用机器学习检测Android恶意代码
0x00 前言
前段时间在乌云知识库上面看到一篇比较有意思的文章 利用机器学习进行恶意代码分类 。这篇文章对Kaggle上的一个恶意代码分类比赛中冠军队伍所采用的方法进行了介绍,展现了机器学习在安全领域的应用与潜力。但是这个比赛的主题是恶意代码的分类,没有进一步实现恶意代码的检测;其次比赛的代码只是针对Windows平台的PE格式,缺少对移动应用的研究。受此启发,尝试利用机器学习方法在Android平台对恶意代码进行检测,最终得到了一定的检测效果。
0x01 背景知识
安卓恶意代码检测方法
目前恶意软件检测方法主要有 基于特征代码(signature-based) 的检测方法和 基于行为(behavior-based) 的检测方法。基于特征代码的检测方法,通过检测文件是否拥有已知恶意软件的特征代码(如一段特殊代码或字符串)来判断其是否为恶意软件。它的优点是快速、准确率高、误报率低,但是无法检测未知的恶意代码。基于行为的检测方法,则依靠监视程序的行为与已知的恶意行为模式进行匹配,以此判断目标文件是否具备恶意特征。它的优点可以检测未知的恶意代码变种,缺点是误报率较高。
基于行为的分析方法又分为 动态分析 方法和 静态分析 方法。动态分析方法是指利用“沙盒或模拟器”来模拟运行程序,通过监控或者拦截的方式分析程序运行的行为,但是很消耗资源和时间。静态分析方法则是通过逆向手段抽取程序的特征,分析其中指令序列等。本文采用 静态分析 的方法进恶意行代码检测。
Weka与机器学习的分类算法
Weka(Waikato Environment for Knowledge Analysis),是一款免费的,非商业化基于JAVA环境下开源的机器学习(machine learning)以及数据挖掘(data minining)软件。Weka存储数据的格式是ARFF(Attribute-Relation File Format)文件,是一种ASCII文本文件。本文就是将特征数据生成ARFF格式的文件,利用Weka自带的分类算法进行数据训练与模型测试。
机器学习中分为有监督学习与无监督学习。有监督学习就是根据训练集,用学习算法学习出一个模型,然后可以用测试集对模型进行评估准确度和性能。分类算法属于有监督学习,需要先建立模型。常见的分类算法有: 随机森林(Random Forest) 、 支持向量机(SVM) 等。
APK的基本格式
Wikipedia上面有 APK(Android application package) 的介绍。
APK文件格式是一种基于ZIP的格式,它与JAR文件的构造方式相似。它的互联网媒体类型是application/vnd.android.package-archive;
一个APK文件通常包含以下文件:
- classes.dex: Dalvik字节码,可被Dalvik虚拟机执行。
- AndroidManifest.xml: 一个的Android清单文件,用于描述该应用程序的名字、版本号、所需权限、注册的服务、链接的其他应用程序。该文件使用XML文件格式。
- META-INF 文件夹: 下面有3个文件
- MANIFEST.MF: 清单信息
- CERT.RSA: 保存应用程序的证书和授权信息
- CERT.SF: 保存SHA-1信息资源列表
- res: APK所需要的资源文件夹
- assets: 不需编译的原始资源文件目录
- resources.arsc:编译后的二进制资源文件
- lib:库文件目录
所有的文件中需要重点注意的是 classes.dex ,安卓的执行代码被编译后封装在这个文件中。
Dalvik虚拟机与反汇编
区别与JAVA虚拟机(JVM),安卓的虚拟机称为Dalvik虚拟机(DVM)。Java虚拟机运行的是Java字节码,Dalvik虚拟机运行的是Dalvik字节码。Java虚拟机基于栈架构,Dalvik虚拟机基于寄存器架构。
DVM拥有专属的DEX可执行文件格式和指令集代码。 smali 和 baksmali 则是针对DEX执行文件格式的汇编器和反汇编器,反汇编后DEX 文件会产生.smali 后缀的代码文件,smali代码拥有特定的格式与语法,smali语言是对Dalvik 虚拟机字节码的一种解释。
apktool 工具是在smali工具的基础上进行封装和改进的,除了对DEX文件的汇编和反汇编功能外,还可以对APK 中已编译成二进制的资源文件进行反编译和重新编译。本文直接使用apktool工具来反汇编APK文件,而不是使用smali和baksmali工具。
#!bash java -jar apktool.jar d D:/drebin/The_Drebin_Dataset/set/apk/DroidKungFu/xyz.apk 命令执行成功会在out 目录下产生如下所示的一级目录结构:
- AndroidManifest.xml 配置文件
- apktool.yml 反编译生成的文件,供apktool使用
- assets/ 不需反编译的资源文件目录
- lib/ 不需反编译的库文件目录
- res/ 反编译后的资源文件目录
- smali/ 反编译生成的smali 源码文件目录
其中,smali目录结构对应着原始的java源码src目录。
0x02 特征工程
Dalvik指令的分类与描述
Smali是对DVM字节码的一种解释,虽然不是官方标准语言,但所有语句都遵循一套语法规范。Dalvik opcodes的详细说明可以参考这篇文章 http://pallergabor.uw.hu/androidblog/dalvik_opcodes.html ,里面详细列举了Dalvik Opcode 的含义及用法、例子。
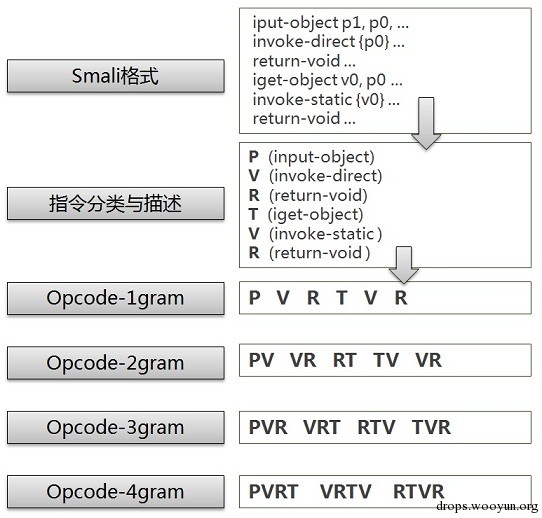
由于Dalvik指令有两百多条,对此需要进行了分类与精简,去掉了无关的指令,只留下了M、R、G、I、T、P、V七大类核心的指令集合,并且只保留操作码字段,去掉了参数。M、R、G、I、T、P、V七大类指令集合分别代表了移动、返回、跳转、判断、取数据、存数据、调用方法七种类型的指令,对指令进行了一次分类与描述。具体见下图:

OpCode N-gram
n-gram是自然语言处理领域的概念,但是它也经常用来处理恶意代码的分析。OpCode N-gram就是对指令操作码字段提取N-gram特征,n可以取值为2,3,4等。对一个smali格式的汇编文件的OpCode N-gram如下图所示:
0x03 系统设计与实现
整个系统分两大部分:建立恶意代码检测模型、测试恶意代码检测模型。
建立恶意代码检测模型如下所示:
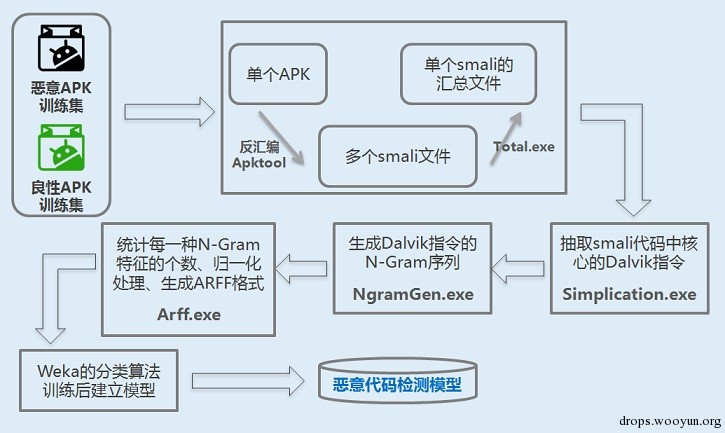
用C++写了几个程序,对模型建立过程中的数据进行处理:
- Total.exe:用于将单个apk反汇编后生成的工程目录中所有的smali文件进行汇总到一个文件
- Simplication.exe:用于提取指令,并进行分类与描述
- NgramGen.exe:用于生成指定N的N-gram序列
- Arff.exe 统计每种特征的个数、生成适用于Weka的ARFF格式文件
测试恶意代码检测模型如下所示:
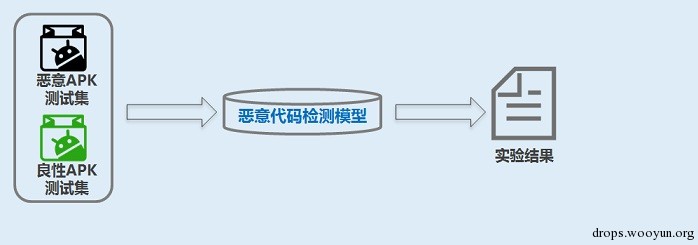
用机器学习工具Weka进行模型测试,检测模型的准确度。得到准确度高的模型可以用来预测未知Android代码是否为恶意代码。
0x04 实验评估
实验数据来源
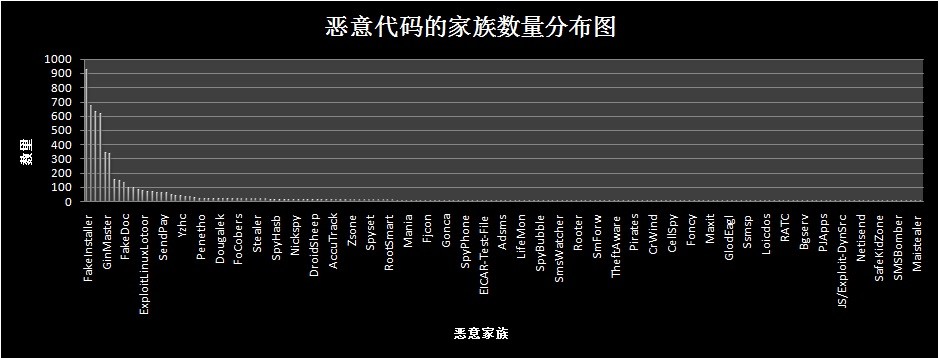
实验数据分为恶意代码样本与正常代码样本。正常代码样本从安卓市场下载;恶意代码样本数据来源于 Drebin项目 ,该病毒库收集了2010年8月至2012年10月178种共5560份APK样本文件。178种恶意代码家族的数据量分布如下图所示:
实验结果
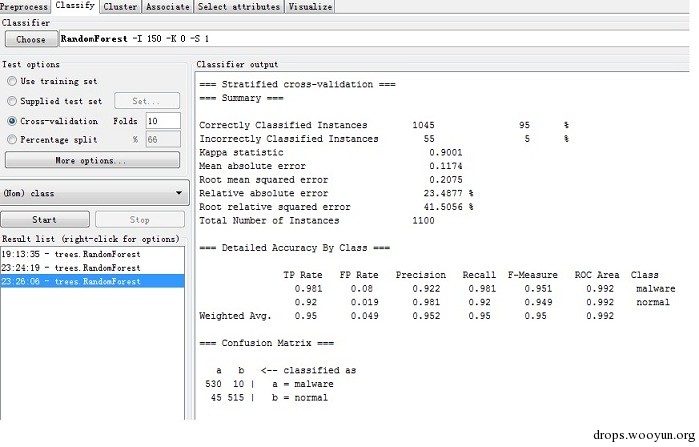
本文采用540个恶意样本与560个良性样本,2个分类,一共合计1100个样本。分类算法采用随机森林,150棵决策树,n取3,进行十折交叉验证。
准确率如下图所示,1045个样本得到正确分类,5个样本分类失败。对于malware,其中TPR(真阳性率)=0.981,FPR(假阳性率)=0.08,Precision(查准率) =0.922
ROC曲线效果如下,AUC=0.9923
ROC(Receiver Operating Characteristic)曲线和AUC常被用来评价一个二值分类器(binary classifier)的优劣,具体关于AUC相关知识请参见 https://en.wikipedia.org/wiki/Area_under_the_curve_(pharmacokinetics)

0x05 总结与展望
- 总的来说,实验结果表明对恶意代码检测有较高的准确率
- 如果可以再结合其他的特征,应该还可以进一步提高准确率
- 除了使用随机森林算法,也可以尝试其他的分类算法的效果,比如支持向量机等
0x06 参考资料
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

