【Python】爬虫+ K-means 聚类分析电影海报主色调
每部电影都有自己的海报,即便是在如今这互联网时代,电影海报仍是一个强大的广告形式。每部电影都会根据自身的主题风格设计海报,精致的电影海报可以吸引人们的注意力。那么问题来了,不同风格的电影海报对颜色有什么样的偏好呢?
利用 Python 爬取海报数据
为了回答这个问题,我们需要分析不同风格电影的海报情况。首先,我们需要构建一个电影海报数据的数据集,因此我利用 Bing 图像搜索引擎来获取海报数据。

接下来我利用 Python 从网页中抓取电影海报数据并将其储存到本地电脑中,最终我得到四种电影类型(惊悚片、喜剧、动画片和动作片)的112张海报数据。
from bs4 import BeautifulSoup import requests import re import urllib2 import os import numpy as np def get_soup(url): return BeautifulSoup(requests.get(url).text) image_type = "action movies" query = "movie 2014 action movies poster" url = "http://global.bing.com/images/search?q=" + query + "&qft=+filterui:imagesize-large&FORM=R5IR5" soup = get_soup(url) images = [a['src'] for a in soup.find_all("img", {"src": re.compile("mm.bing.net")})] for img in images: raw_img = urllib2.urlopen(img).read() cntr = len([i for i in os.listdir("images") if image_type in i]) + 1 f = open("images/" + image_type + "_" + str(cntr), "wb") f.write(raw_img) f.close() 其中部分海报数据如下图所示:

图像格式转换
为了提取海报的颜色信息,我们需要将图像转换为 RGB 像素矩阵。比如,对于 200*200 像素的图片,我们需要将其转换成含有 40000 个像素信息的对象。同时为了保持数据集的大小,我将图像的大小统一设定为 200*200。
def get_points(img): points = [] w, h = img.size for count, color in img.getcolors(w * h): points.append(Point(color, 3, count)) return points rtoh = lambda rgb: '#%s' % ''.join(('%02x' % p for p in rgb)) 提取颜色信息
接下来我利用 K 均值算法和颜色信息将海报分成许多不同的类别。我尝试了 k=3 , k=5 和 k=10 三种模型,但由于大多数海报通常都具有黑色的字体和边框,所以前两种模型无法获取海报中的主要颜色信息。最终我选择 k=10 的模型,并利用该算法处理 112 张海报,得到了 1120 种颜色信息。
部分结果如下图所示:

从下图中我们可以看出,K 均值算法存在一些不足之处:该算法对初始值非常敏感,这会产生一些不想要的结果。在这张海报中,该算法无法获取金色或橘黄色的信息。

3D 散点图
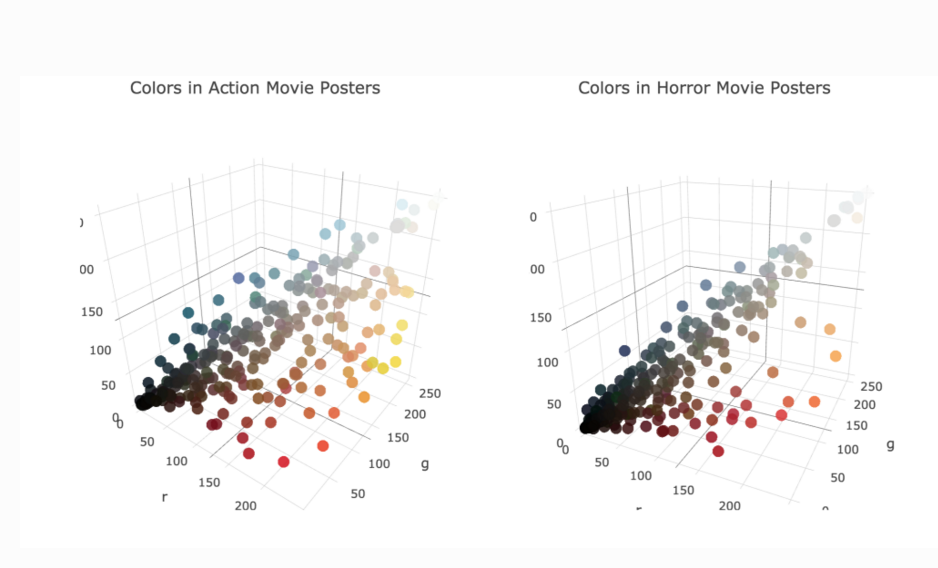
对每一类型的电影,我根据海报的 RGB 数据绘制三维散点图,其中每个点代表海报的一个颜色。通过比较四张散点图我们可以发现大多数惊悚片的海报中都有暗黑色和红色,而喜剧和动画片则会根据不同的电影主题选择不同的配色。
喜剧 VS. 动画片

动作片 VS. 惊悚片
转换颜色信息
由于我们很难从 1120 种颜色中提取一些特定的模式,因此我们需要降低颜色的维度。我们可以将颜色信息转换到 Lab 色彩空间中,然后利用 Python 中的 Delta E equations 和 colormath 包来计算海报中的颜色和基础颜色之间的视觉差异程度。
我通过最小距离法将这些颜色分成 17 类。下表是喜剧电影海报数据的部分数据:

电影类型对比
转换数据后,我计算出每个电影类型中所包含的基本色数量。

从上图中我们可以发现黑色、灰色和白色是电影海报中最常见的三种颜色。这是因为基本色的数量太少了,而大多数电影海报都有黑色的标题和边框。
原文链接: http://blog.nycdatascience.com/students-work/using-python-and-k-means-to-find-the-colors-in-movie-posters/
原文作者:Amy
译者:Fibears
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

