND: "sshd" #6 [ffff880103e713b8] _spin_lock at ffffffff8152a311 #7 [ffff880103e713c0] shrink_inactive_list at ffffffff81139f80 #8 [ffff880103e71570] shrink_mem_cgroup_zone at ffffffff8113a7ae #9 [ffff880103e71640] shrink_zone at ffffffff8113aa73 #10 [ffff880103e716b0] zone_reclaim at ffffffff8113b661 ... PID: 19615 TASK: ffff880ed279e080 CPU: 16 COMMAND: "dnsmasq" ... #6 [ffff880ac68195a8] shrink_inactive_list at ffffffff81139daf #7 [ffff880ac6819750] shrink_mem_cgroup_zone at ffffffff8113a7ae #8 [ffff880ac6819820] shrink_zone at ffffffff8113aa73 #9 [ffff880ac6819890] zone_reclaim at ffffffff8113b661 ... PID: 8356 TASK: ffff880ed267c040 CPU: 17 COMMAND: "java" #6 [ffff88106ed4b5d8] _spin_lock at ffffffff8152a30e #7 [ffff88106ed4b5e0] shrink_inactive_list at ffffffff81139f80 #8 [ffff88106ed4b790] shrink_mem_cgroup_zone at ffffffff8113a7ae #9 [ffff88106ed4b860] shrink_zone at ffffffff8113aa73 #10 [ffff88106ed4b8d0] zone_reclaim at ffffffff8113b661 ... 大致的意思就是,现在所有需要allocate memory的线程,都得调用zone_reclaim去inactive_list上去回收pagecache,这个行为也就是所谓的direct reclaim。
简要的汇总信息如下:
总共有24个CPU,我们看下每个CPU此时的状态
| CPU | 跑的程序 | 正在运行的函数 |
| 0 | crond | _spin_lock(&zone->lru_lock) |
| 1 | bash | _spin_lock(&zone->lru_lock) |
| 2 | crond | _spin_lock(&zone->lru_lock) |
| 3 | bash | _spin_lock(&zone->lru_lock) |
| 4 | swapper | idle |
| 5 | java | _spin_lock(&zone->lru_lock) |
| 6 | bash | sysrq |
| 7 | crond | _spin_lock(&zone->lru_lock) |
| 8 | swapper | idle |
| 9 | swapper | idle |
| 10 | swapper | idle |
| 11 | swapper | idle |
| 12 | java | _spin_lock(&zone->lru_lock) |
| 13 | sh | _spin_lock(&zone->lru_lock) |
| 14 | bash | _spin_lock(&zone->lru_lock) |
| 15 | sshd | _spin_lock(&zone->lru_lock) |
| 16 | dnsmasq | shrink_inactive_list |
| 17 | java | _spin_lock(&zone->lru_lock) |
| 18 | lldpd | _spin_lock_irq(&zone->lru_lock) |
| 19 | swapper | idle |
| 20 | sendmail | _spin_lock(&zone->lru_lock) |
| 21 | swapper | idle |
| 22 | swapper | idle |
| 23 | swapper | idle |
从这个表格我们可以看到,所有申请内存的线程都在等待zone->lru_lock这把自旋锁,而这把自旋锁现在被CPU16上的dnsmasq这个线程持有,它现在正卖力的回收pagecache到freelist。于是从这个zone里来申请内存的线程都得在这里等待着,于是load值就高了上来。外在的表现就是,系统反映好慢啊,ssh都登不进去(因为ssh也会申请内存);即使登录进去了,敲命令也没有反应(因为这些命令也都是需要申请内存的)。
背后的知识
page cache
导致这个情况的原因是:线程在申请内存的时候,发现该zone的freelist上已经没有足够的内存可用,所以不得不去从该zone的LRU链表里回收inactive的page,这种情况就是direct reclaim(直接回收)。direct reclaim会比较消耗时间的原因是,它在回收的时候不会去区分dirty page和clean page,如果回收的是dirty page,就会触发磁盘IO的操作,它会首先把dirty page里面的内容给刷写到磁盘,再去把该page给放到freelist里。
我们先用一张图来看下memory,page cache,Disk I/O的关系。

举个简单的例子,比如我们open一个文件时,如果没有使用O_DIRECT这个flag,那就是File I/O, 所有对磁盘文件的访问都要经过内存,内存会把这部分数据给缓存起来;但是如果使用了O_DIRECT这个flag,那就是Direct I/O, 它会绕过内存而去直接访问磁盘,访问的这部分数据也不会被缓存起来,自然性能上会降低很多。
page reclaim
在直观上,我们有一个认知,我们现在读了一个文件,它会被缓存到内存里面,如果接下来的一个月我们一直都不会再次访问它,而且我们这一个月都不会关闭或者重启机器,那么在这一个月之后该文件就不应该再在内存里头了。这就是内核对page cache的管理策略:LRU( 最近最少使用 )。即把最近最少使用的page cache给回收为free pages。
内核的页回收机制有两种:后台回收和直接回收。
后台回收是有一个内核线程kswapd来做的,当内存里free的pages低于一个水位(page_low)时,就会唤醒该内核线程,然后它从LRU链表里回收page cache到内存的free_list里头,它会一直回收直至free的pages达到另外一个水位page_high. 如下图所示,
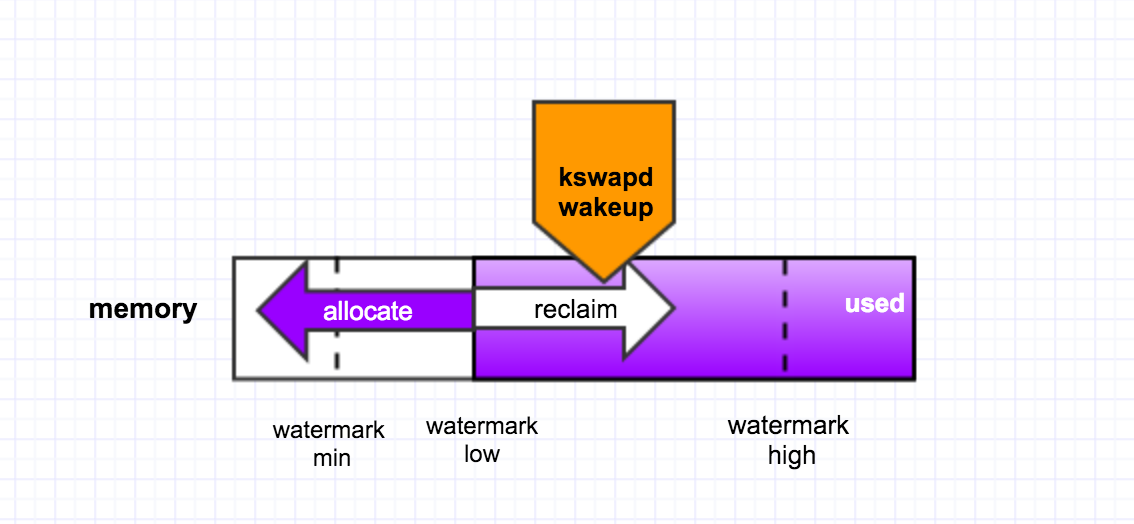
直接回收则是,在发生page fault时,没有足够可用的内存,于是线程就自己直接去回收内存,它一次性的会回收32个pages。逻辑过程如下图所示,

所以说,我们应该要避免做direct reclaim。
memory zone
对于多核NUMA系统而言,内存是分节点的,不同的CPU对不同的内存节点的访问速度是不一样的,所以CPU会优先去访问靠近自己的内存节点( 即速度相对快的内存区域 )。
CPU内部是依靠MMU来进行内存管理的,根据内存属性的不同,MMU将一个内存节点内部又划分了不同的zone。对64-bit系统而言( 即我们现在使用的系统 ),一个内存节点包含三个zone:Normal,DMA,DMA32. 对32-bit系统而言,一个内存节点则是包括:Normal,Highmem,DMA。Highmem存在的目的是为了解决线性地址空间不够用的问题,在64-bit上由于有足够的线性地址空间所以就没了该zone。
不同zone存在的目的是基于数据的局部性原则,我们在写代码的时候也知道,把相关的数据给放在一起可以提高性能,memory zone也是这个道理。于是MMU在分配内存时,也会尽量给同一个进程分配同一个zone的内存。凡事有利就有弊,这样有好处自然也可能会带来一些坏处。
root cause知道了:解决问题
为了避免direct reclaim,我们得保证在进程申请内存时有足够可用的free pages,从前面的背景知识我们可以看出,提高watermark low可以尽早的唤醒kswapd,然后kswapd来做background reclaim。为此,内核专门提供了一个sysctl接口给用户来使用:vm.extra_free_kbytes.
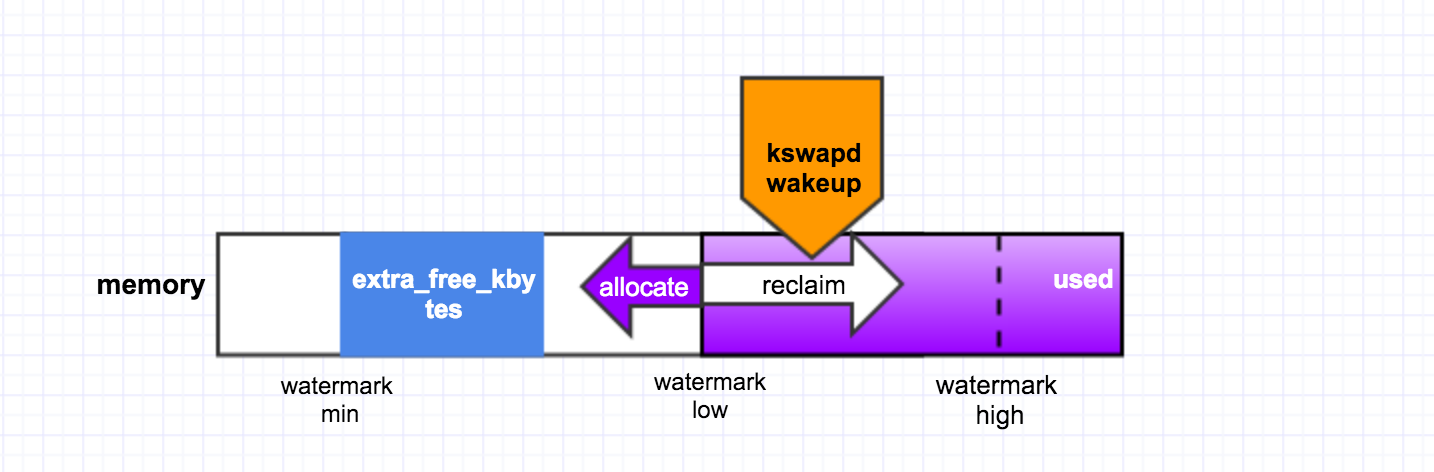
于是我们增大这个值(比如增大到5G,hohoho),确实也解决了问题。增大该值来提高low水位,这样在申请内存的时候,如果free的内存低于了该水位,就会唤醒kswapd去做页回收,同时又由于还有足够的free内存可用所以进程能够正常申请而不触发直接回收。
PS: extra_free_kbytes是CentOS-6(kernel-2.6.32导出的一个接口), 该接口并未合入内核主线,它是redhat自己合入的一个patch。 在CentOS-7(kernel-3.10)上删除了该接口,转而使用dirty ratio来触发, 因为直接回收耗时长的直接原因就是因为回收的时候会去回收dirty page, 所以CentOS-7的这种做法更加合理一些, extra_free_kbytes在某种程度上也浪费了一些内存的使用。 但是,这还不够。我们从前面dump出来的内核alltrace也可以看出,线程的回收跟memory zone相关。也就是说normal zone里面的free pages不够用了,于是触发了direct reclaim。但是,假如此时DMA zone里还有足够的free pages呢?线程会不会从DMA zone里来申请内存呢?
继续来看另外一个问题
就在解决了这个问题没几天后,搜索的solr服务器又遇到一个类似的问题,只不过这个问题跟前面那个问题有一点不一样的地方.先来看下它的free memory:
$ free -m
total used free shared buffers cached
Mem: 64391 62805 1586 0 230 27665
-/+ buffers/cache: 34909 29482
swap: 15999 0 15999
我们可以看到,此时它的free pages还是挺多的,有1G多。
再来看下它有多少个dirty pages:
$ cat /proc/vmstat
nr_free_pages 422123
nr_inactive_anon 1039139
nr_active_anon 7414340
nr_inactive_file 3827150
nr_active_file 3295801
...
nr_dirty 4846
nr_writeback 0
...
同时它的dirty pages也很高,有4846个。
这跟前面的问题有一些不一样,前面的问题是free的pages很少同时dirty的pages很多,这里则是free的pages挺多而dirty的pages也很多。
这就是我们前面对memory zone的那个疑问。free的pages都在其它的zone里头,所以线程去回收自己zone的page cache而不去使用其它zone的free pages。对于这个内核也提供了一个接口给用户使用:vm.zone_reclaim_mode. 这个值在该机器上本来是1( 即宁肯回收自己zone的page cache,也不去申请其它zone的free pages ),我把它更改为0( 即只要其它zone有free pages就去其它zone里申请 ),就解决了该问题( 一设置后系统就恢复了正常 )。
将该值从1改为0后,效果是立竿见影:
$ free -m
total used free shared buffers cached
Mem: 64391 64062 329 0 233 28921
-/+ buffers/cache: 34907 29484
swap: 15999 0 15994
可以看到free的pages立马减少了,同时dirty pages也减少了(没人跟flush线程抢zone->lru_lock这把锁了,自然它脏页刷的也快了)。
总结&思考 :机制与策略
从前面我们讨论的这个问题也可以看出,Linux内核提供了各种各样的机制,然后我们根据具体的使用场景来选择使用的策略。我们的目的肯定是为了在不影响稳定性的前提下,尽可能的提升系统性能。然而如果真的是稳定性与性能二选一的话,毫无疑问我们要去选择稳定性。
Linux机制的多种多样,也给上层的开发者带来了一些苦恼:由于对底层了解的不深入,就很难选择出一个很好的策略来使用这些内核机制。
然而对这些机制的使用,也不会有一个万能公式,还是要看具体的使用场景。由于搜索服务器存在很多批量文件操作,所以对page cache的使用很频繁,所以我们才选择了尽早的能够触发background reclaim这个策略;而如果你的文件操作不频繁,显然就没有必要去尽早的唤醒后台回收线程。另外一个,作为一个文件服务器,它对page cache的需求是很大的,越多的内存作为page cache,系统的整体性能就会越好,所以我们就没有必要为了数据的局部性而预留DMA内存,两相比较肯定是page cache对性能的提升大于数据的局部性对性能的提升;而如果你的文件操作不多的话,那还是打开zone_reclaim的。
作为一个底层开发人员,我希望能给应用层开发团队建议合理的内核使用策略。所以很欢迎应用开发团队在遇到底层的困惑后能够跟我们一起讨论,这样我也能够了解应用层的实现,从而能够给出更合理的建议。
欢迎大家与我交流各种Linux问题。 --@亚方 正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

