变不可能为可能,Tachyon帮助Spark变小时级任务到秒
本文作者是Gianmario Spacagna和Harry Powell,Barclays的数据科学家。
集群计算和大数据技术已经取得了很多进展,不过现在很多大数据应用使用的还是HDFS这一分布式分件系统。HDFS是一个基于磁盘的文件系统,将数据存储在磁盘上有一些问题,比如说面临法律的监管,由磁盘读写造成的延迟也比较高。要避免这些问题可以将处理过的数据暂时放在内存中。Tachyon就可以帮你让这些数据长期处于内存中并且在不同应用之间共享。
在巴克莱我们并没有把数据存储在HDFS上,而是使用了RDMBS关系型数据库,而且我们还开发了一套让Spark从RDBMS直接读取数据的流程。我们作为读取数据的一方对于数据库的schema并不完全清楚,所以我们先读取为动态类型的Spark DataFrame,分析了数据结构和内容之后再转换为RDD。
这套流程有一个弊端。我们的数据集比较大,所以从RDBMS读取数据要花挺长时间。按理说我们不应该频繁地读取数据,但Spark缓存的数据一崩溃一重启就丢了。这时候就得重新读取数据一次,这么来一次我们的系统就得挂一半个小时,一天重读个几次也是很常见的。哪怕我们做完了数据的映射之后只要运行Spark job也还得重新读取数据,加入新特性,改模型,测试的时候都得这么干。
所以我们找到了Tachyon。Tachyon现在已经改名为Alluxio,它是一个数据存储层,它让所有的Spark应用可以直接通过文件API来读取数据。既方便与现有应用的集成也很简单。
现有架构的问题如前所述,最主要的问题就是数据的加载。虽然Spark有缓存功能,但当我们重启context,更新依赖或者重新提交job的时候缓存的数据就丢失了,只有从数据库中重新加载这一个办法。
下面的图表是加载数据到6个Spark节点所需要花费的时间(以分钟计)。横坐标代表数据的行数,绿色是晚上六点数据库比较闲的时候,灰色是早晨十点数据库使用率比较高的时候而蓝色是下午两点数据库非常忙的时候。

我们可以看出加载数据的时间从几分钟到几小时不等。考虑到我们一天要重启很多次,光靠Spark的缓存肯定是不够的。我们想要达到的目标有下面三点:
• 缓存DataFrame原始数据用于寻找正确的映射配置
• 缓存RDD用于分析
• 快速读取中间结果并在不同应用之间共享数据
这三点汇成一句话其实就是要一个内存存储系统。
TachyonTachyon不单解决了我们数据存储的问题还将目前的部署速度提升到了一个新台阶。Tachyon作为一种内存分布式文件系统,可以存储任何文本格式或Parquet、Avro和Kryo等高效数据类型。我们还可以将结合进Snappy或LZO等压缩算法来减少对内存的占用。
与Spark应用的集成非常简单,只需调用DataFrame和RDD的加载存储API并指定路径URL和Tachyon协议即可。
我们存储原始数据的目的是快速地迭代探索式分析和测试。现在我们可以直接从原始数据来构建最简可行产品而不必在数据的处理上多花时间。下面是我们部署Tachyon之后的工作流程。
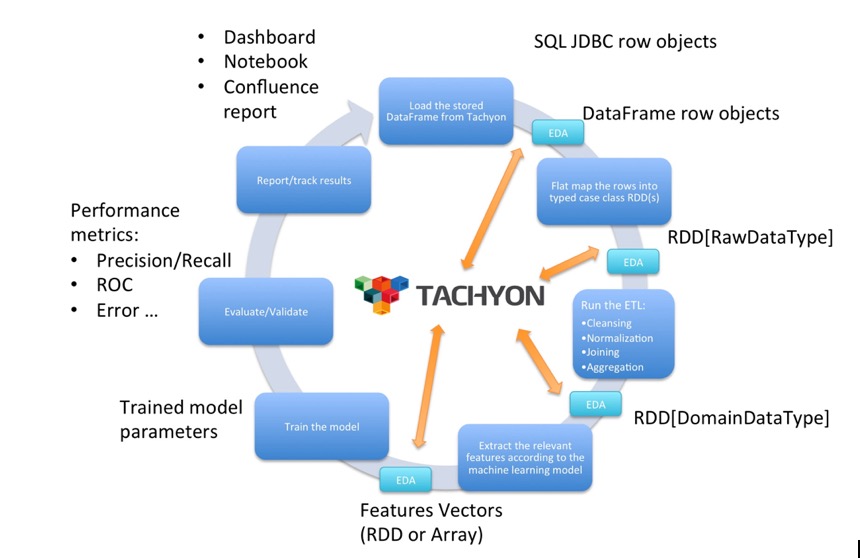
橙色箭头代表我们将数据的中间结果存储到Tachyon以方便以后读取。
Tachyon的配置在巴克莱我们将Tachyon配置为与tmpfs文件系统配合(unix系统中的路径为/dev/shm)。在Tachyon主节点上的配置由下面五步组成:
1.修改tachyon-env.sh配置文件
export TACHYON_WORKER_MEMORY_SIZE=${TACHYON_WORKER_MEMORY_SIZE:-24GB} TACHYON_JAVA_OPTS中我们则保留默认配置:
-Dtachyon.worker.tieredstore.level0. -Dtachyon.worker.tieredstore.level0.dirs.path=${TACHYON_RAM_FOLDER} -Dtachyon.worker.tieredstore.level0.dirs.quota=${TACHYON_WORKER_MEMORY_SIZE} 2.将配置复制到worker节点中
./bin/tachyon copyDir ./conf/
3.格式化Tachyon
./bin/tachyon format
4.部署Tachyon。注意NoMount选项,NoMount不需要root权限:
./bin/tachyon-start.sh all NoMount
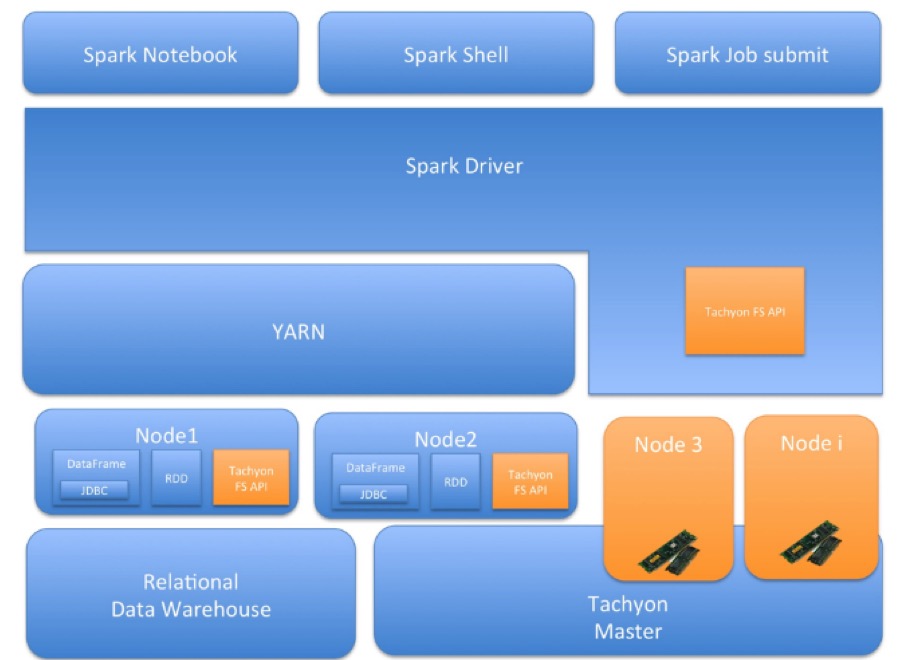
下面是我们整个架构的示意图:
Tachyon中数据的读写非常简单,因为它所提供的文件API与Java类似。往Tachyon中写DataFrame:
dataframe.write.save("tachyon://master_ip:port/mydata/mydataframe.parquet") 从Tachyon中读取DataFrame:
val dataframe: DataFrame = sqlContext.read.load("tachyon://master_ip:port/mydata/mydataframe.parquet") 写入RDD:
rdd.saveAsObjectFile("tachyon://master_ip:port/mydata/myrdd.object") 读取RDD:
val rdd: RDD[MyCaseClass] = sc.objectFile[MyCaseClass] ("tachyon://master_ip:port/mydata/myrdd.object") 这里要注意MyCaseClass的类型必须与写入时一致,不然会出错。
效果我们使用Spark、Scala、DataFrame、JDBC、Parquet、Kryo和Tachyon创建出了一套数据项目流程,它具有扩展性好和速度快等优点,质量也足以直接部署到生产环境中。
Tachyon使我们能够直接读取原始数据而不必从数据库中加载。数据写入Tachyon之后也可以迅速开始分析,提高了工作的效率。
使用Tachyon将数据存储在内存中读写只需几秒钟,所以在我们的流程中扩展几乎不影响性能。迭代一次所需的时间从以前的几个小时降低到了现在的几秒钟。
未来展望Tachyon自身还在发展,我们对Tachyon的使用也还在进一步的探索中,所以有一些限制是难免的。下面我们就列出了一些还有待提高的地方。
• 我们没有指定底层的存储设备所以Tachyon所能够存储的数据量受到所分配空间的限制。Tachyon提供了分层存储功能来解决这个问题。
• 设置JDBC驱动、分区策略和类映射还比较麻烦而且不够易用。
• Spark和Tachyon共享内存,所以为了避免重复和过度的垃圾回收还需要做一些调整。
• 如果Tachyon worker挂了,数据就会丢失。因为我们没有使用分层存储所以Tachyon自己不会重新加载数据。对巴克莱来说还好但对于其他企业来说可能还需要进一步的改进。
总的来说我们还是很看好Tachyon,它应该会对企业中的数据项目有所影响。
原文链接: Making the Impossible Possible with Tachyon: Accelerate Spark Jobs from Hours to Seconds
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

