利用cache特性检测Android模拟器
Author: leonnewton
0x00 序
目前对Android模拟器的检测,主要是从特定的系统值来进行区分的。例如,getDeviceId()、getLine1Number()这类函数,还有android.os.Build类记录的一系列值等等。但是偶然发现有位 老外 提出了用cache来区分模拟器和真机的idea,但是这位老外可能当时比较懒,没有具体的细节,写了个简单的PoC后把Evaluation空着了,也没有实验,所以并不知道这个方法是否真的有效。因此,本文就把检测的整个方法从原理到实现完整地展现出来。
0x01 ARM和x86
由于现在大部分的Android手机都是ARM架构的,因此首先看一下ARM架构和x86架构在cache上的区别。两者简明的区别如下图所示。

图1:ARM和x86 cache区别
从图中我们可以看出,在CPU和内存之间,可以存在几级cache,这里是L1和L2。cache的作用是加速,把指令缓存起来,就不用到低速的内存中去取了。x86的cache都是连续的,但是ARM把L1 cache分成了平行的2块,也就是I-Cache和D-Cache。这种将程序指令储存和数据储存分开的存储器结构叫哈佛架构( Harvard architecture ),而把程序指令存储器和数据存储器合并在一起的叫冯·诺伊曼结构( von Neumann architecture )。
那么问题就来了,在指令和数据分开存储的结构中,这两个cache不是同步的,因此一个特定地址的数据值在一个cache中更新了,但是在另一个cache就没有更新。比如往数据cache中写了数据,指令cache中是不会写入这个数据的。
而目前Android SDK提供的模拟器是基于QEMU的,QEMU是一个开源的模拟处理器的软件,详细可以看维基 QEMU 。所以模拟器是没有分开的cache,模拟器只有一个整块的cache。
于是就有了下面利用cache来检测模拟器的思路。
0x02 思路
先看下思路的流程图:
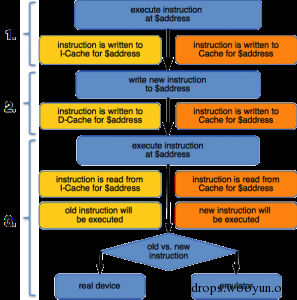
图2:检测思路
左边的是真机上发生的情况,右边是模拟器发生的情况,下面详述一下操作和后果。
第一步:
执行一个地址上的指令,假设就是 $address 这个地址。那么在真机上,指令会写到I-Cache上,模拟器直接写到cache上(因为模拟器就一个整块的cache)。
第二步:
向 $address 写入一个新指令。注意,这就有区别了,真机上的新指令会写入D-Cache,而在模拟器直接写到cache上。
第三步:
执行 $address 的指令。那么此时,在真机上,会从I-Cache读指令,也就是会执行第一步的指令。模拟器直接从cache上读指令,会执行第二步的新指令。
当然有可能发生在真机上的指令cache被洗掉了,但是实验下来可能性还是比较小的。
0x03 show me the code
首先是设计一段代码,会向一个特定的地址重新写一个指令。然后由于要重新回到原来的地址再执行一遍,因此可以用一个循环来实现。代码如下:
#!cpp __asm __volatile ( 1 "stmfd sp!,{r4-r8,lr}/n" 2 "mov r6,#0/n" 用来统计循环次数,debug用的 3 "mov r7,#0/n" 为r7赋初值 4 "mov r8,pc/n" 4、7行用来获得覆盖$address“新指令”的地址 5 "mov r4,#0/n" 为r4赋初值 6 "add r7,#1/n" 用来覆盖$address的“新指令” 7 "ldr r5,[r8]/n" 8 "code:/n" 9 "add r4,#1/n" 这就是$address,是对r4加1 10 "mov r8,pc/n" 10,11,12行的作用就是把第6行的指令写到第9行 11 "sub r8,#12/n" 12 "str r5,[r8]/n" 13 "add r6,#1/n" r6用来计数 14 "cmp r4,#10/n" 控制循环次数 15 "bge out/n" 16 "cmp r7,#10/n" 控制循环次数 17 "bge out/n" 18 "b code/n" 10次内的循环调回去 19 "out:/n" 20 "mov r0,r4/n" 把r4的值作为返回值 21 "ldmfd sp!,{r4-r8,pc}/n" ); 注释已经解释得比较清晰了。也就是说,r4如果是10,那么就是执行的是旧指令,是在真机上。如果r4等于1,那就是执行了旧指令,是在模拟器上。
这里会遇到一个问题,就是我们是没有写代码段的权限的,解决方案是mmap一段可写的,把编译好的机器码复制进去,再跳过去执行。
#!cpp void (*call)(void); #define PROT PROT_EXEC|PROT_WRITE|PROT_READ #define FLAGS MAP_ANONYMOUS| MAP_FIXED |MAP_SHARED char code[]= "/xF0/x41/x2D/xE9/x00/x60/xA0/xE3/x00/x70/xA0/xE3/x0F/x80/xA0/xE1" "/x00/x40/xA0/xE3/x01/x70/x87/xE2/x00/x50/x98/xE5/x01/x40/x84/xE2" "/x0F/x80/xA0/xE1/x0C/x80/x48/xE2/x00/x50/x88/xE5/x01/x60/x86/xE2" "/x0A/x00/x54/xE3/x02/x00/x00/xAA/x0A/x00/x57/xE3/x00/x00/x00/xAA" "/xF5/xFF/xFF/xEA/x04/x00/xA0/xE1/xF0/x81/xBD/xE8"; void *exec = mmap((void*)0x10000000,(size_t)4096 ,PROT ,FLAGS,-1,(off_t)0); memcpy(exec ,code,sizeof(code)+1); call=(void*)0x10000000; call(); 申请了一段内存,然后把汇编代码的机器码复制过去,接着跳到这块内存执行。然后我们在后面取r4的值即可。
#!cpp __asm __volatile ( "mov %0,r0/n" :"=r"(a) : : ); 把r0,也就是r4的值放到a变量中。然后根据a的值返回不同的值就可以了。方便在应用里判断结果。
0x04 调试
调试的方法可以见郑博士的文章 安卓动态调试七种武器之孔雀翎 – Ida Pro 。
整个调试的过程是,把上一节的代码编译成一个so共享库,返回值是r0也就是r4的值(a变量),然后在应用中根据返回值来判断在什么环境中运行。
在进入10000000前下断点,然后F7进去。
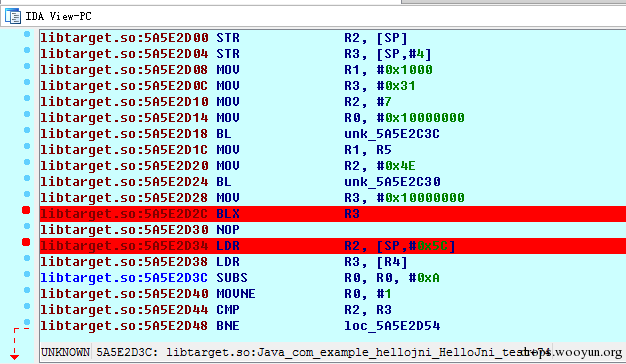
进入以后,在mov r0,r4的时候下断,F9执行,这时候看到r4的值是10,这是在真机上测试的结果。可以看到原先add r4,#1 已经变成了add r7,#1,但是实际执行的还是add r4,#1。
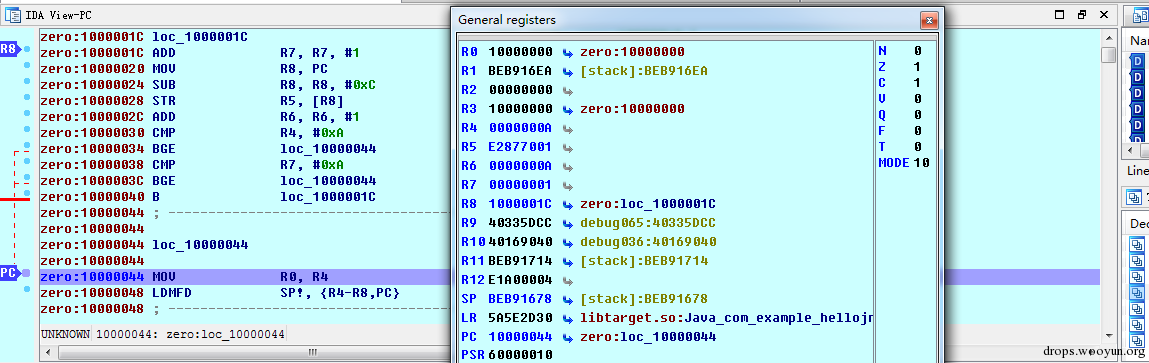

在模拟器执行的结果如下,可以看到r4的值是1,r7是10,所以执行的是新指令,是在模拟器上:

0x05 测试
不知道在其他机器上是否可行,大家可以从 https://github.com/leonnewton/cache_test 下载进行测试。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

