阿里巴巴开源项目: 阿里巴巴去Oracle数据迁移同步工具
标签: 阿里巴巴 开源 项目 | 发表时间:2016-03-05 10:29 | 作者:
出处:http://agapple.iteye.com
背景
08年左右,阿里巴巴开始尝试MySQL的相关研究,并开发了基于MySQL分库分表技术的相关产品,Cobar/TDDL(目前为阿里云DRDS产品),解决了单机Oracle无法满足的扩展性问题,当时也掀起一股去IOE项目的浪潮,愚公这项目因此而诞生,其要解决的目标就是帮助用户完成从Oracle数据迁移到MySQL上,完成去IOE的第一步.
项目介绍
名称: yugong
译意: 愚公移山
语言: 纯java开发
定位: 数据库迁移 (目前主要支持oracle -> mysql/DRDS)
项目介绍
整个数据迁移过程,分为两部分:
- 全量迁移
- 增量迁移

过程描述:
- 增量数据收集 (创建oracle表的增量物化视图)
- 进行全量复制
- 进行增量复制 (可并行进行数据校验)
- 原库停写,切到新库
架构
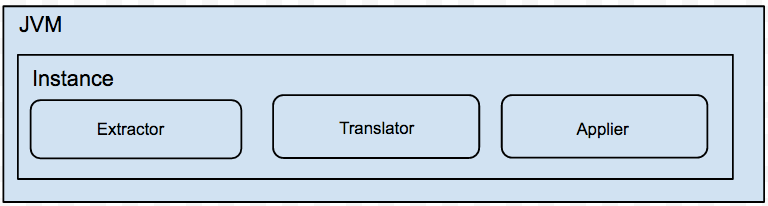
说明:
-
一个Jvm Container对应多个instance,每个instance对应于一张表的迁移任务
- instance分为三部分
a. extractor (从源数据库上提取数据,可分为全量/增量实现)
b. translator (将源库上的数据按照目标库的需求进行自定义转化)
c. applier (将数据更新到目标库,可分为全量/增量/对比的实现)
方案设计
全量方案
业界常用的全量方案有:
- 数据文件导入/导出,比如EXPDP/IMPDP, mysqldump/source, xtrabackup等
- ETL数据导入/导出,主要原理为使用JDBC数据查询接口
yugong在项目设计之初考虑去IOE数据迁移的灵活性和自定义能力,最终选择的方案为基于JDBC接口遍历数据.
相比于数据文件导入/导出,其优点:
- 灵活数据同步
- 支持异构数据
- 实现相对简单
缺点:
- 全量拉取需要配合增量使用,会有部分数据重复同步
- 性能和影响,一次性全量拉取,如果持续时间过长,如果此时数据库变更过多,会导致segment过大
增量方案
业界常用的增量方案有:
- 基于时间戳定时dump
- oracle日志文件,比如LogMiner,OGG
- oracle CDC(Change Data Capture)
- oracle trigger机制,比如DataBus , SymmetricDS
- oracle 物化视图(materialized view)
- ...
yugong在项目设计之初考虑去IOE数据迁移的灵活性,支持多种oracle版本,同时为降低DBA的运维成本,最终选择oracle物化视图作为我们的增量方案.
相比于其他,物化视图方案其优点:
- 原理简单,方便理解和学习,用户可以理解为一种固化的简易trigger模式
- 运维简单,DBA一次账户授权后,程序可按需create一张物化视图表即可完成增量订阅
- 相对透明,不需要像时间戳sql扫描依赖数据库表设计,也不需要关注oracle版本和服务器存储等
缺点:
- 性能和影响,类似于trigger机制会对源库的数据写入造成一定的性能影响.
QuickStart
See the page for quick start: QuickStart
AdminGuide
See the page for admin deploy guide: AdminGuide
Performance
See the page for yugong performance : Performance
相关资料
- yugong简单介绍ppt : ppt
- 分布式关系型数据库服务DRDS (前身为阿里巴巴公司的Cobar/TDDL的演进版本, 基本原理为MySQL分库分表)
问题反馈
- qq交流群: 537157866
- 邮件交流: jianghang115@gmail.com
- 新浪微博: agapple0002
- 报告issue: issues
ITeye推荐
- —软件人才免语言低担保 赴美带薪读研!—
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

