SparkES 多维分析引擎设计
设计动机
ElasticSearch 毫秒级的查询响应时间还是很惊艳的。其优点有:
- 优秀的全文检索能力
- 高效的列式存储与查询能力
- 数据分布式存储(Shard 分片)
其列式存储可以有效的支持高效的聚合类查询,譬如groupBy等操作,分布式存储则提升了处理的数据规模。
相应的也存在一些缺点:
- 缺乏优秀的SQL支持
- 缺乏水平扩展的Reduce(Merge)能力,现阶段的实现局限在单机
- JSON格式的查询语言,缺乏编程能力,难以实现非常复杂的数据加工,自定义函数(类似Hive的UDF等)
Spark 作为一个计算引擎,可以克服ES存在的这些缺点:
- 良好的SQL支持
- 强大的计算引擎,可以进行分布式Reduce
- 支持自定义编程(采用原生API或者编写UDF等函数对SQL做增强)
所以在构建即席多维查询系统时,Spark 可以和ES取得良好的互补效果。通过ES的列式存储特性,我们可以非常快的过滤出数据,并且支持全文检索,之后这些过滤后的数据从各个Shard 进入Spark,Spark分布式的进行Reduce/Merge操作,并且做一些更高层的工作,最后输出给用户。
通常而言,结构化的数据结构可以有效提升数据的查询速度,但是会对数据的构建产生一定的吞吐影响。ES强大的Query能力取决于数据结构化的存储(索引文件),为了解决这个问题,我们可以通过Spark Streaming有效的对接各个数据源(Kafka/文件系统)等,将数据规范化后批量导入到ES的各个Shard。Spark Streaming 基于以下两点可以实现为ES快速导入数据。
- Spark RDD 的Partition 能够良好的契合ES的Shard的概念。能够实现一一对应。避免经过ES的二次分发
- Spark Streaming 批处理的模式 和 Lucene(ES的底层存储引擎)的Segment对应的非常好。一次批处理意味着新生成一个文件,
我们可以有效的控制生成文件的大小,频度等。
架构设计
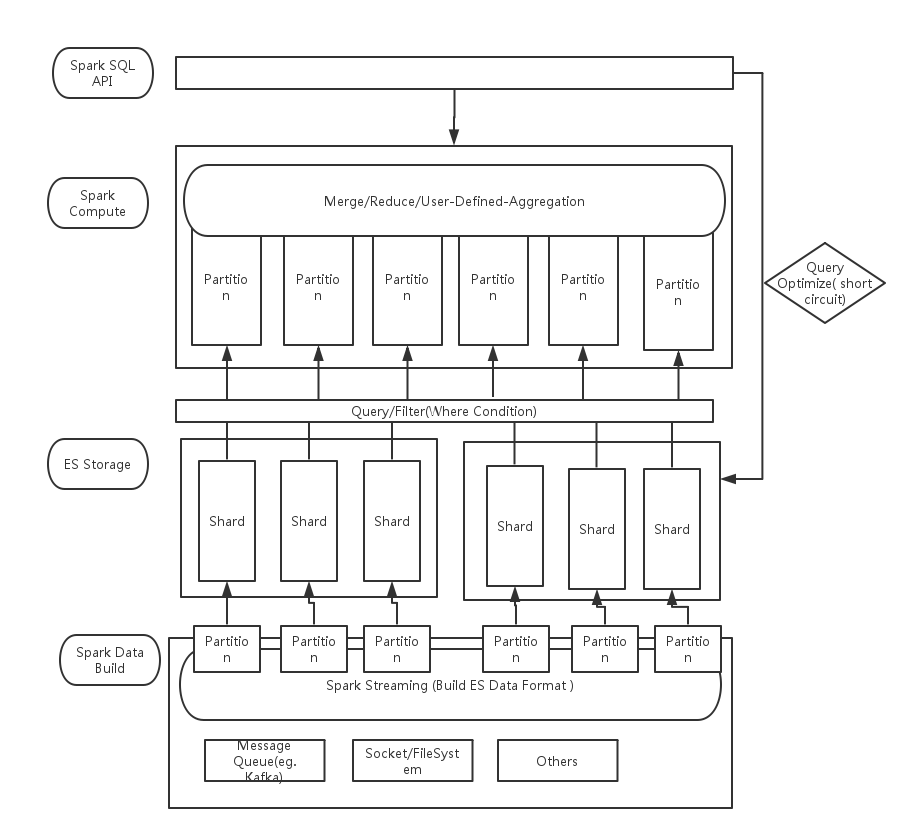
下面是架构设计图:
spark-es-4.png
整个系统大概分成四个部分。分别是:
- API层
- Spark 计算引擎层
- ES 存储层
- ES 索引构建层
API 层
API 层主要是做多查询协议的支持,比如可以支持SQL,JSON等形态的查询语句。并且可是做一些启发式查询优化。从而决定将查询请求是直接转发给后端的ES来完成,还是走Spark 计算引擎。也就是上图提到的 Query Optimize,根据条件决定是否需要短路掉 Spark Compute。
Spark 计算引擎层
前面我们提到了ES的三个缺陷,而Spark 可以有效的解决这个问题。对于一个普通的SQL语句,我们可以把 where 条件的语句,部分group 等相关的语句下沉到ES引擎进行执行,之后可能汇总了较多的数据,然后放到Spark中进行合并和加工,最后转发给用户。相对应的,Spark 的初始的RDD 类似和Kafka的对接,每个Kafka 的partition对应RDD的一个partiton,每个ES的Shard 也对应RDD的一个partition。
ES 存储层
ES的Shard 数量在索引构建时就需要确定,确定后无法进行更改。这样单个索引里的Shard 会越来越大从而影响单Shard的查询速度。但因为上层有了 Spark Compute层,所以我们可以通过添加Index的方式来扩大Shard的数目,然后查询时查询所有分片数据,由Spark完成数据的合并工作。
ES 索引构建层
数据的结构化必然带来了构建的困难。所以有了Spark Streaming层作为数据的构建层。这里你有两种选择:
- 通过ES原生的bulk API 完成索引的构建
- 然Spark 直接对接到 ES的每个Shard,直接针对该Shard 进行索引,可有效替身索引的吞吐量。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

