基于用户行为动态变化的内部威胁检测方法
*原创作者:木千之
写在前面
基于用户行为建模(Profile)的威胁检测方法早已不是个新事物,早在2008年的一篇综述中【1】作者就列举出了大量已有的主动检测的研究实例。
然而时至今日在现实的安全产业中依然很少见到成熟应用的内部威胁主动检测系统,其中一个最大的原因就是学界提出的检测方法误报率实在太高,虽然看上去貌似只有1%-2%,但是对于动辄上万的日常日志来说,安全管理员/审计管理员的工作负担相当巨大,结果造成了现在虽然组织中部署了审计系统,但是管理员对当天的警报基本不看的现状,不是不想看,是实在不知道看的目标,人力实在看不过来。所以误报率过高是制约主动检测实际应用的最大桎梏之一。
所以今天我们给大家介绍一个降低主动检测误报率的方法,该方法考虑了用户行为的变化,从而建立了一个动态的分类器。
Outline
1. 引言
2. 动态分类器
3. 内部威胁检测:非序列数据
4. 内部威胁检测:序列数据
5. Hadoop/Mapreduce应用
6. 结语
7. 参考文献
一、引言
基于主动检测的内部威胁应对系统误报主要来自于将用户正常、合理的行为判断成了异常行为,这里异常的比较标准是通过训练集学习到的用户行为模式。传统地研究聚焦于提取、选择更好的行为特征和分类算法来提高检测准确率,降低误报率;今天我们将焦点放在判定标准上,即事先通过学习得到的用户行为模式。
传统地研究都忽视了一个问题:用户自身的行为也会随着时间而改变,而且是合理地改变。当我们将用户的行为数据看作是一个巨大时间窗口下的数据流时,就会发现这种显著的变化。更加详细的内容我们在下一个部分介绍。
我们今天主要从用户行为改变的角度来构建适应动态变化的分类器,根据使用数据集的不同,分别针对非序列数据和序列数据进行分析,最后将分析任务部署在基于Hadoop/Mapreduce的分布式处理框架中。
二、动态分类器
引言中我们已经提到,将用户的数据看作随时间变化的数据流时,就会发现用户行为自然地改变。这种改变也许来自用户自身计算机使用习惯的改变(如每天一上班就要先看新闻/查看邮件),也有可能来自于组织工作流程的改变(如审批流程地变化),无论如何,随着时间的前进,用户自身的行为不可能一成不变,合理地变化如果不纳入检测系统的考虑,必然导致误报和漏报。
为了形象地说明用户行为的改变问题,我们给出图1进行说明:
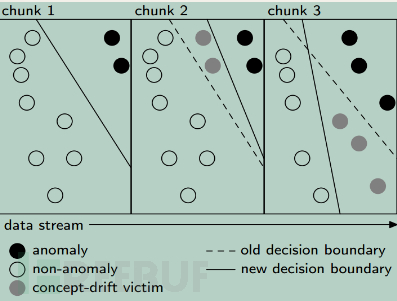
图1中详细表示了模式迁移对系统的影响,黑点表示异常,空白点表示正常,实现表示真实的异常/正常分界线,而虚线则表示传统地分类器划分的界限。
我们从中可以看到,数据块2相对于数据块1而言,真实的异常只有两个,而检测系统却识别出了4个,那么2个为误报(False Positive)。数据块3相对于1而言,异常为6个,但是检测系统却认为只有3个,即出现了漏报(False Negtive)。
为了应对上述问题,一种可行的解决方案是引入实时、自动更新的分类器,分类器可以根据用户的行为变化自动实现更新,为了达到这个目的,可以使用以下的框架,见图2:
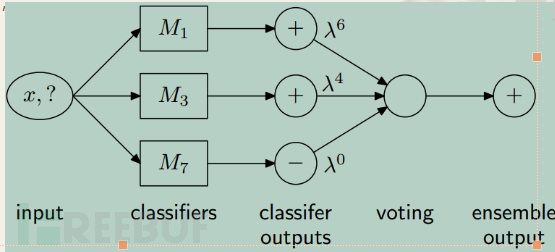
图2中所示的框架本质是一个K投票框架,即最终的判定结果是K个分类器结果的某种组合,每当分析完一个新的数据块(用户的某个时间窗口数据),就要启动一次全局K模型更新算法,利用单类支持向量机(OCSVM)或基于图分析的异常检测(GBAD)计算新的分类器,然后比较这K+1个分类器在最近的用户行为数据块上判断的准确率,淘汰最差的分类器,得到新的全局K模型。
具体的全局K模型更新算法伪代码如图3:

简要的说明下图3的意思:
1. Du是最近的一个标记的数据块(即正常/异常已知);
2. 针对现有全集K模型A中的每一个模型M,检验M模型对Du判定的准确性,即test(M, Du);
3. 利用单类SVM算法针对Du生成一个新的模型Mn;
4. 测试Mn对Du的判定是否正确,即test(Mn, Du);
5. 从{Mn U A}中丢弃判定错误的模型,得到更新后的全集K模型A’。
如此一来,我们便实现了全局K模型的动态实时自动更新。接下来,需要针对不同的数据采取不同的分类算法。
三、内部威胁检测:非序列数据
1. 非序列数据
我们这里的非序列数据与著名的1998年林肯实验室的入侵检测数据集,即著名的KDD99同源,都来自于MIT’98数据集。该数据集已经多次被作为入侵检测领域的研究。其中TCPDUMP获得的KDD99的数据就呈现出非序列形式,表现出一个特征向量。具体如图4:
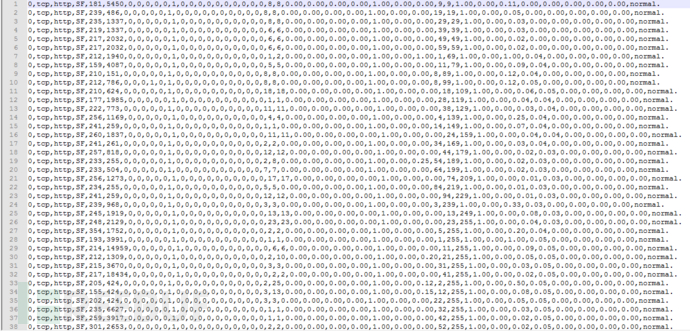
其中每个维度都有自己的意义,如第一位表示连接持续时间,第二位表示协议类型,第三位表示目标主机的网络服务类型等。
KDD99数据下载可以 参考链接 。
KDD99更多详细的分析可以 参考链接 。
MIT’98数据集的分类:
图17:
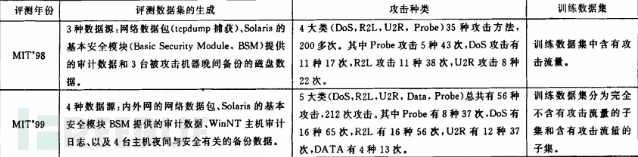
MIT’98中BSM(Basic Security Model,基本安全模型)的数据为Header+Token的形式。其中Header在Token之前,记录Token的大小、版本号、涉及的系统调用名称以及执行时间。实验所使用的即MIT‘98数据集中的BSM部分。
一个进一步处理后的Header+Token可以参考图5:
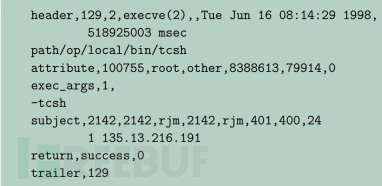
其中第二行记录命令执行的完整路径,Attribute行记录用户属组以及文件系统节点和设备信息,Subject行记录审计ID,有效用户组ID,真实用户和组ID、进程ID、会话ID以及端口和地址;Return记录系统调用执行结果/返回值。最终使用的特征在此基础上分析得到,如图6:

2. 分类器
2.1 SVM
这里我们使用两类分类器,一类是监督式学习的SVM,另一类则是非监督式的GBAD。我们分别进行简要介绍。
支持向量机(SVM)是现在广泛使用的一种线性分类器,SVM通过将非线性数据映射到高维线性可分空间,然后计算最大分隔超平面。本实验使用的是基于核函数RBF(Radial-Based Function)的SVM,程序上采用LIBSVM实现。
SVM的更多介绍可 参见链接
2.2 GBAD
基于图的异常检测(Graph-based Anormaly Detection)主要通过分析图中的顶点与边的变化进行异常检测,具体地是顶点与边的修改、增加与删除三种变化。
我们首先计算一个图的规范子图,即寻找其具有最小描述长度的子图:
L(S,G) = DL(G | S) + DL(S) 其中G表示整个的图,S是要分析的子图,DL(G|S)是将G压缩到S后的描述长度,DL(S)是图S的描述长度,我们选择最终L(S,G)最小的子图。这里的最小描述长度(Minimal Description Length)是一个数学概念,具体可以 参考链接 。
我们绘制的图类似图7:
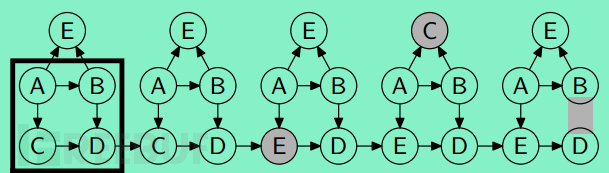
其中方框表示正常的子图,而阴影部分则表示异常,分别展示了顶点修改(异常点E)、顶点插入(异常点C)和边的修改(异常B-C)三种情况。
3. 实验
实验中先使用OCSVM检验使用全局K模型更新与传统的分类效果,如图8:

可以看到应用全局K模型后分类效果有很大改善误报率降低了近一半。
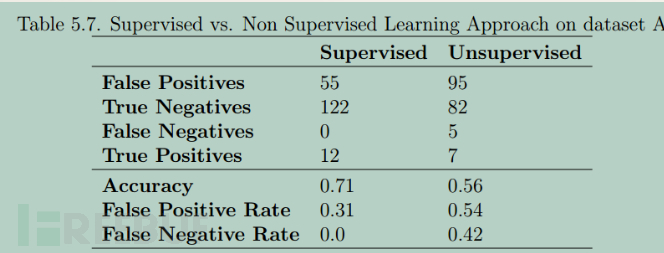
选择部分测试集的结果表明,监督式学习分类要好于非监督式学习,这是比较容易理解的,一般来说有老师的学习总是好于没有老师的自学的。如图9:
四、内部威胁检测:序列数据
上面介绍了非序列数据的分析方法,其实就是一般性的特征向量形式的数据分析。接下来我们来讨论下序列数据。所谓的序列数据,指的是元素的有序排列,可以允许重复。我们这里使用的是1988年Galgary大学的一个关于学生的项目,其中包含168个Unix用户的命令记录文件。一个典型的序列示例就像学生每天移动地点,如图10:

其中地点进行了简写,如ml = media lab等。
1. 分析方法
这里我们获得了用户的一些计算机使用命令行为数据,如图11:
我们通过分析用户使用命令的序列模式来建立分类器,具体地:
1. 先对用户的命令进行简写,如ls命令简写为l,cp命令简写为c,find命令简写为f,cpp命令简写为cp等;
2. 使用LZW算法构建每个用户的LZW字典,LZW算法全称为Lempel-ZivWelch Algorithm,用于遍历出所有的组合模式;
3. 对得到的LZW字典计算各个模式的权值,具体地使用每种模式的频率表示,如图12:
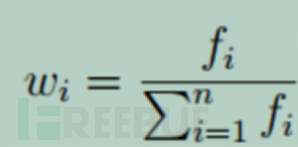
4. 筛选LZW字典,得到最具有代表性的组合,具体方式为对于每个模式而言,计算自身与其相邻的模式的“代表值”,该值等于模式长度与权值的乘积,即Vp = Length(Pattern) X Wi,不断重复,可以得到一个代表性字典;
5. 对于全局所有的时间窗口分别计算各自的代表性字典,对于窗口个数为N时,可以得到E = RD1, RD2, … RDn, RD = Representive Dictionary;
6. 若一个用户的命令模式偏离E中的RDi的比例达到30%,即判断为异常;
分析的架构间图13:
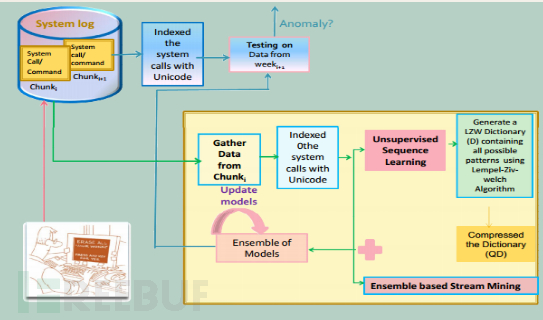
2. 实验结果
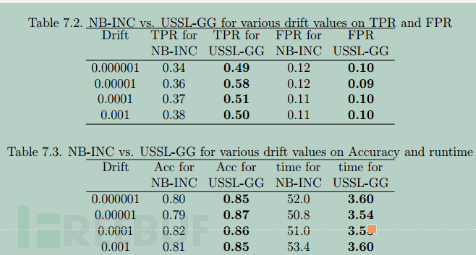
实验中与朴素贝叶斯分类器进行比较(Naive Bayes, NB),采用真实检测率与真实误报率作指标(True Positive Rate, False Positive Rate)。实验显示两项指标下LZW方法均优于NB方法。见图14:
五、Hadoop/Mapreduce应用
在序列数据分析时,需要构造LZW字典,但是对于用户的命令模式来说,工作量十分巨大,一般的服务器效率很低。因此考虑借助Hadoop/Mapreduce的分布式计算平台实现。具体地将计算分析任务采用Mapreduce模型编程,将任务在Hadoop平台上分布式运行。具体架构间图15:
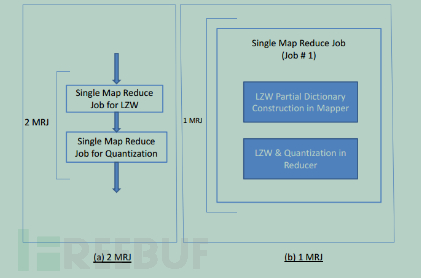
六、结语
传统的内部威胁检测研究聚焦于数据特征的提取与分类器构建,力图通过这两个方面的努力提升检测率,降低误报率。然而实际中使用时依旧误报率过高,以致无法在实际中有效推广。今天我们介绍的方法努力从整体思路上进行优化补全,将之前没有考虑到、但是却作用关键的用户行为自身的变化性纳入整体解决方案的设计之中,从而获得了传统检测框架的改进。
本文最关键的贡献自然是提出了 全局K模型 ,“全局”体现在该模型实现了实时自动更新,紧跟用户的行为而变化;“K模型”体现在其本质是一个 K投票 框架,即机器学习中的组合学习,多个分类器的某种组合。借助于全局K模型,本方法可以自动实时跟踪用户行为变化,不断更新分类器,使得分类器与现实的距离最小。
除了上面的工作,我们还对非序列数据和序列数据分别进行了分析。对于类似于KDD99这样的非序列数据而言,支持向量机SVM是一个不错的尝试,复杂度、准确率都较为满意,SVM也常常作为衡量其它算法的 标准算法 。借助于图论的知识进行异常检测并不是一个新话题,这里采用了最小描述距离作为构建规范子图的关键特征,然后从图的顶点与边的变化对用户行为进行刻画。
对于序列数据而言,今天我们直接从用户的命令模式入手,构建LZW字典来遍历出所有的命令模式,然后计算其中最有代表性的模式。如果考虑时间序列特征,那么也可以尝试使用Markov模型构建分类器。
最后,给出今天讨论的整体框架,如图16:

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

